
I. 背景
数月前我们在攻防两个方向经历了一场“真枪实弹”的考验,期间团队的目光曾一度聚焦到Chromium组件上。其实,早在 Microsoft 2018年宣布 Windows的新浏览器 Microsoft Edge 将基于Chromium内核进行构建之前,伴随互联网发展至今的浏览器之争其实早就已经有了定论,Chromium已然成为现代浏览器的事实标准,市场占有率也一骑绝尘。在服务端、桌面还是移动端,甚至据传SpaceX火箭亦搭载了基于Chromium开发的控制面板。

Chromium内核的安全问题,早已悄无声息地牵动着互联网生活方方面面。基于对实战经历的复盘,本文将从Chromium架构及安全机制概况入手,剖析Chromium组件在多场景下给企业带来的安全风险并一探收敛方案。
II. 浅析Chromium
2.1 Chromium涉及哪些组件?
Chromium主要包含两大核心组成部分:渲染引擎和浏览器内核。
2.1.1 渲染引擎
Chromium目前使用Blink作为渲染引擎,它是基于webkit定制而来的,核心逻辑位于项目仓库的third_party/blink/目录下。渲染引擎做的事情主要有:
- 解析并构建DOM树。Blink引擎会把DOM树转化成C++表示的结构,以供V8操作。
- 调用V8引擎处理JavaScript和Web Assembly代码,并对HTML文档做特定操作。
- 处理HTML文档定义的CSS样式
- 调用Chrome Compositor,将HTML对应的元素绘制出来。这个阶段会调用OpenGL,未来还会支持Vulkan。在Windows平台上,该阶段还会调用DirectX库处理;在处理过程中,OpenGL还会调用到Skia,DirectX还会调用到ANGLE。
Blink组件间的调用先后关系,可用下图概括:
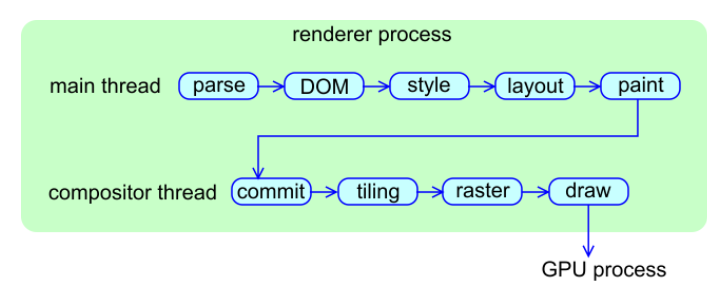
可以说,几乎所有发生在浏览器页签中的工作,都有Blink参与处理。由于涉及许多组件库,不难想象过程中可能会出现的安全风险一定不少。据《The Security Architecture of the Chromium Browser》一文的统计数据,约67.4%的浏览器漏洞都出在渲染引擎中,这也是为什么要引入Sandbox这么重要。
2.1.2 浏览器内核
浏览器内核扮演连接渲染引擎及系统的“中间人”角色,具有一定“特权”,负责处理的事务包括但不限于:
1) 管理收藏夹、cookies以及保存的密码等重要用户信息
2) 负责处理网络通讯相关的事务
3) 在渲染引擎和系统间起中间人的角色。渲染引擎通过Mojo与浏览器内核交互,包含组件:download、payments等等。
2.2 Chromium的沙箱保护原理/机制
1、为什么要引入沙箱?
前述部分提到,Chromium渲染引擎涉及大量C++编写的组件,出现漏洞的概率不小。因此,基于纵深防御理念浏览器引入了涉及三层结构。渲染引擎等组件不直接与系统交互,而是通过一个被称为MOJO的IPC组件与浏览器引擎通讯(也被称为:broker),再与系统交互。进而可以实现:即便沙箱中的进程被攻破,但无法随意调用系统API产生更大的危害。有点类似:即便攻破了一个容器实例,在没有逃逸或提权漏洞的情况下,宿主机安全一定程度上不受影响(实际上,浏览器的Sandbox和容器隔离的部分技术原理是相似的)。
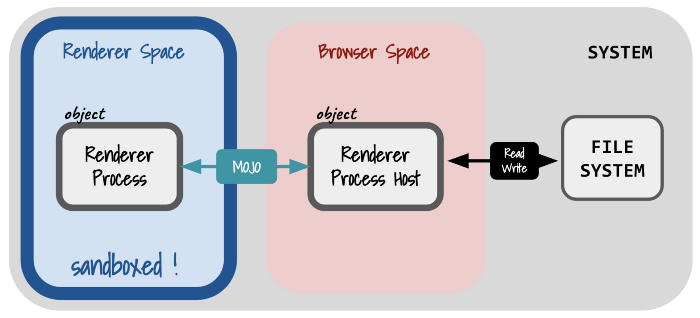
2、浏览器的哪些部分是运行在沙箱中的?
