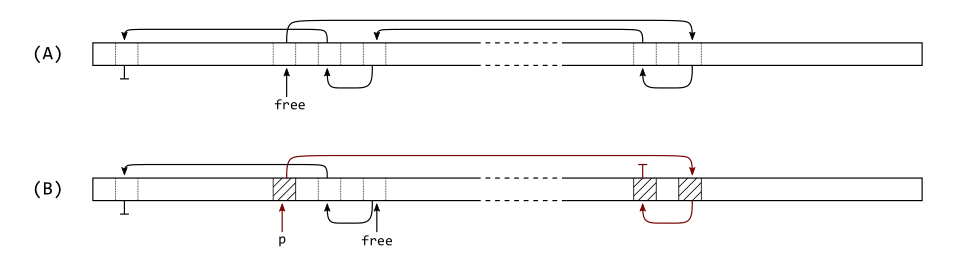
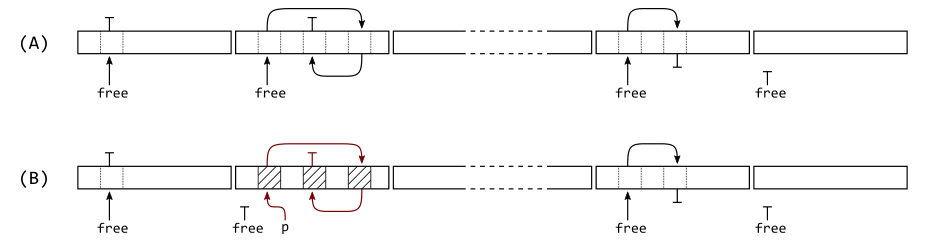
#!/usr/bin/env python
import clang.cindex
import sys
import os
import logging
import argparse
import fnmatch
from DotGenerator import *
index = clang.cindex.Index.create()
dotGenerator = DotGenerator()
def findFilesInDir(rootDir, patterns):
""" Searches for files in rootDir which file names mathes the given pattern. Returns
a list of file paths of found files"""
foundFiles = []
for root, dirs, files in os.walk(rootDir):
for p in patterns:
for filename in fnmatch.filter(files, p):
foundFiles.append(os.path.join(root, filename))
return foundFiles
def processClassField(cursor):
""" Returns the name and the type of the given class field.
The cursor must be of kind CursorKind.FIELD_DECL"""
type = None
fieldChilds = list(cursor.get_children())
if len(fieldChilds) == 0: # if there are not cursorchildren, the type is some primitive datatype
type = cursor.type.spelling
else: # if there are cursorchildren, the type is some non-primitive datatype (a class or class template)
for cc in fieldChilds:
if cc.kind == clang.cindex.CursorKind.TEMPLATE_REF:
type = cc.spelling
elif cc.kind == clang.cindex.CursorKind.TYPE_REF:
type = cursor.type.spelling
name = cursor.spelling
return name, type
def processClassMemberDeclaration(umlClass, cursor):
""" Processes a cursor corresponding to a class member declaration and
appends the extracted information to the given umlClass """
if cursor.kind == clang.cindex.CursorKind.CXX_BASE_SPECIFIER:
for baseClass in cursor.get_children():
if baseClass.kind == clang.cindex.CursorKind.TEMPLATE_REF:
umlClass.parents.append(baseClass.spelling)
elif baseClass.kind == clang.cindex.CursorKind.TYPE_REF:
umlClass.parents.append(baseClass.type.spelling)
elif cursor.kind == clang.cindex.CursorKind.FIELD_DECL: # non static data member
name, type = processClassField(cursor)
if name is not None and type is not None:
# clang < 3.5: needs patched cindex.py to have
# clang.cindex.AccessSpecifier available:
# https://gitorious.org/clang-mirror/clang-mirror/commit/e3d4e7c9a45ed9ad4645e4dc9f4d3b4109389cb7
if cursor.access_specifier == clang.cindex.AccessSpecifier.PUBLIC:
umlClass.publicFields.append((name, type))
elif cursor.access_specifier == clang.cindex.AccessSpecifier.PRIVATE:
umlClass.privateFields.append((name, type))
elif cursor.access_specifier == clang.cindex.AccessSpecifier.PROTECTED:
umlClass.protectedFields.append((name, type))
elif cursor.kind == clang.cindex.CursorKind.CXX_METHOD:
try:
returnType, argumentTypes = cursor.type.spelling.split(' ', 1)
if cursor.access_specifier == clang.cindex.AccessSpecifier.PUBLIC:
umlClass.publicMethods.append((returnType, cursor.spelling, argumentTypes))
elif cursor.access_specifier == clang.cindex.AccessSpecifier.PRIVATE:
umlClass.privateMethods.append((returnType, cursor.spelling, argumentTypes))
elif cursor.access_specifier == clang.cindex.AccessSpecifier.PROTECTED:
umlClass.protectedMethods.append((returnType, cursor.spelling, argumentTypes))
except:
logging.error("Invalid CXX_METHOD declaration! " + str(cursor.type.spelling))
elif cursor.kind == clang.cindex.CursorKind.FUNCTION_TEMPLATE:
returnType, argumentTypes = cursor.type.spelling.split(' ', 1)
if cursor.access_specifier == clang.cindex.AccessSpecifier.PUBLIC:
umlClass.publicMethods.append((returnType, cursor.spelling, argumentTypes))
elif cursor.access_specifier == clang.cindex.AccessSpecifier.PRIVATE:
umlClass.privateMethods.append((returnType, cursor.spelling, argumentTypes))
elif cursor.access_specifier == clang.cindex.AccessSpecifier.PROTECTED:
umlClass.protectedMethods.append((returnType, cursor.spelling, argumentTypes))
def processClass(cursor, inclusionConfig):
""" Processes an ast node that is a class. """
