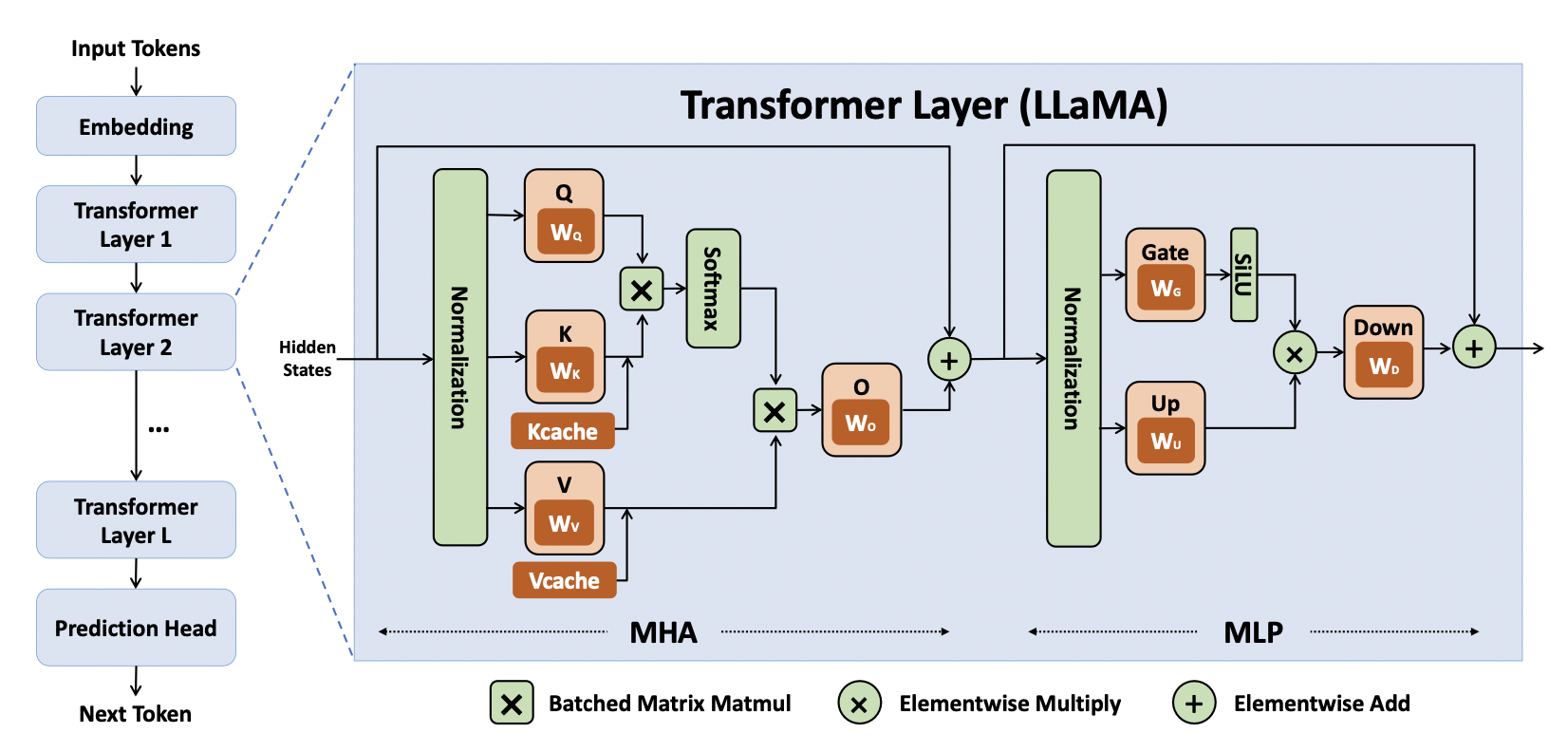
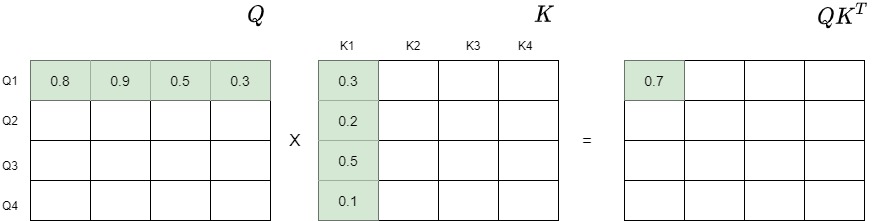
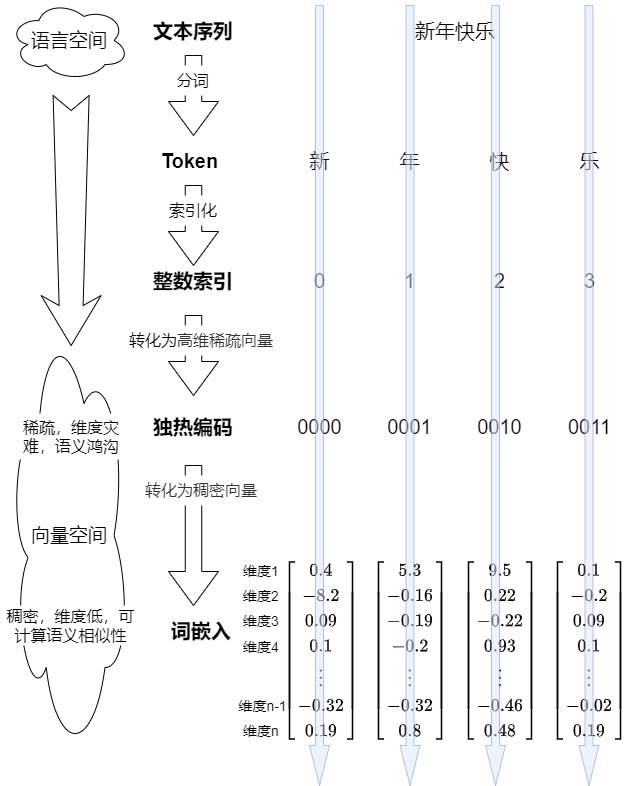
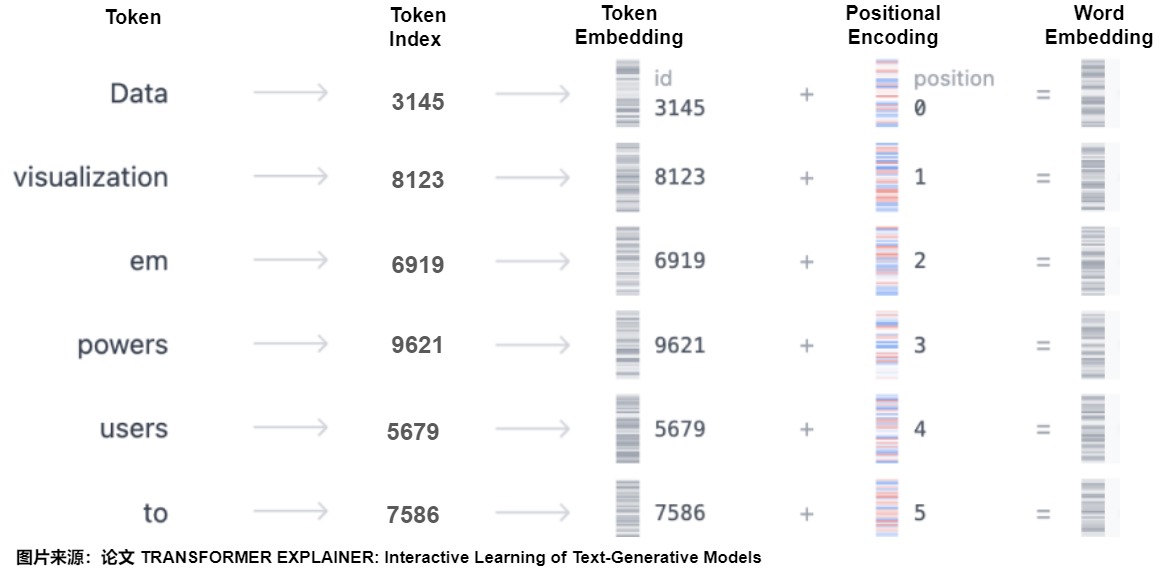
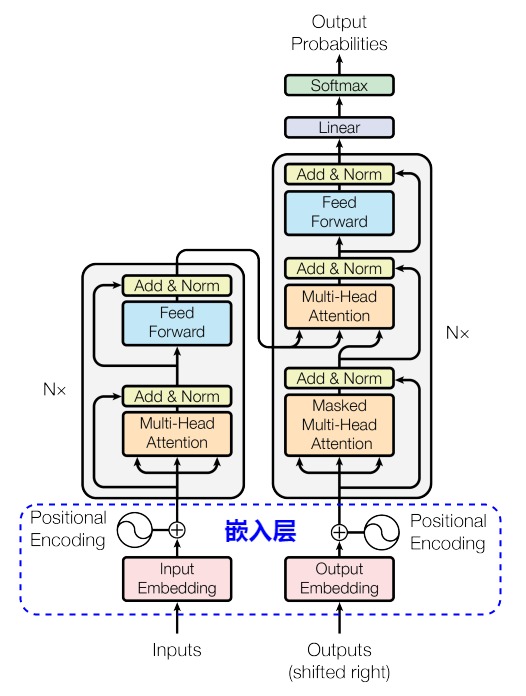
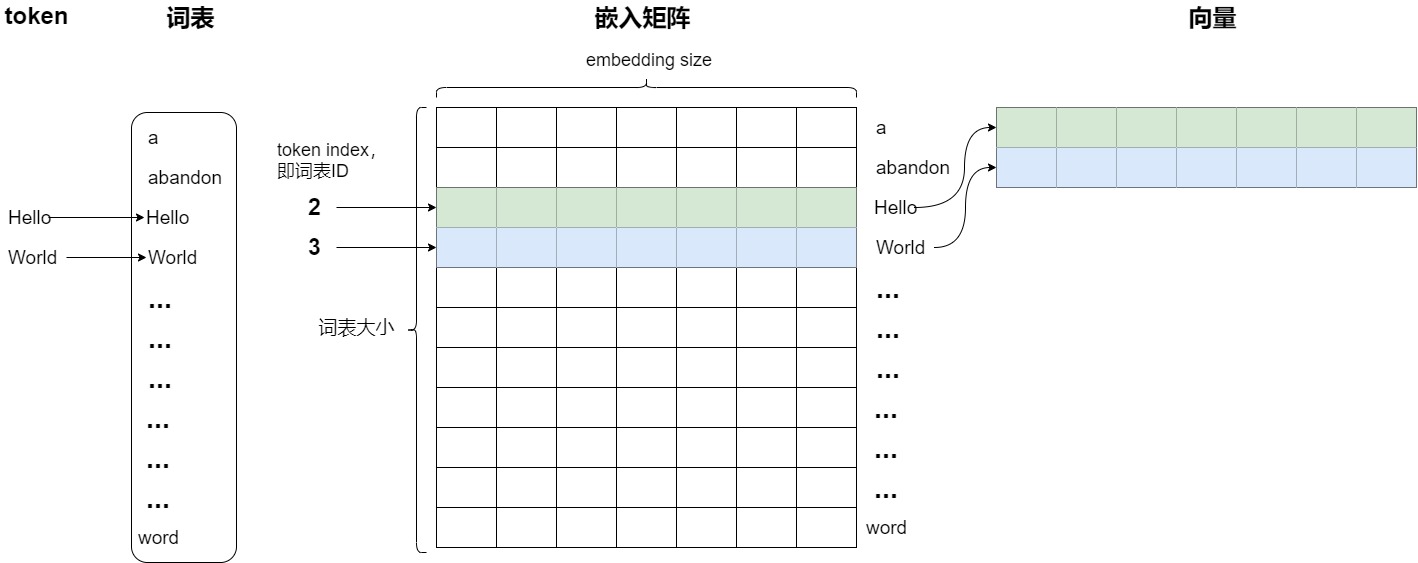
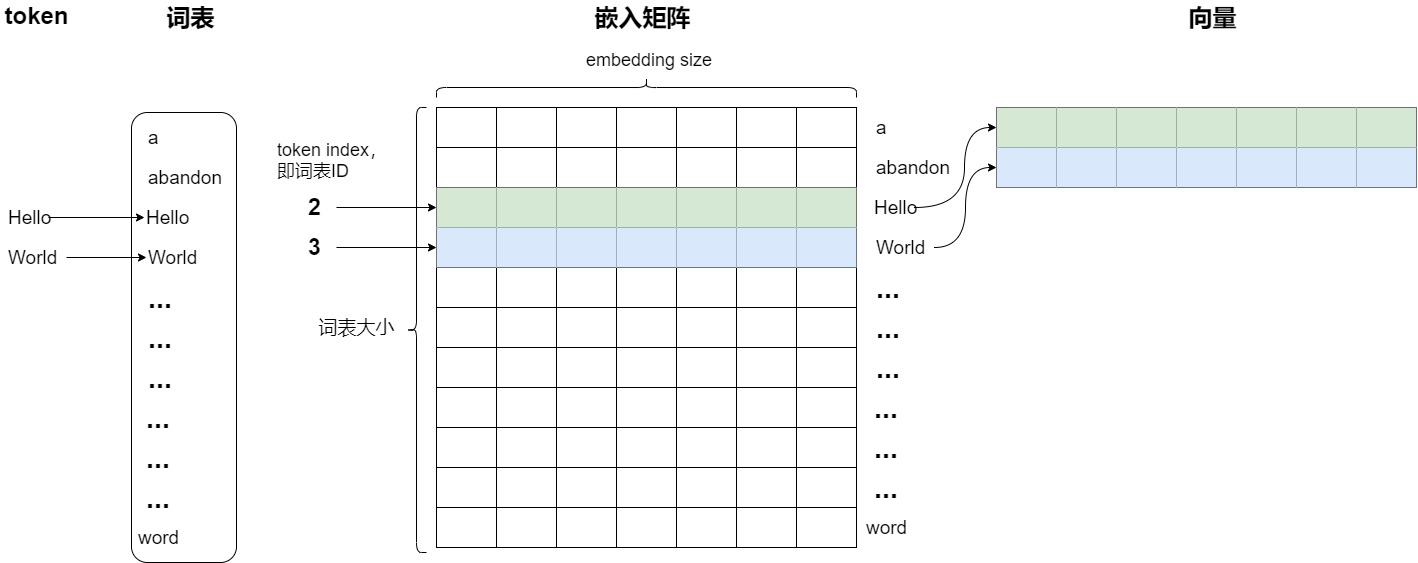
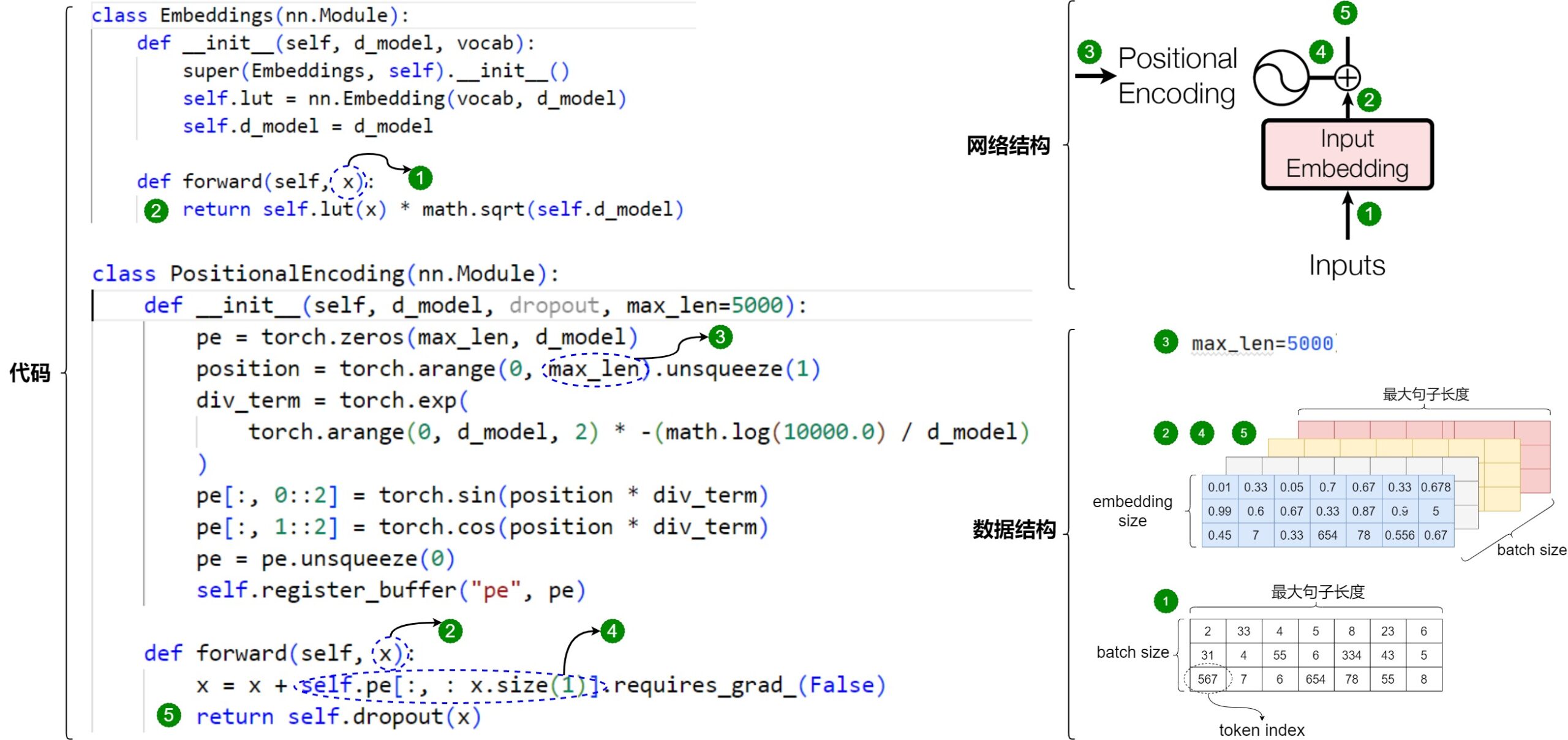
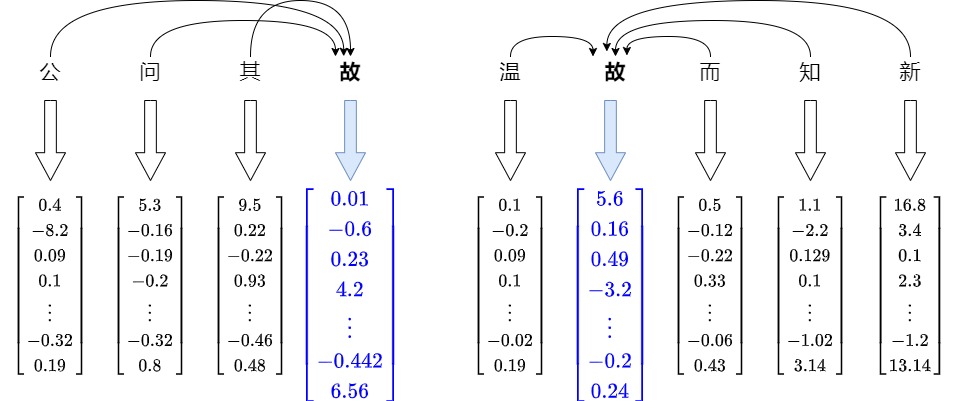
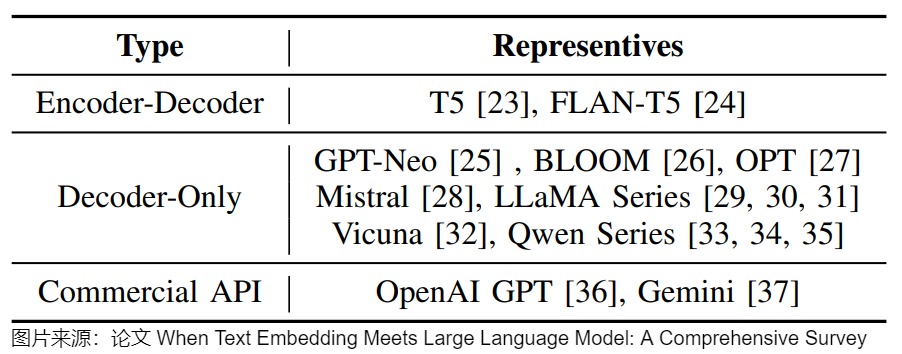
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [32,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [33,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [34,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [35,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [36,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [37,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [38,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [39,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [40,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [41,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [42,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [43,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [44,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [45,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [46,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [47,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [48,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [49,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [50,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [51,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [52,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [53,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [54,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [55,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [56,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [57,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [58,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [59,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [60,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [61,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [62,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [63,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [64,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [65,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [66,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [67,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [68,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [69,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [70,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [71,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [72,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [73,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [74,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [75,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [76,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [77,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [78,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [79,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [80,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [81,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [82,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [83,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [84,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [85,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [86,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [87,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [88,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [89,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [90,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [91,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [92,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [93,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [94,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [95,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [64,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [65,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [66,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [67,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [68,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [69,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [70,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [71,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [72,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [73,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [74,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [75,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [76,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [77,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [78,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [79,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [80,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [81,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [82,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [83,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [84,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [85,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [86,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [87,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [88,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [89,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [90,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [91,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [92,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [93,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [94,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [95,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [96,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [97,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [98,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [99,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [100,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [101,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [102,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [103,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [104,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [105,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [106,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [107,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [108,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [109,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [110,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [111,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [112,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [113,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [114,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [115,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [116,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [117,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [118,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [119,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [120,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [121,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [122,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [123,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [124,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [125,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [126,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [127,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [64,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [65,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [66,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [67,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [68,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [69,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [70,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [71,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [72,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [73,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [74,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [75,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [76,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [77,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [78,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [79,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [80,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [81,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [82,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [83,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [84,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [85,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [86,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [87,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [88,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [89,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [90,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [91,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [92,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [93,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [94,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [95,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [96,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [97,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [98,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [99,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [100,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [101,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [102,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [103,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [104,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [105,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [106,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [107,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [108,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [109,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [110,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [111,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [112,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [113,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [114,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [115,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [116,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [117,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [118,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [119,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [120,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [121,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [122,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [123,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [124,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [125,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [126,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [127,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [32,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [33,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [34,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [35,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [36,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [37,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [38,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [39,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [40,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [41,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [42,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [43,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [44,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [45,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [46,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [47,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [48,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [49,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [50,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [51,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [52,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [53,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [54,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [55,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [56,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [57,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [58,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [59,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [60,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [61,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [62,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [63,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [0,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [1,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [2,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [3,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [4,