浏览器渲染引擎、GPU、PPAPI插件以及语音识别服务等进程是运行在沙箱中的。此外不同系统平台下的部分服务也会受沙箱保护,例如Windows下打印时调用的PDF转换服务、icon浏览服务;MacOS下NaCl loader、需要访问IOSurface的镜像服务等。
更多细节可查阅Chromium项目文件sandbox_type.h和sandbox_type.cc中的源码定义:
|
1 2 3 4 5 |
// sandbox/policy/sandbox_type.h Line 24 enum class SandboxType { // sandbox/policy/sandbox_type.cc Line 21 bool IsUnsandboxedSandboxType(SandboxType sandbox_type) { |
3、Windows和Linux下沙箱实现的技术细节
Windows
在Windows平台上,Chrome组合使用了系统提供的Restricted Token、Integrity Level、The Windows job object、The Windows desktop object机制来实现沙盒。其中最重要的一点是,把写操作权限限制起来,这样攻击这就无法通过写入文件或注册表键来攻击系统。
Linux
Chrome在Linux系统上使用的沙箱技术主要涉及两层:
| 层级 | 功能 |
|---|---|
| Layer - 1 | 用于限制运行在其中的进程对资源的访问 |
| Layer - 2 | 用于有关进程对系统内核某些攻击面的访问 |
第一层沙箱采用setuid sandbox方案。
其主要功能封装在二进制文件chrome_sandbox内,在编译项目时需要单独添加参数“ninja -C xxx chrome chrome_sandbox”编译,可以通过设置环境变量CHROME_DEVEL_SANDBOX指定Chrome调用的setuid sandbox二进制文件。
setuid sandbox主要依赖两项机制来构建沙盒环境:CLONE_NEWPID和CLONE_NEWNET方法。CLONE_NEWPID一方面会借助chroots,来限制相关进程对文件系统命名空间的访问;另一方面会在调用clone()时指定CLONE_NEWPID选项,借助PID namespace,让运行在沙盒中的进程无法调用ptrace()或kill()操作沙盒外的进程。而CLONE_NEWNET则用于限制在沙盒内进程的网络请求访问,值得一提的是,使用该方法需要CAP_SYS_ADMIN权限。这也使得当Chrome组件在容器内运行时,沙箱能力所需的权限会和容器所管理的权限有冲突;我们无法用最小的权限在容器里启动Chrome沙箱,本文4.2.2部分会详细阐述此处的解决之道。
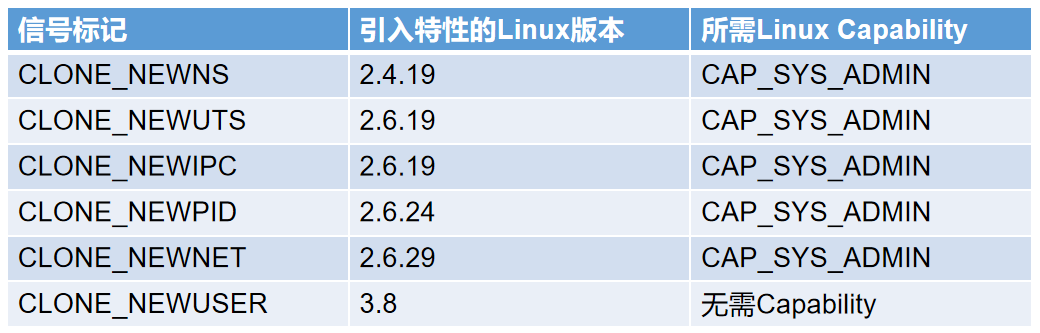
更多详参见Linux Namespace及cgroups介绍说明:《Resource management: Linux kernel Namespaces and cgroups》- https://sites.cs.ucsb.edu/~rich/class/cs293b-cloud/papers/lxc-namespace.pdf
由于setuid sandbox方案存在一定短板。自Chrome 44版本起已推荐namespaces sandbox来替代setuid sandbox方案,其主要依赖于Linux内核提供的user namespaces机制,相关逻辑可在项目的如下行代码看到:
|
1 |
https://source.chromium.org/chromium/chromium/src/+/main:sandbox/policy/linux/sandbox_linux.cc;drc=2311701cab51ef03be34fba491e0a855371d4f84;l=544 |
第二层沙箱采用Seccomp-BPF方案,用来限制进程访问内核特定攻击面。
其原理是:通过将Seccomp和BPF规则结合,实现基于用户配置的策略白名单,对系统调用及其参数进行过滤限制。
|
1 2 |
// sandbox/policy/linux/sandbox_linux.cc Line 413 StartSeccompBPF(sandbox_type, std::move(hook), options); |
2.3 小结
Chromium涉及的组件众多,使用的C++语言天然决定了会潜在不少安全问题。例如:一个V8中的内存安全问题(如:CVE-2021-21220、CVE-2019–5782),组合Web Assembly将Shellcode写入RWX Pages,在未受沙箱保护的情况下,就能实现远程代码执行。
沙箱机制组合使用了OS相关的隔离能力(如:Linux平台上的namespace、Seccomp-BPF机制),限制了被沙箱保护进程的资源访问以及syscall能力,能很好的防止出现在渲染引擎中的漏洞,被用于直接实现RCE :但沙箱机制也存在一些不足,历史上也出现过沙箱逃逸的漏洞,例如:Google Project Zero团队曾发布的《Virtually Unlimited Memory: Escaping the Chrome Sandbox》一文。
综上,在无法100%预防Chromium渲染进程出现内存安全问题的情况下,开启沙箱保护是一项必须落地的最佳安全实践。
III. Chromium漏洞攻击利用场景分析
作为一款客户端组件,在评估Chromium漏洞时,常常会聚焦于客户端的攻防场景。但根据我们的经验,受chromium漏洞影响的不仅有客户端应用,也包含了服务器上运行的程序,例如:部署在服务器端、基于Chrome Headless应用的爬虫程序等。
3.1 服务器端
3.1.1 禁用沙盒的chromium headless应用
随着Phantomjs项目停止维护,Chromium headless已经成为Headless Browser的首选。在日常开发、测试、安全扫描、运维中,有许多地方会用到Headless Browser,包括不限于以下场景:
|
1 2 3 4 5 |
● 前端测试 ● 监控 ● 网站截图 ● 安全扫描器 ● 爬虫 |
在这些场景中,如果程序本身使用的Chromium存在漏洞,且访问的URL可被外部控制,那么就可能受到攻击最终导致服务器被外部攻击者控制。
以常见的使用Chrome headless的爬虫为例,如果在一些网站测试投放包含exploit的链接,有概率会被爬虫获取,相关爬取逻辑的通常做法是新建tab导航至爬取到的链接。此时,如果爬虫依赖的chromium应用程序更新不及时,且启动时设置了—no-sandbox参数,链接指向页面内的exploit会成功执行,进而允许攻击者控制爬虫对应的服务器。
为何 —no-sandbox 会如此泛滥呢?我们不妨来看一下,当我们在ROOT下启动Chrome,会有什么样的提示呢?

