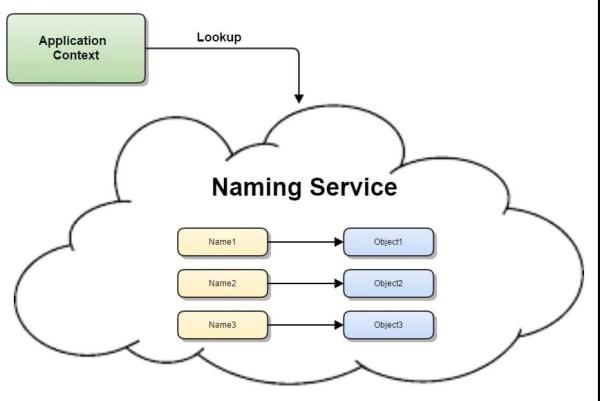
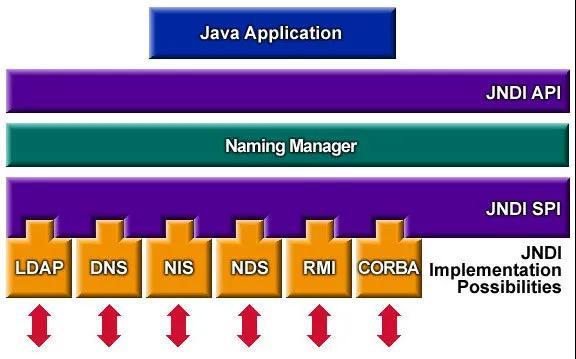
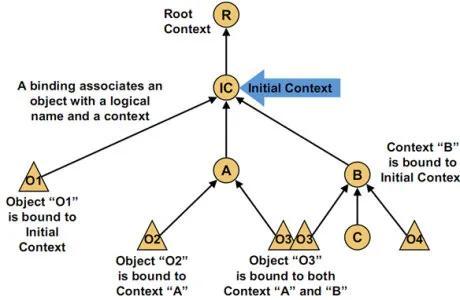
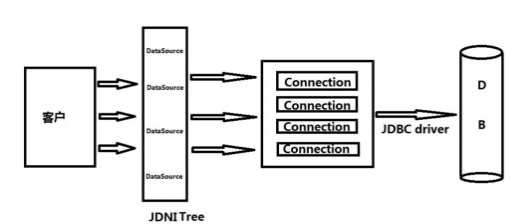
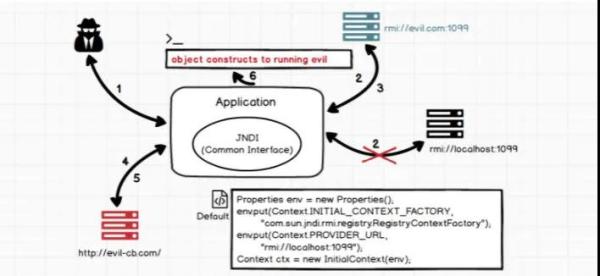
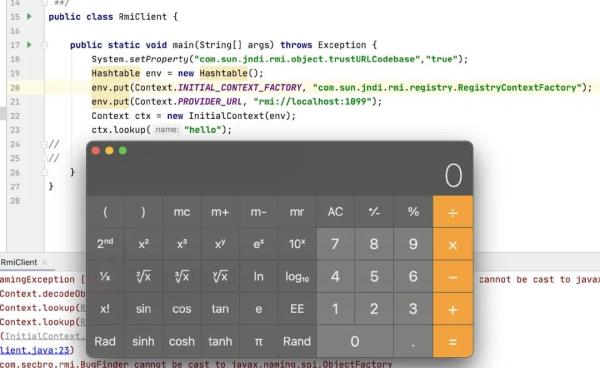
import java.math.BigInteger;
public class Util {
/**
* 用于建立十六进制字符的输出的小写字符数组
*/
private static final char[] DIGITS_LOWER = {'0', '1', '2', '3', '4', '5',
'6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};
/**
* 用于建立十六进制字符的输出的大写字符数组
*/
private static final char[] DIGITS_UPPER = {'0', '1', '2', '3', '4', '5',
'6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F'};
/**
* 整形转换成网络传输的字节流(字节数组)型数据
*
* @param num 一个整型数据
* @return 4个字节的自己数组
*/
public static byte[] intToBytes(int num) {
byte[] bytes = new byte[4];
bytes[0] = (byte) (0xff & (num >> 0));
bytes[1] = (byte) (0xff & (num >> 8));
bytes[2] = (byte) (0xff & (num >> 16));
bytes[3] = (byte) (0xff & (num >> 24));
return bytes;
}
/**
* 四个字节的字节数据转换成一个整形数据
*
* @param bytes 4个字节的字节数组
* @return 一个整型数据
*/
public static int byteToInt(byte[] bytes) {
int num = 0;
int temp;
temp = (0x000000ff & (bytes[0])) << 0;
num = num | temp;
temp = (0x000000ff & (bytes[1])) << 8;
num = num | temp;
temp = (0x000000ff & (bytes[2])) << 16;
num = num | temp;
temp = (0x000000ff & (bytes[3])) << 24;
num = num | temp;
return num;
}
/**
* 长整形转换成网络传输的字节流(字节数组)型数据
*
* @param num 一个长整型数据
* @return 4个字节的自己数组
*/
public static byte[] longToBytes(long num) {
byte[] bytes = new byte[8];
for (int i = 0; i < 8; i++) {
bytes[i] = (byte) (0xff & (num >> (i * 8)));
}
return bytes;
}
/**
* 大数字转换字节流(字节数组)型数据
*
* @param n
* @return
*/
public static byte[] byteConvert32Bytes(BigInteger n) {
byte[] tmpd = null;
if (n == null) {
return null;
}
if (n.toByteArray().length == 33) {
tmpd = new byte[32];
System.arraycopy(n.toByteArray(), 1, tmpd, 0, 32);
} else if (n.toByteArray().length == 32) {
tmpd = n.toByteArray();
} else {
tmpd = new byte[32];
for (int i = 0; i < 32 - n.toByteArray().length; i++) {
tmpd[i] = 0;
}
System.arraycopy(n.toByteArray(), 0, tmpd, 32 - n.toByteArray().length, n.toByteArray().length);
}
return tmpd;
}
/**
* 换字节流(字节数组)型数据转大数字
*
* @param b
* @return
*/
public static BigInteger byteConvertInteger(byte[] b) {
if (b[0] < 0) {