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [5,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [6,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [7,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [8,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [9,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [10,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [11,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [12,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [13,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [14,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [15,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [16,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [17,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [18,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [19,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [20,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [21,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [22,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [23,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [24,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [25,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [26,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [27,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [28,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [29,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [30,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [31,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [96,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [97,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [98,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [99,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [100,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [101,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [102,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [103,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [104,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [105,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [106,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [107,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [108,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [109,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [110,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [111,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [112,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [113,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [114,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [115,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [116,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [117,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [118,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [119,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [120,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [121,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [122,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [123,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [124,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [125,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [126,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [127,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [0,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [1,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [2,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [3,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [4,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [5,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [6,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [7,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [8,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [9,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [10,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [11,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [12,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [13,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [14,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [15,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [16,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [17,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [18,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [19,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [20,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [21,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [22,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [23,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [24,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [25,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [26,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [27,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [28,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [29,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [30,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [2,0,0], thread: [31,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [64,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [65,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [66,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [67,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [68,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [69,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [70,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [71,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [72,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [73,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [74,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [75,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [76,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [77,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [78,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [79,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [80,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [81,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [82,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [83,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [84,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [85,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [86,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [87,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [88,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [89,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [90,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [91,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [92,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [93,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [94,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [95,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [32,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [33,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [34,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [35,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [36,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [37,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [38,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [39,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [40,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [41,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [42,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [43,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [44,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [45,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [46,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [47,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [48,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [49,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [50,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [51,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [52,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [53,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [54,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [55,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [56,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [57,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [58,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [59,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [60,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [61,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [62,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [0,0,0], thread: [63,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [32,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [33,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [34,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [35,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [36,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [37,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [38,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [39,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [40,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [41,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [42,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [43,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [44,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [45,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [46,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [47,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [48,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [49,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [50,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [51,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [52,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [53,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [54,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [55,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [56,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [57,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [58,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [59,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [60,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [61,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [62,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [63,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [96,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [97,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [98,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [99,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [100,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [101,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [102,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [103,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [104,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [105,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [106,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [107,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [108,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [109,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [110,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [111,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [112,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [113,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [114,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [115,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [116,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [117,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [118,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [119,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [120,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [121,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [122,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [123,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [124,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [125,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [126,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [127,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [0,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [1,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [2,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [3,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [4,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [5,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [6,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [7,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [8,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [9,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [10,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [11,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [12,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [13,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [14,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [15,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [16,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [17,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [18,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [19,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [20,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [21,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [22,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [23,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [24,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [25,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [26,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [27,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [28,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [29,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [30,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [3,0,0], thread: [31,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [0,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [1,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [2,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [3,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [4,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [5,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [6,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [7,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [8,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [9,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [10,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [11,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [12,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [13,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [14,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [15,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [16,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [17,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [18,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [19,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [20,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [21,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [22,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [23,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [24,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [25,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [26,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [27,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [28,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [29,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [30,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
~/pytorch/aten/src/ATen/native/cuda/IndexKernel.cu:53: lambda [](int)->auto::operator()(int)->auto: block: [1,0,0], thread: [31,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
Traceback (most recent call last):
File "tools/train_net.py", line 173, in <module>
main()
File "tools/train_net.py", line 166, in main
model = train(cfg, args.local_rank, args.distributed)
File "tools/train_net.py", line 76, in train
cfg,
File "~/MaskTextSpotter/maskrcnn_benchmark/engine/trainer.py", line 66, in do_train
loss_dict = model(images, targets)
File "~/.conda/envs/MaskTextSpotter/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "~/MaskTextSpotter/maskrcnn_benchmark/modeling/detector/generalized_rcnn.py", line 50, in forward
proposals, proposal_losses = self.rpn(images, features, targets)
File "~/.conda/envs/MaskTextSpotter/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "~/MaskTextSpotter/maskrcnn_benchmark/modeling/rpn/rpn.py", line 94, in forward
return self._forward_train(anchors, objectness, rpn_box_regression, targets)
File "~/MaskTextSpotter/maskrcnn_benchmark/modeling/rpn/rpn.py", line 110, in _forward_train
anchors, objectness, rpn_box_regression, targets
File "~/.conda/envs/MaskTextSpotter/lib/python3.6/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "~/MaskTextSpotter/maskrcnn_benchmark/modeling/rpn/inference.py", line 138, in forward
sampled_boxes.append(self.forward_for_single_feature_map(a, o, b))
File "~/MaskTextSpotter/maskrcnn_benchmark/modeling/rpn/inference.py", line 113, in forward_for_single_feature_map
boxlist = remove_small_boxes(boxlist, self.min_size)
File "~/MaskTextSpotter/maskrcnn_benchmark/structures/boxlist_ops.py", line 46, in remove_small_boxes
(ws >= min_size) & (hs >= min_size)
RuntimeError: copy_if failed to synchronize: cudaErrorAssert: device-side assert triggered