我们会得到 Running as root without —no-sandbox is not supported 的错误提示,且无法启动 Chrome;这对于以研发效率和产品功能优先的研发同学来说无异于提示“请使用 —no-sandbox 来启动 Chrome”, 应用容器化的进程也加剧了使用ROOT用户启动应用程序的情况。你不得不创建一个新的普通用户来启动Chrome服务,例如在 Dockerfile 里加入 RUN useradd chrome 和 USER chrome 语句;有些基于Chrome的著名第三方库甚至会在代码中隐形植入关闭 sandbox的代码,当研发同学在ROOT下启动应用程序时,第三方库会默认关闭sandbox,添加 —no-sandbox 参数,例如 Golang 第三方 package Chromedp 的代码:
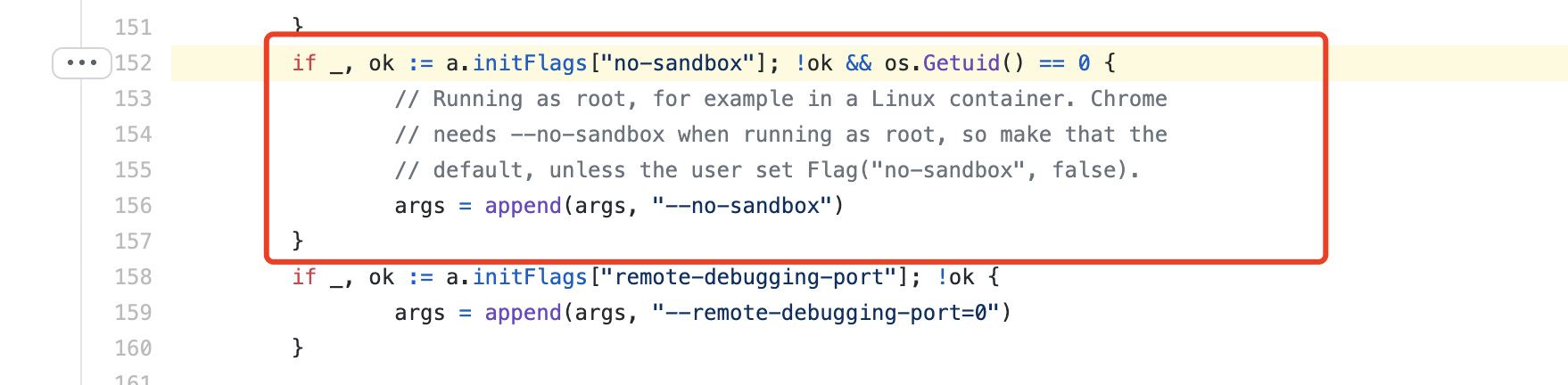
此时,对于开发同学来说使用 —no-sandbox 参数甚至是无感的,直至自己的容器或服务器被攻击者入侵控制。
即使研发同学sandbox来避免安全风险的意识,在容器化的应用内启动chrome也是不易的;为镜像创建一个新的非ROOT用户并非唯一的条件,Chrome sandbox 需要调用一些特定的 syscall 或 linux capabilities 权限用于启动 sandbox 逻辑,同时容器镜像需要打入 chrome-sandbox二进制文件并写入环境变量以供Chrome进程找到sandbox程序。若未对Chrome容器进行特定的权限配置,chrome将输出 Operation not permitted 报错信息并退出。

所以,网络上有大量的文档和博客推荐启用 —no-sandbox 来解决 Chrome headless 的使用问题,这也间接助长了 —no-sandbox 参数这种错误用法的泛滥:

我们将在后面的章节里详细为您讲解 Chrome Sandbox 在容器以及容器集群中方便快捷且安全合理的部署解决方案。
3.1.2 浅议攻击方式
未知攻焉知防?虽然在已有Exploit的情况下进行漏洞利用并不困难,但知悉漏洞利用的流程和攻击行为有助于我们更好的构建安全能力。以下以最近的CVE-2021-21224漏洞为例,当服务端上程序使用的chromium版本存在漏洞时,且未开启Sandbox,可以利用这个漏洞来获取服务器的权限。
首先攻击者使用metasploit生成shellcode,这里假设chromium是在linux上运行且架构为x64。同时,考虑到爬虫运行结束后往往会结束浏览器进程,通过设置PrependFork为true可以保证session的持久运行。

生成shellcode后监听端口:

实战中,可以通过投递带exploit的链接到各个网站上,这里假设攻击者控制的服务器正在被爬取或者正在被渗透测试人员的扫描器扫描:
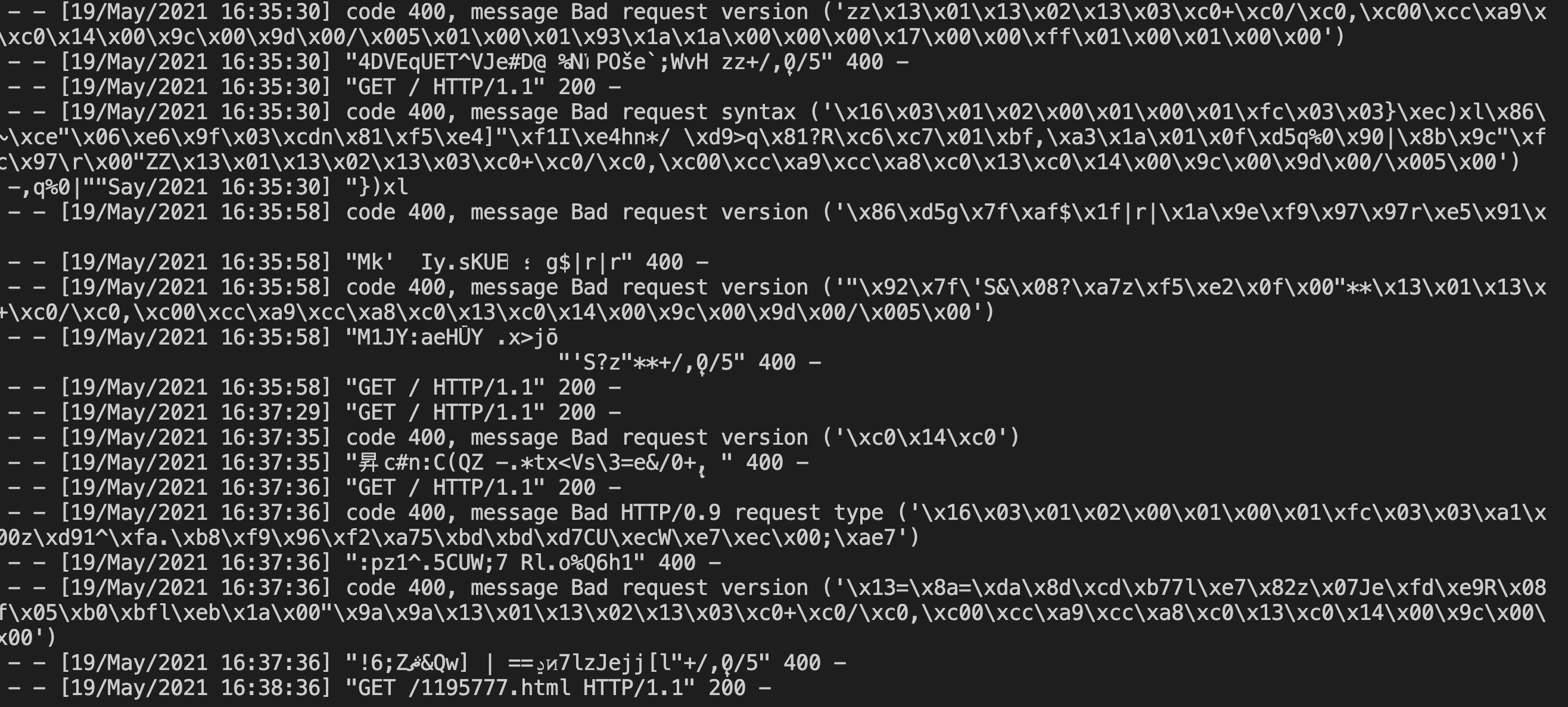
成功获取到爬虫/扫描器的服务器session:

meterpreter的进程是fork后的chrome子进程:

可以猜想,不仅是各种内嵌浏览器的客户端程序易受chromium相关漏洞影响,可能有相当多的服务端程序也暴露在chromium 0Day/Nday的攻击下。 chromium漏洞将会成为企业防御边界的新的突破口,而这个突破口是自内而外的,相比开放端口在外的服务漏洞,这种攻击可能会更隐蔽。
作为防御方,我们也可以利用chromium漏洞来反制一些攻击者,如果攻击者安全意识较差或者使用的工具安全性不强,防御方在服务器上托管带有exploit的网页,攻击者的爬虫/扫描器扫到了这些网页就可能被反制攻击。
3.2 客户端
在面对Chromium组件风险时,客户端场景往往首当其冲。通常,其风险成立条件有两点:1、使用了存在漏洞的Chromium组件;2、可以指定Webview组件访问特定的网站地址。
3.2.1 移动客户端
