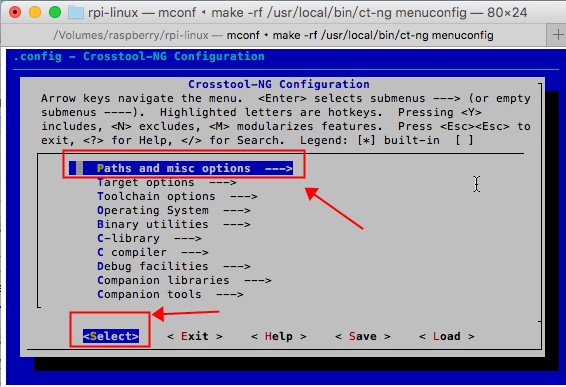
调用glclear接口,发现它耗时比较长,翻了翻stackoverflow。
Measuring the elapsed time of an OpenGL API call is mostly meaningless.
研究OpenGL接口的耗时是无意义的。
Asynchronicity
The key aspect to understand is that OpenGL is an API to pass work to a GPU.
The easiest mental model (which largely corresponds to reality) is that when you make OpenGL API calls, you queue up work that will later be submitted to the GPU. For example, if you make a glDraw*() call, picture the call building a work item that gets queued up, and at some point later will be submitted to the GPU for execution.
In other words, the API is highly asynchronous. The work you request by making API calls is not completed by the time the call returns. In most cases, it's not even submitted to the GPU for execution yet. It is only queued up, and will be submitted at some point later, mostly outside your control.
A consequence of this general approach is that the time you measure to make a glClear() call has pretty much nothing to do with how long it takes to clear the framebuffer.
Synchronization
Now that we established how the OpenGL API is asynchronous, the next concept to understand is that a certain level of synchronization is necessary.
Let's look at a workload where the overall throughput is limited by the GPU (either by GPU performance, or because the frame rate is capped by the display refresh). If we kept the whole system entirely asynchronous, and the CPU can produce GPU commands faster than the GPU can process them, we would be queuing up a gradually increasing amount of work. This is undesirable for a couple of reasons:
- In the extreme case, the amount of queued up work would grow towards infinity, and we would run out of memory just from storing the queued up GPU commands.
- In apps that need to respond to user input, like games, we would get increasing latency between user input and rendering.
To avoid this, drivers use throttling mechanisms to prevent the CPU from getting too far ahead. The details of how exactly this is handled can be fairly complex. But as a simple model, it might be something like blocking the CPU when it gets more than 1-2 frames ahead of what the GPU has finished rendering. Ideally, you always want some work queued up so that the GPU never goes idle for graphics limited apps, but you want to keep the amount of queued up work as small as possible to minimize memory usage and latency.
Meaning of Your Measurement
With all this background information explained, your measurements should be much less surprising. By far the most likely scenario is that your glClear() call triggers a synchronization, and the time you measure is the time it takes the GPU to catch up sufficiently, until it makes sense to submit more work.
Note that this does not mean that all the previously submitted work needs to complete. Let's look at a sequence that is somewhat hypothetical, but realistic enough to illustrate what can happen:
- Let's say you make the
glClear() call that forms the start of rendering frame n.
- At this time, frame
n - 3 is on the display, and the GPU is busy processing rendering commands for frame n - 2.
- The driver decides that you really should not be getting more than 2 frames ahead. Therefore, it blocks in your
glClear() call until the GPU finished the rendering commands for frame n - 2.
- It might also decide that it needs to wait until frame
n - 2 is shown on the display, which means waiting for the next beam sync.
- Now that frame
n - 2 is on the display, the buffer that previously contained frame n - 3 is not used anymore. It is now ready to be used for frame n, which means that the glClear()command for frame n can now be submitted.
Note that while your glClear() call did all kinds of waiting in this scenario, which you measure as part of the elapsed time spent in the API call, none of this time was used for actually clearing the framebuffer for your frame. You were probably just sitting on some kind of semaphore (or similar synchronization mechanism), waiting for the GPU to complete previously submitted work.
Conclusion
Considering that your measurement is not directly helpful after all, what can you learn from it? Unfortunately not a whole lot.
If you do observe that your frame rate does not meet your target, e.g. because you observe stuttering, or even better because you measure the framerate over a certain time period, the only thing you know for sure is that your rendering is too slow. Going into the details of performance analysis is a topic that is much too big for this format. Just to give you a rough overview of steps you could take:
- Measure/profile your CPU usage to verify that you are really GPU limited.
- Use GPU profiling tools that are often available from GPU vendors.
- Simplify your rendering, or skip parts of it, and see how the performance changes. For example, does it get faster if you simplify the geometry? You might be limited by vertex processing. Does it get faster if you reduce the framebuffer size? Or if you simplify your fragment shaders? You're probably limited by fragment processing.
OpenGL是GPU的API
API call是以eventloop的形式工作
但需要一定的同步工作,任务数量太多,延迟会变大,开发者又需要尽快响应用户,GPU需要跟CPU保持一定过得同步。简单的来说,如果CPU发出的绘制指令超出GPU太多(1-2帧),GPU会锁住CPU。
在这个背景下,就可以解释为什么glClear耗时了,因为它触发了一次同步。
已3个缓冲区为例,n-3在绘制,n-2在合成,The driver decides that you really should not be getting more than 2 frames ahead。glClear就会block住,直到GPU工作完。
GPU工作渲染完n-2,glClear就会提交n。
最终结论,绘制太慢导致的。
可以看看CPU消耗,看看是不是CPU被锁住了。