byte[] temp = new byte[b.length + 1];
temp[0] = 0;
System.arraycopy(b, 0, temp, 1, b.length);
return new BigInteger(temp);
}
return new BigInteger(b);
}
/**
* 根据字节数组获得值(十六进制数字)
*
* @param bytes
* @return
*/
public static String getHexString(byte[] bytes) {
return getHexString(bytes, true);
}
/**
* 根据字节数组获得值(十六进制数字)
*
* @param bytes
* @param upperCase
* @return
*/
public static String getHexString(byte[] bytes, boolean upperCase) {
String ret = "";
for (int i = 0; i < bytes.length; i++) {
ret += Integer.toString((bytes[i] & 0xff) + 0x100, 16).substring(1);
}
return upperCase ? ret.toUpperCase() : ret;
}
/**
* 打印十六进制字符串
*
* @param bytes
*/
public static void printHexString(byte[] bytes) {
for (int i = 0; i < bytes.length; i++) {
String hex = Integer.toHexString(bytes[i] & 0xFF);
if (hex.length() == 1) {
hex = '0' + hex;
}
System.out.print("0x" + hex.toUpperCase() + ",");
}
System.out.println();
}
/**
* Convert hex string to byte[]
*
* @param hexString the hex string
* @return byte[]
*/
public static byte[] hexStringToBytes(String hexString) {
if (hexString == null || hexString.equals("")) {
return null;
}
hexString = hexString.toUpperCase();
int length = hexString.length() / 2;
char[] hexChars = hexString.toCharArray();
byte[] d = new byte[length];
for (int i = 0; i < length; i++) {
int pos = i * 2;
d[i] = (byte) (charToByte(hexChars[pos]) << 4 | charToByte(hexChars[pos + 1]));
}
return d;
}
/**
* Convert char to byte
*
* @param c char
* @return byte
*/
public static byte charToByte(char c) {
return (byte) "0123456789ABCDEF".indexOf(c);
}
/**
* 将字节数组转换为十六进制字符数组
*
* @param data byte[]
* @return 十六进制char[]
*/
public static char[] encodeHex(byte[] data) {
return encodeHex(data, true);
}
/**
* 将字节数组转换为十六进制字符数组
*
* @param data byte[]
* @param toLowerCase <code>true</code> 传换成小写格式 , <code>false</code> 传换成大写格式
* @return 十六进制char[]
*/
public static char[] encodeHex(byte[] data, boolean toLowerCase) {
return encodeHex(data, toLowerCase ? DIGITS_LOWER : DIGITS_UPPER);
}
/**
* 将字节数组转换为十六进制字符数组
*
* @param data byte[]
* @param toDigits 用于控制输出的char[]
* @return 十六进制char[]
*/
protected static char[] encodeHex(byte[] data, char[] toDigits) {
int l = data.length;
char[] out = new char[l << 1];
// two characters form the hex value.