目前,移动客户端主要分两大“阵营”:安卓和iOS,最大相关风险是Webview类组件。前者 Android System Webview是基于Chromium源代码开发的,所以当1 Day披露时,需要及时跟进影响;iOS App一般会使用WKWebView和JavaScriptCore,Chromium 1 Day影响iOS应用的可能性较低。
客户端内置Webview浏览器窗口
除了使用系统自带的Webview组件,另外一种比较常见且更容易引起注意的方式是使用应用内置或独立于系统之外的浏览器组件;此时,应用会选用Chromium体系的概率较高。应用选择自己内置并维护浏览器组件的原因有很多,例如以下几类需求:
1、在浏览器内核层回收更多用于Debug的客户端信息;
2、支持如夜间模式、中文优化等用户需求;
3、支持更多的视频格式和文件格式;
也有应用为了应对此前App Store在WWDC大会提出的限制(即App Store中的所有应用都必须启用App Transport Security 安全功能并全量走HTTPS),使用改过的Webview组件曲线救国,以便达到App Store的合规需求。
也因为应用自己维护所使用的浏览器组件,当系统的WebView跟随系统升级而修复漏洞时,应用所使用的的浏览器组件并不跟着更新;作为应用开发者自己维护的硬分支,Chromium不断的功能变更和漏洞修复补丁都需要应用开发者自行合并和兼容;这不仅需要硬核的浏览器研发能力也需要日以继夜不断的坚持。再加上,无论在移动端还是桌面客户端,在使用应用内WebView时为了更加轻便和简洁,浏览器组件多是以单进程的方式启动;而在我们之前对Sandbox技术的介绍中,浏览器Sandbox和单进程WebView组件显然是冲突的;这也使得历史上关闭Sandbox能力的客户端程序,在漏洞修复过程中,对于开启Sandbox的修复操作存在历史包袱。
无论如何,我们始终不建议移动端应用的WebView组件可以由用户控制并打开开放性的页面;这会使得应用内加载的内容可能存在不可控或不可信的内容。WebView组件可以打开的URL,应该用白名单进行限制;特别是可以用 Deeplink 打开并且存在 URL 参数的 WebView。
3.2.2 桌面客户端
许多桌面客户端应用也是基于Chromium构建的。一类是基于Chromium定制的浏览器产品、或内置基于Chromium开发Webview组件的桌面客户端应用;另一类是基于Electron构建的桌面客户端应用。
前者与传统Chrome浏览器或是嵌入在移动客户端的Webview组件类似,如果未开启沙箱保护,面临很大的风险。而后者Electron则是在评估Chromium漏洞攻防利用场景时,比较容易被忽视的一块。Electron基于Chromium和Node构建,其主要特性之一就是能在渲染进程中运行Node.js。目前有许多客户端工具基于它开发,涉及:VS Code、Typora、Slack等。默认情况下,渲染器进程为受沙箱保护,这是因为:大多数Node.js 的API都需要系统权限,没有文件系统权限的情况下require()是不可用的,而该文件系统权限在沙箱环境下是不可用的,但功能性进程受沙箱保护。 Electron除面临渲染引擎本身的安全风险外,主要风险源自于其本身的功能特性 —— nodeIntegration。当该选项被设置为true,表示renderer有权限访问node.js API,进而执行“特权”操作。这时如果攻击者能自由控制渲染的页面内容,则可直接实现RCE。
IV. 风险收敛方案
回到我们今天的主题:修复和防御。如上我们知道,Chromium的安全问题是方方面面的,各类安全风险也会在不同的场景上产生,那么如何收敛就是企业安全建设永恒的话题;最后我们想分享我们的安全实践经验,力求解答在安全实践中我们遇到的以下几个问题,如:Chrome组件的漏洞都有哪些?Google又是如何跟进它们的?我们又该如何评估和检测Chrome持续更新过程中所公开的1Day风险?最终如何修复?Linux容器中开启Chrome沙盒的最佳实践又是什么?