umlClass = UmlClass() # umlClass is the datastructure for the DotGenerator
# that stores the necessary information about a single class.
# We extract this information from the clang ast hereafter ...
if cursor.kind == clang.cindex.CursorKind.CLASS_TEMPLATE:
# process declarations like:
# template <typename T> class MyClass
umlClass.fqn = cursor.spelling
else:
# process declarations like:
# class MyClass ...
# struct MyStruct ...
umlClass.fqn = cursor.type.spelling # the fully qualified name
import re
if (inclusionConfig['excludeClasses'] and
re.match(inclusionConfig['excludeClasses'], umlClass.fqn)):
return
if (inclusionConfig['includeClasses'] and not
re.match(inclusionConfig['includeClasses'], umlClass.fqn)):
return
for c in cursor.get_children():
# process member variables and methods declarations
processClassMemberDeclaration(umlClass, c)
dotGenerator.addClass(umlClass)
def traverseAst(cursor, inclusionConfig):
if (cursor.kind == clang.cindex.CursorKind.CLASS_DECL
or cursor.kind == clang.cindex.CursorKind.STRUCT_DECL
or cursor.kind == clang.cindex.CursorKind.CLASS_TEMPLATE):
# if the current cursor is a class, class template or struct declaration,
# we process it further ...
processClass(cursor, inclusionConfig)
for child_node in cursor.get_children():
traverseAst(child_node, inclusionConfig)
def parseTranslationUnit(filePath, includeDirs, inclusionConfig):
clangArgs = ['-x', 'c++'] + ['-I' + includeDir for includeDir in includeDirs]
tu = index.parse(filePath, args=clangArgs, options=clang.cindex.TranslationUnit.PARSE_SKIP_FUNCTION_BODIES)
for diagnostic in tu.diagnostics:
logging.debug(diagnostic)
logging.info('Translation unit:' + tu.spelling + "\n")
traverseAst(tu.cursor, inclusionConfig)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="CodeDependencyVisualizer (CDV)")
parser.add_argument('-d', required=True, help="directory with source files to parse (searches recusively)")
parser.add_argument('-o', '--outFile', default='uml.dot', help="output file name / name of generated dot file")
parser.add_argument('-u', '--withUnusedHeaders', help="parse unused header files (slow)")
parser.add_argument('-a', '--associations', action="store_true", help="draw class member assiciations")
parser.add_argument('-i', '--inheritances', action="store_true", help="draw class inheritances")
parser.add_argument('-p', '--privMembers', action="store_true", help="show private members")
parser.add_argument('-t', '--protMembers', action="store_true", help="show protected members")
parser.add_argument('-P', '--pubMembers', action="store_true", help="show public members")
parser.add_argument('-I', '--includeDirs', help="additional search path(s) for include files (seperated by space)", nargs='+')
parser.add_argument('-v', '--verbose', action="store_true", help="print verbose information for debugging purposes")
parser.add_argument('--excludeClasses', help="classes matching this pattern will be excluded")
parser.add_argument('--includeClasses', help="only classes matching this pattern will be included")
args = vars(parser.parse_args(sys.argv[1:]))
filesToParsePatterns = ['*.cpp', '*.cxx', '*.c', '*.cc']
if args['withUnusedHeaders']:
filesToParsePatterns += ['*.h', '*.hxx', '*.hpp']
filesToParse = findFilesInDir(args['d'], filesToParsePatterns)
subdirectories = [x[0] for x in os.walk(args['d'])]
loggingFormat = "%(levelname)s - %(module)s: %(message)s"
logging.basicConfig(format=loggingFormat, level=logging.INFO)
if args['verbose']:
logging.basicConfig(format=loggingFormat, level=logging.DEBUG)
logging.info("found " + str(len(filesToParse)) + " source files.")
for sourceFile in filesToParse:
logging.info("parsing file " + sourceFile)
parseTranslationUnit(sourceFile, args['includeDirs'], {
'excludeClasses': args['excludeClasses'],
'includeClasses': args['includeClasses']})
dotGenerator.setDrawAssociations(args['associations'])
dotGenerator.setDrawInheritances(args['inheritances'])
dotGenerator.setShowPrivMethods(args['privMembers'])
dotGenerator.setShowProtMethods(args['protMembers'])
dotGenerator.setShowPubMethods(args['pubMembers'])
dotfileName = args['outFile']
logging.info("generating dotfile " + dotfileName)
with open(dotfileName, 'w') as dotfile:
dotfile.write(dotGenerator.generate())