for (int i = 0, j = 0; i < l; i++) {
out[j++] = toDigits[(0xF0 & data[i]) >>> 4];
out[j++] = toDigits[0x0F & data[i]];
}
return out;
}
/**
* 将字节数组转换为十六进制字符串
*
* @param data byte[]
* @return 十六进制String
*/
public static String encodeHexString(byte[] data) {
return encodeHexString(data, true);
}
/**
* 将字节数组转换为十六进制字符串
*
* @param data byte[]
* @param toLowerCase <code>true</code> 传换成小写格式 , <code>false</code> 传换成大写格式
* @return 十六进制String
*/
public static String encodeHexString(byte[] data, boolean toLowerCase) {
return encodeHexString(data, toLowerCase ? DIGITS_LOWER : DIGITS_UPPER);
}
/**
* 将字节数组转换为十六进制字符串
*
* @param data byte[]
* @param toDigits 用于控制输出的char[]
* @return 十六进制String
*/
protected static String encodeHexString(byte[] data, char[] toDigits) {
return new String(encodeHex(data, toDigits));
}
/**
* 将十六进制字符数组转换为字节数组
*
* @param data 十六进制char[]
* @return byte[]
* @throws RuntimeException 如果源十六进制字符数组是一个奇怪的长度,将抛出运行时异常
*/
public static byte[] decodeHex(char[] data) {
int len = data.length;
if ((len & 0x01) != 0) {
throw new RuntimeException("Odd number of characters.");
}
byte[] out = new byte[len >> 1];
// two characters form the hex value.
for (int i = 0, j = 0; j < len; i++) {
int f = toDigit(data[j], j) << 4;
j++;
f = f | toDigit(data[j], j);
j++;
out[i] = (byte) (f & 0xFF);
}
return out;
}
/**
* 将十六进制字符转换成一个整数
*
* @param ch 十六进制char
* @param index 十六进制字符在字符数组中的位置
* @return 一个整数
* @throws RuntimeException 当ch不是一个合法的十六进制字符时,抛出运行时异常
*/
protected static int toDigit(char ch, int index) {
int digit = Character.digit(ch, 16);
if (digit == -1) {
throw new RuntimeException("Illegal hexadecimal character " + ch
+ " at index " + index);
}
return digit;
}
/**
* 数字字符串转ASCII码字符串
*
* @param content 字符串
* @return ASCII字符串
*/
public static String StringToAsciiString(String content) {
String result = "";
int max = content.length();
for (int i = 0; i < max; i++) {
char c = content.charAt(i);
String b = Integer.toHexString(c);
result = result + b;
}
return result;
}
/**
* 十六进制转字符串
*
* @param hexString 十六进制字符串
* @param encodeType 编码类型4:Unicode,2:普通编码
* @return 字符串
*/
public static String hexStringToString(String hexString, int encodeType) {
String result = "";
int max = hexString.length() / encodeType;
for (int i = 0; i < max; i++) {
char c = (char) hexStringToAlgorism(hexString
.substring(i * encodeType, (i + 1) * encodeType));
result += c;
}
return result;
}
/**
* 十六进制字符串装十进制
*
* @param hex 十六进制字符串
* @return 十进制数值
*/
public static int hexStringToAlgorism(String hex) {
hex = hex.toUpperCase();
int max = hex.length();
int result = 0;
for (int i = max; i > 0; i--) {
char c = hex.charAt(i - 1);
int algorism = 0;
if (c >= '0' && c <= '9') {
algorism = c - '0';
} else {
algorism = c - 55;
}
result += Math.pow(16, max - i) * algorism;
}
return result;
}
/**
* 十六转二进制
*
* @param hex 十六进制字符串
* @return 二进制字符串
*/
public static String hexStringToBinary(String hex) {
hex = hex.toUpperCase();
String result = "";
int max = hex.length();
for (int i = 0; i < max; i++) {
char c = hex.charAt(i);
switch (c) {
case '0':
result += "0000";
break;
case '1':
result += "0001";
break;
case '2':
result += "0010";
break;
case '3':
result += "0011";
break;
case '4':
result += "0100";
break;
case '5':
result += "0101";
break;
case '6':
result += "0110";
break;
case '7':
result += "0111";
break;
case '8':
result += "1000";
break;
case '9':
result += "1001";
break;
case 'A':
result += "1010";
break;
case 'B':
result += "1011";
break;
case 'C':
result += "1100";
break;
case 'D':
result += "1101";
break;
case 'E':
result += "1110";
break;
case 'F':
result += "1111";
break;
}
}
return result;
}
/**
* ASCII码字符串转数字字符串
*
* @param content ASCII字符串