4.1 风险监测和评估
4.1.1 风险情报
有两个渠道可以及时了解到Chromium漏洞披露情况:
● Chromium工单系统。该平台上收录了所有已公开的Chrome安全Issue,可借助特定关键词检索。如检索已公开的高风险安全问题,可访问:https://bugs.chromium.org/p/chromium/issues/list?can=1&q=Security_Severity%3DHigh%20&colspec=ID%20Pri%20M%20Stars%20ReleaseBlock%20Component%20Status%20Owner%20Summary%20OS%20Modified&sort=-modified&num=100&start=
● Chrome发布日志。Chrome稳定版本发布消息会在https://chromereleases.googleblog.com/上发出,和稳定版本发布消息一起的还有该版本做了哪些安全更新以及对应漏洞的奖金。
事实上,甲方安全人员还可以借助一些技巧,提前了解安全问题的修复细节。Gerrit是基于git的一款Code Review平台,chrome team使用该平台进行code review:https://chromium-review.googlesource.com/。该平台上的主题会关联对应的issue id,通过对应修复commit的主题可以了解到issue的修复方案和代码。
chromium使用https://bugs.chromium.org对chromium的bug进行跟踪。可以用短链来访问对应的issue,例如issue 1195777可以用该链接访问:https://crbug.com/1195777。
chromium安全问题对应关联的issue在修复期间并且在补丁发布后也不一定是可见的,官方给出的披露原则是在补丁广泛应用后才会开放issue的限制。但是Gerrit上对issue修复代码的code review和关联信息是一直可见的,我们如果想了解某个issue具体的修复代码和方案可以在Gerrit上找到。
以issue 1195777为例,在Gerrit使用bug搜索关键字可以搜到对应commit的code review主题:

而如果只有CVE编号,CVE的References一般会给出issue的短链,虽然通常该issue限制访问,但是仍可以通过Gerrit了解相关issue的具体修复代码,安全研究者可以根据这些修复代码对该问题进行分析,进而推测出漏洞复现代码。
难怪Twitter上某位研究员会说:“如果0-Day有Chromium Bug Tracker的编号,那它就不算0-Day了”。

另外,还可以从 国家信息安全漏洞库 检索相关的漏洞问题。
4.1.2 风险评估
通常,在Chromium官方披露漏洞或外部已出现在野利用的案例后,应进行风险评估,主要聚两个问题:
● 公司内哪些产品受漏洞影响?
● 外部披露的exp是否能真实利用形成危害?
在获悉一个漏洞的存在后,安全人员需要评估漏洞对公司的影响如何。通常一个可利用的漏洞在披露后会马上有安全人员写出exploit,而公开的exploit将导致利用门槛的大幅降低。因此,常常需要监控公开信息渠道的exploit信息,例如:监控Github、Twitter等平台的消息。但是早在exploit披露前,就可以通过
Chromium Monorail系统中的issues、代码CL或者更新日志提前了解风险。
一个漏洞的影响评估流程可以按下面几步走:
1、 确定存在漏洞组件为哪个部分。
2、 采集使用了该组件的产品(包括:使用了嵌入式浏览器的客户端、单纯使用v8引擎等组件的软件、使用了chrome headless的服务端程序);有些产品仅使用chrome的一部分组件可能不受影响。例如:v8就会影响所有用Chromium内核的产品,但iOS客户端如果用JavaScriptCore,则不受影响。
