最近在学习Vulkan,结果在查看示例代码的时候,对于如下两句出现了疑问:
layout(local_size_x = X, local_size_y = Y, local_size_z = Z) in;
ivec3 pos = ivec3(gl_GlobalInvocationID);
首先是Invocation这个单词的理解,计算机语言中他的意思是 "the act of making a particular function start" ,中文意思是 "调用,启用"。
其中
layout(local_size_x = X, local_size_y = Y, local_size_z = Z) in;
意思是初始化,X * Y * Z 个计算单元供我们的代码调用,可以简单理解成线程数。如果不设置这几个值,默认值是 1,也就是只提供一个计算单元(线程)。
而使用如下的代码
ivec3 pos = ivec3(gl_GlobalInvocationID);
意思是获取当前代码运行的计算单元的编号,也可以理解成获取当前线程的索引。
下面的代码都使用如下的命令编译成Vulkan使用的SPIR-V格式的代码
$ glslangValidator xx.comp --target-env vulkan1.0
比如下面的代码,就是一个简单的利用gl_GlobalInvocationID,进行并行计算的例子:
#version 430 core
layout (local_size_x = 64) in;
layout(std430, binding=4 ) buffer INFO
{
vec2 info[];
};
void main()
{
uint gid = gl_GlobalInvocationID.x;
info[gid].x += 1.0;
info[gid].y += 1.0;
memoryBarrier();
}
但是,如果传入的数组的大小超过我们设置的计算单元的数量的情况,上述的代码是处理不了的。
可以如下方式处理上述情况:
/*atomicAdd 从4.30版本的opengl开始提供,之前的版本没有这个函数*/
#version 430 core
layout (local_size_x = 64) in;
layout(std430, binding=4 ) buffer INFO
{
vec2 info[];
};
layout(std430, binding=5 ) buffer LEN
{
uint len;
};
uint counter = 0;
void main()
{
uint gid = atomicAdd(counter,1);
if (gid <= len ) {
info[gid].x += 1.0;
info[gid].y += 1.0;
memoryBarrier();
}
}
void main()
{
uint gid = atomicAdd(counter,1);
if (gid <= len ) {
info[gid].x += 1.0;
info[gid].y += 1.0;
memoryBarrier();
}
}
如果想动态调整计算单元的数量,增加处理灵活性,可以参考下面的代码:
#version 450 layout(local_size_x_id = 0) in; layout(local_size_y_id = 1) in; layout(local_size_z_id = 2) in; //rest of the shader
外部通过
VkResult vkCreateComputePipelines( VkDevice device, VkPipelineCache pipelineCache, uint32_t createInfoCount, const VkComputePipelineCreateInfo* pCreateInfos, const VkAllocationCallbacks* pAllocator, VkPipeline* pPipelines);
函数调用的时候,指定
typedef struct VkComputePipelineCreateInfo {
VkStructureType sType;
const void* pNext;
VkPipelineCreateFlags flags;
VkPipelineShaderStageCreateInfo stage;
VkPipelineLayout layout;
VkPipeline basePipelineHandle;
int32_t basePipelineIndex;
} VkComputePipelineCreateInfo;
参数中的
typedef struct VkPipelineShaderStageCreateInfo {
VkStructureType sType;
const void* pNext;
VkPipelineShaderStageCreateFlags flags;
VkShaderStageFlagBits stage;
VkShaderModule module;
const char* pName;
const VkSpecializationInfo* pSpecializationInfo;
} VkPipelineShaderStageCreateInfo;
参数中的
typedef struct VkSpecializationInfo {
uint32_t mapEntryCount;
const VkSpecializationMapEntry* pMapEntries;
size_t dataSize;
const void* pData;
} VkSpecializationInfo;
参数中的
typedef struct VkSpecializationMapEntry {
uint32_t constantID;
uint32_t offset;
size_t size;
} VkSpecializationMapEntry;
指定的数值来动态调整所需要的计算单元的数量。
整个参数的设置流程特别长,非常难掌握。具体的使用例子参考 Glavnokoman/vuh以及 Vulkan® 1.0.95 - A Specification - Khronos Group文档中的上述参数的使用例子。
如果内部不指定,也可以通过外部调用
void vkCmdDispatch( VkCommandBuffer commandBuffer, uint32_t groupCountX, uint32_t groupCountY, uint32_t groupCountZ);
的时候设置,但是这样的设置存在一定的灵活性问题,可能需要多个独立的ComputePipeline来配合。
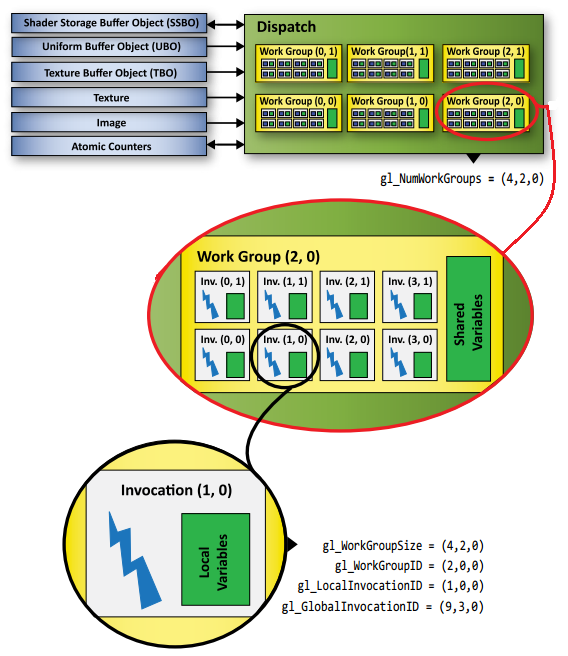
具体信息,可以参考下图:
相关介绍,请参考 Compute Shader。网页如果打不开,可以点击下图,查看详细内容:
参考链接
- opengl渲染管线 不能再详细了
- / jessie / opengl-4-man-doc / gl_GlobalInvocationID(3G)
- 基于OpenGL ES的深度学习框架编写
- How are tasks divided up with compute shaders?
- Vulkan® 1.1.95 - A Specification (with all registered Vulkan extensions)
- Compute Shader
- User defined WorkGroup sizes in Vulkan Compute shaders
- Vulkan atomic counters
- Atomic Counter
- atomicAdd — perform an atomic addition to a variable
- WorkGroupSize specialization does not work when gl_WorkGroupSize is not referenced in the shader.
- Has anybody got a working example of work group size variation through use of specialization constants?
- Push Constants Guaranteed Minimum Size (Vulkan Spec)?
那个图片上的 WorkGroup ID 和 LocalInvocationID 都写错了吧,跟图片不一致,应该是(2,1,0)和(1,1,0)
图片是网上找到的,跟代码确实对应不起来,两者没有太大关系,就是一个参考。