* @return 字符串
*/
public static String AsciiStringToString(String content) {
String result = "";
int length = content.length() / 2;
for (int i = 0; i < length; i++) {
String c = content.substring(i * 2, i * 2 + 2);
int a = hexStringToAlgorism(c);
char b = (char) a;
String d = String.valueOf(b);
result += d;
}
return result;
}
/**
* 将十进制转换为指定长度的十六进制字符串
*
* @param algorism int 十进制数字
* @param maxLength int 转换后的十六进制字符串长度
* @return String 转换后的十六进制字符串
*/
public static String algorismToHexString(int algorism, int maxLength) {
String result = "";
result = Integer.toHexString(algorism);
if (result.length() % 2 == 1) {
result = "0" + result;
}
return patchHexString(result.toUpperCase(), maxLength);
}
/**
* 字节数组转为普通字符串(ASCII对应的字符)
*
* @param bytearray byte[]
* @return String
*/
public static String byteToString(byte[] bytearray) {
String result = "";
char temp;
int length = bytearray.length;
for (int i = 0; i < length; i++) {
temp = (char) bytearray[i];
result += temp;
}
return result;
}
/**
* 二进制字符串转十进制
*
* @param binary 二进制字符串
* @return 十进制数值
*/
public static int binaryToAlgorism(String binary) {
int max = binary.length();
int result = 0;
for (int i = max; i > 0; i--) {
char c = binary.charAt(i - 1);
int algorism = c - '0';
result += Math.pow(2, max - i) * algorism;
}
return result;
}
/**
* 十进制转换为十六进制字符串
*
* @param algorism int 十进制的数字
* @return String 对应的十六进制字符串
*/
public static String algorismToHEXString(int algorism) {
String result = "";
result = Integer.toHexString(algorism);
if (result.length() % 2 == 1) {
result = "0" + result;
}
result = result.toUpperCase();
return result;
}
/**
* HEX字符串前补0,主要用于长度位数不足。
*
* @param str String 需要补充长度的十六进制字符串
* @param maxLength int 补充后十六进制字符串的长度
* @return 补充结果
*/
static public String patchHexString(String str, int maxLength) {
String temp = "";
for (int i = 0; i < maxLength - str.length(); i++) {
temp = "0" + temp;
}
str = (temp + str).substring(0, maxLength);
return str;
}
/**
* 将一个字符串转换为int
*
* @param s String 要转换的字符串
* @param defaultInt int 如果出现异常,默认返回的数字
* @param radix int 要转换的字符串是什么进制的,如16 8 10.
* @return int 转换后的数字
*/
public static int parseToInt(String s, int defaultInt, int radix) {
int i = 0;
try {
i = Integer.parseInt(s, radix);
} catch (NumberFormatException ex) {
i = defaultInt;
}
return i;
}
/**
* 将一个十进制形式的数字字符串转换为int
*
* @param s String 要转换的字符串
* @param defaultInt int 如果出现异常,默认返回的数字
* @return int 转换后的数字
*/
public static int parseToInt(String s, int defaultInt) {
int i = 0;
try {
i = Integer.parseInt(s);
} catch (NumberFormatException ex) {
i = defaultInt;
}
return i;
}
/**
* 十六进制串转化为byte数组
*
* @return the array of byte
*/
public static byte[] hexToByte(String hex)
throws IllegalArgumentException {
if (hex.length() % 2 != 0) {
throw new IllegalArgumentException();
}
char[] arr = hex.toCharArray();
byte[] b = new byte[hex.length() / 2];
for (int i = 0, j = 0, l = hex.length(); i < l; i++, j++) {
String swap = "" + arr[i++] + arr[i];
int byteint = Integer.parseInt(swap, 16) & 0xFF;
b[j] = new Integer(byteint).byteValue();
}
return b;
}
/**
* 字节数组转换为十六进制字符串
*
* @param b byte[] 需要转换的字节数组
* @return String 十六进制字符串
*/
public static String byteToHex(byte[] b) {
if (b == null) {
throw new IllegalArgumentException(
"Argument b ( byte array ) is null! ");
}
String hs = "";
String stmp = "";
for (int n = 0; n < b.length; n++) {
stmp = Integer.toHexString(b[n] & 0xff);
if (stmp.length() == 1) {
hs = hs + "0" + stmp;
} else {
hs = hs + stmp;
}
}
return hs.toUpperCase();
}
public static byte[] subByte(byte[] input, int startIndex, int length) {
byte[] bt = new byte[length];
for (int i = 0; i < length; i++) {
bt[i] = input[i + startIndex];
}
return bt;
}
}