3、 确认使用存在漏洞组件的产品使用的版本是否受影响,如果产品本身对chromium进行定制化开发的情况下,难以根据版本确定,可以通过PoC(部分场景下,可借助Chromium项目中的单元测试用例)进行黑盒测试或者白盒审计受影响代码是否存在,是否存在漏洞的触发路径。
4、 原则上内存破坏类的漏洞在没有exploit公开的情况下也需要尽快修复,存在公开exploit的情况下,需要立即修复;有时候exploit使用到的exploit技术可能仅适用于某些版本的chromium,但是并不代表这些版本之外的chromium完全没有利用的可能。例如使用WebAssembly创建RWX pages来写入shellcode的技术在客户端使用的chromium版本不支持,但依旧存在通过ROP等技术来到达RCE的可能性。
4.1.3 风险检测
4.1.3.1 黑盒测试
V8等组件会编写单元测试js文件,可以基于此修改形成页面,来通过黑盒的方式判断组件是否受对应漏洞影响。对于漏洞测试来说,这个资源也是极好的TestCase。
以CVE-2021-21224为例,编写黑盒测试用例过程如下:
1、 通过Issue编号定位到对应的Chromium Gerrit工单
https://chromium-review.googlesource.com/c/v8/v8/+/2838235
2、 定位到官方提供的、针对该漏洞的单元测试文件
https://chromium-review.googlesource.com/c/v8/v8/+/2838235/4/test/mjsunit/compiler/regress-1195777.js
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
(function() { function foo(b) { let y = (new Date(42)).getMilliseconds(); let x = -1; if (b) x = 0xFFFF_FFFF; return y < Math.max(1 << y, x, 1 + y); } assertTrue(foo(true)); %PrepareFunctionForOptimization(foo); assertTrue(foo(false)); %OptimizeFunctionOnNextCall(foo); assertTrue(foo(true)); })(); |
3、 基于单元测试文件修改生成黑盒测试用例
如果仔细观察,会发现上述单元测试代码中包含%开头的函数。它们是v8引擎内置的runtime函数,用于触发v8引擎的某些功能特性,需要在v8的debug版本d8命令行工具启动时,追加—allow-natives-syntax参数才会生效。因此,直接将上述单元测试js来测试是无法准确测出是否存在漏洞的。但可以通过编写js代码,实现相同的效果,例如:
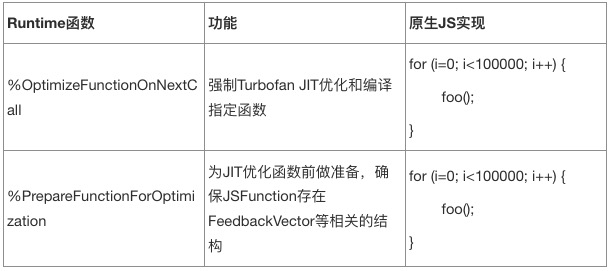
值得一提的是,前述漏洞的单元测试用例并不会造成浏览器tab崩溃,而只是输出的数值与预期不符。因此,可以看到上述单元测试用例中引入了assertTrue、assertEquals等断言方法,用于判断单元测试数值是否与预期相等。如果不等,则认为存在漏洞。在进行改造时,也要一并用自己的JavaScript代码替换。最终,前述官方提供的测试用例可改造如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
function foo(b) { let y = (new Date(42)).getMilliseconds(); let x = -1; if (b) x = 0xFFFF_FFFF; return y < Math.max(1 << y, x, 1 + y); } function check(val) { console.log(val); if(!val){ alert("CVE-2021-21224 found!") } } // 断言函数,判断函数返回值是否为true // assertTrue(foo(true)); let val1 = foo(true); check(val1); // v8内置runtime函数 // %PrepareFunctionForOptimization(foo); for (i=0; i<100000; i++) { foo(false); } // 断言函数,判断函数返回值是否为true // assertTrue(foo(false)); let val2 = foo(false); check(val2); // v8内置runtime函数 // %OptimizeFunctionOnNextCall(foo); for (i=0; i<100000; i++) { foo(true); } // 断言函数,判断函数返回值是否为true // assertTrue(foo(true)); let val3 = foo(true); check(val3); |
4、 最终效果如下
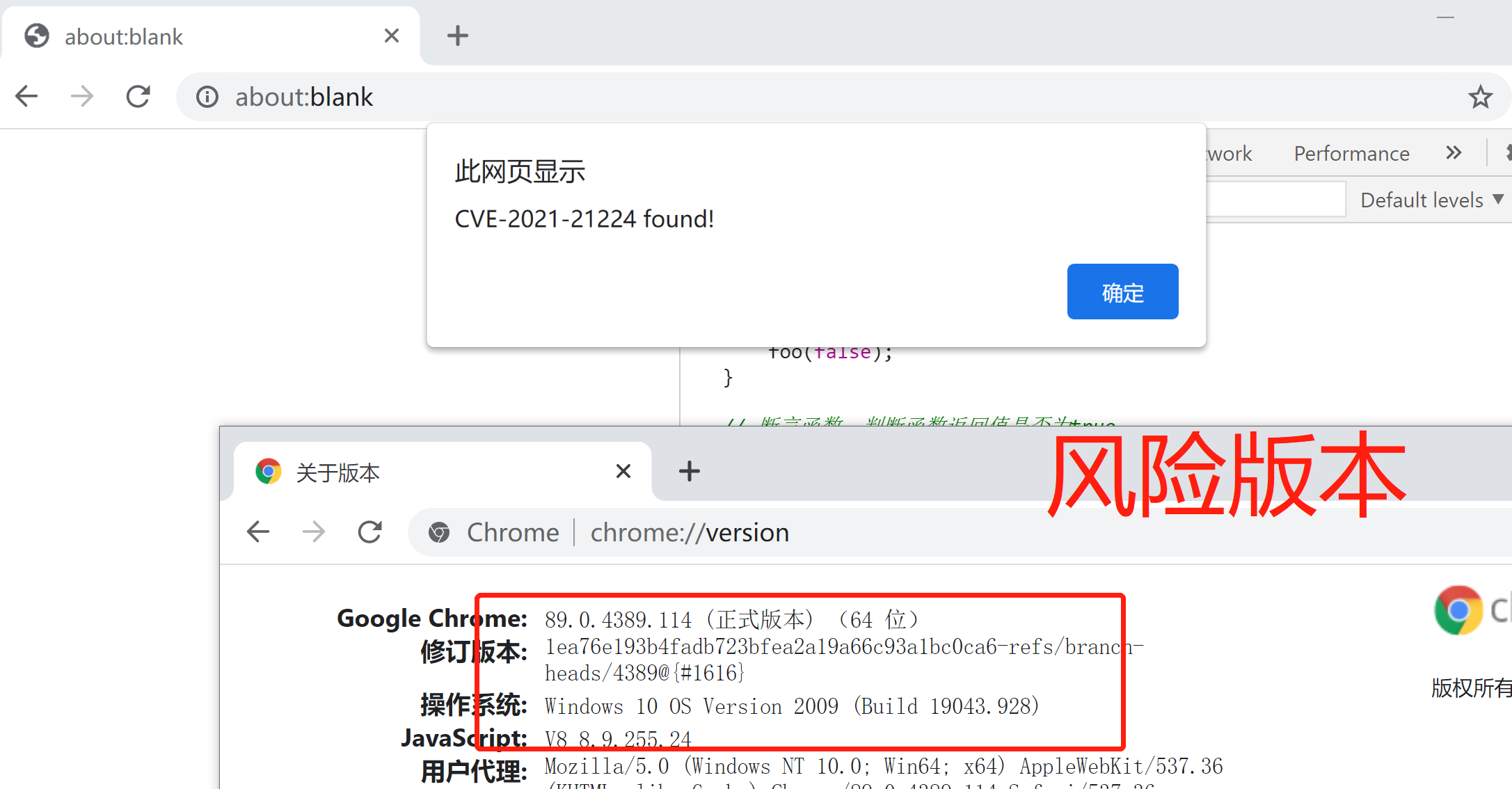
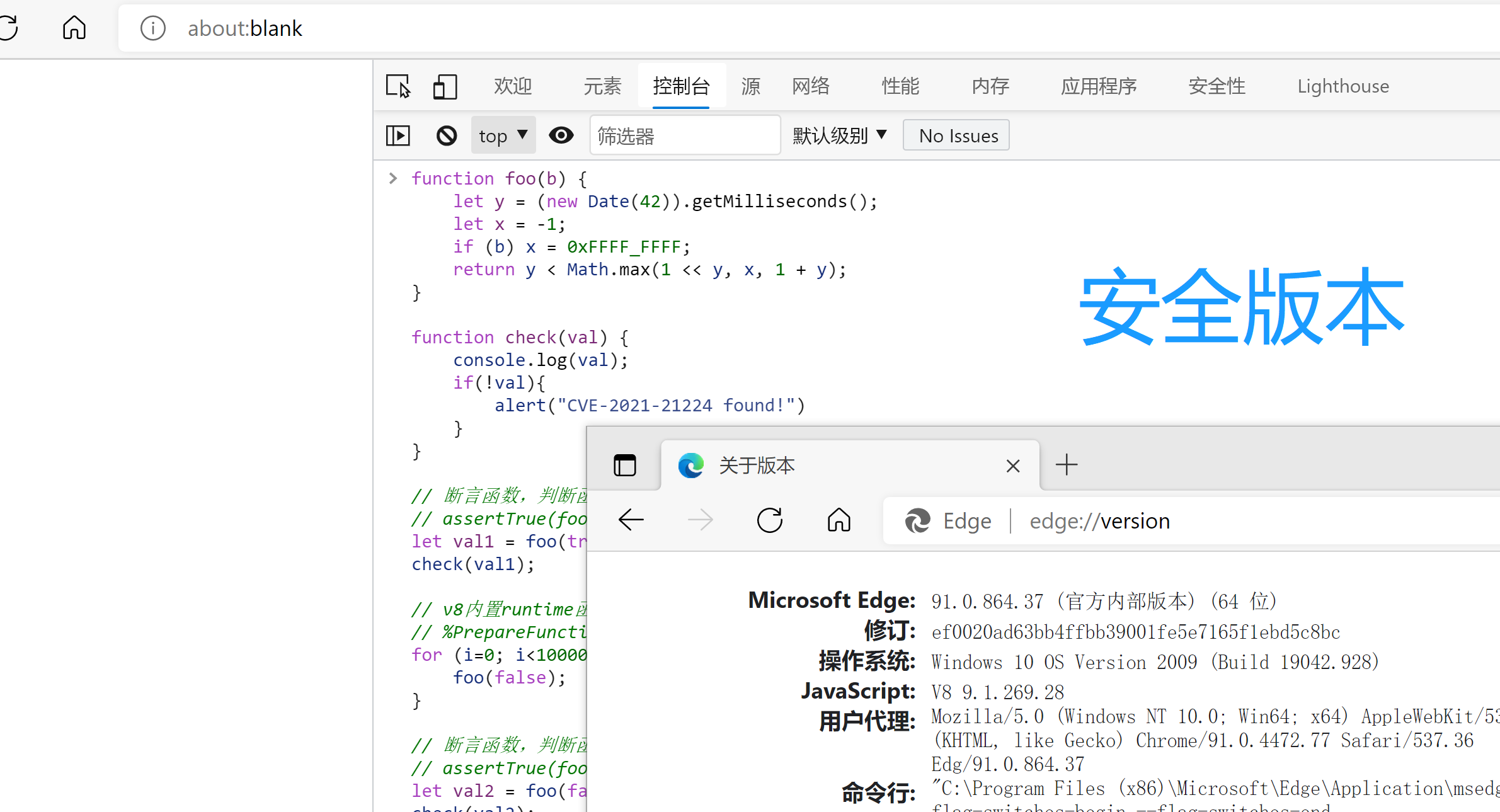
4.1.3.2 静态代码扫描
如上面所述,由于Chrome漏洞即便在没有正式发布安全公告前,就已经有Issue ID,且能通过Gerrit平台找到涉及的代码变动。因此,开发人员可以抢先在公司内部代码仓库进行全局静态代码扫描并修复问题。
| 目的 | 策略 | 目的 |
|---|---|---|
| 收集包含chromium组件的仓库 | 扫描特定文件名特征(如有需要可添加一些代码特征) | 掌握企业内应用的组件指纹 |
| 精确判断某个Issue对应的代码是否已修复 | 扫描文件名特征 + 每个Issue对应的代码特征 | 追踪特定漏洞的修复情况 |
● 收集包含chromium组件的仓库
不同的项目可能会引入Chromium整体或部分相关的组件,通常可结合文件名、或特定的代码片段,在公司的代码仓库中收集包含相关指纹的仓库。
● 精确判断某个Issue对应的代码是否已修复
以要精准扫描全局代码仓库中是否存在涉及v8组件的CVE-2021-21224的漏洞代码为例。可基于semgrep类方案,对公司代码仓库进行全局检查,编写静态代码扫描步骤如下:
1、 根据Issue号找到对应的漏洞修复代码变动
● https://chromium-review.googlesource.com/c/v8/v8/+/2838235
● https://chromium-review.googlesource.com/c/v8/v8/+/2838235/4/src/compiler/representation-change.cc
2、确定涉及文件representation-change.cc,存在漏洞的代码特征为
|
1 2 3 4 5 6 7 |
if (output_type.Is(Type::Signed32()) || output_type.Is(Type::Unsigned32())) { op = machine()->TruncateInt64ToInt32(); } else if (output_type.Is(cache_->kSafeInteger) && use_info.truncation().IsUsedAsWord32()) { op = machine()->TruncateInt64ToInt32(); } |
3、可编写semgrep规则如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
rules: - id: chromium-v8-1195777 message: | A Type Confusion vulnerability in Chromium v8 Engine, labeled as CVE-2021-21224, is found in the project. Please fix this bug by following the [instructions](https://iwiki.woa.com/pages/viewpage.action?pageId=801201056) on iWiki. languages: - generic metadata: references: - https://chromereleases.googleblog.com/2021/04/stable-channel-update-for-desktop_20.html - https://chromium-review.googlesource.com/c/v8/v8/+/2817791/4/src/compiler/representation-change.cc category: security severity: WARNING pattern: | if (output_type.Is(Type::Signed32()) || output_type.Is(Type::Unsigned32())) {...} else if (output_type.Is(cache_->kSafeInteger) && use_info.truncation().IsUsedAsWord32()) {...} paths: include: - "representation-change.cc" |
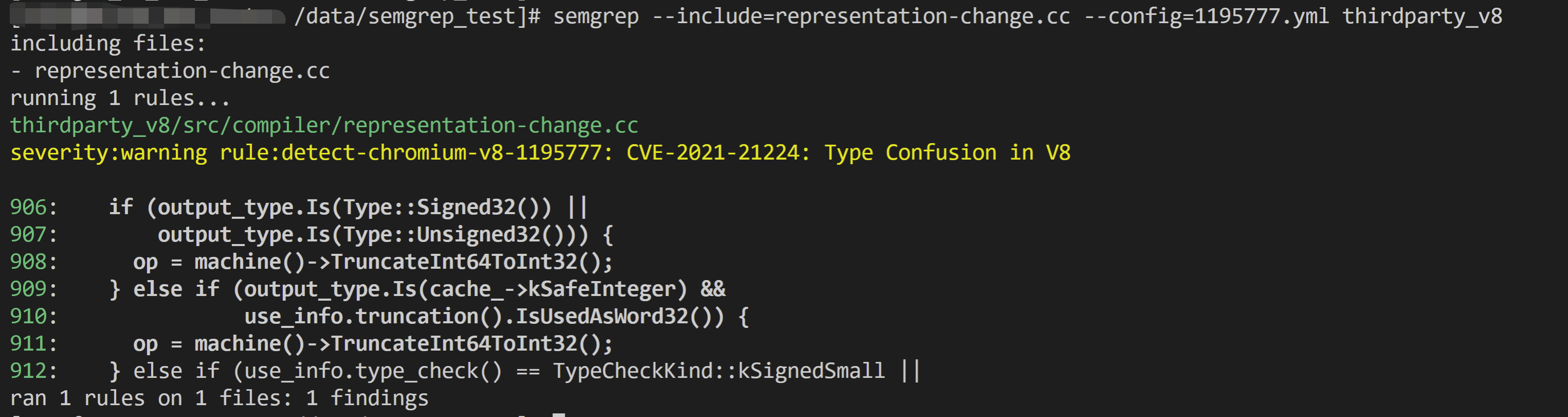
4、调用命令扫描
|
1 |
semgrep --include=representation-change.cc --config=1195777.yml thirdparty_v8 |
5、最终效果,如下
4.1.3.3 主机Agent采集
针对部署在服务器端、且使用了Chromium的程序,除了上述方法之外,可以考虑借助HIDS、EDR或RASP等系统采集进程特征,排查存在风险的实例。
同时满足下面两个条件的 cmdline,其进程我们就可以认为是存在风险的:
● 程序名包含 Chrome 或 Chromium
● 且 Cmdline 中包含 —no-sandbox 参数或 —disable-setuid-sandbox
关于误报
这里大家可能会产生疑问,这里为什么单独检测 Sandbox 的开启与关闭就判断风险呢?若Chromium组件已经使用最新发布的commit编译而成,包含了所有的漏洞补丁,也一样不会受到1Day和NDay漏洞的影响。其实,这里主要考虑到Chrome在对漏洞修复是十分频繁的,持续的升级存在一定的维护成本,且不排除攻击者拥有Chromium 0Day的可能。相较之下,逃逸Sandbox以控制浏览器所在的主机,是比较困难的;所以要求线上业务,尽可能开启 Chromium Sandbox特性。
关于漏报
另外,以上方案若Chrome可执行文件被修改了文件名,则容易产生漏报。另一种可选的方案是:提取出多个Chrome的特有选项进行过滤。例如,headless浏览器启动时一般不会导航至特定url,此时命令行会存在about:blank,再用Chrome特定的区别于其他浏览器的选项进行排除。
更复杂的方案可以提取出Chrome执行文件的文件特征,或者建立Chrome执行文件的hashsum数据库来判断进程的执行文件是否是Chrome浏览器,进而再筛选启动时用了不安全配置的进程。其实,我们在大规模观察相关的进程数据和运营之后,发现利用 —no-sandbox 单个因素进行进程数据分析并获取未开启Sandbox的Chromium进程,这样简单粗暴的做法并不会产生太多误报;有些进程看似非 Chromium 浏览器,但其实也集成了 Chromium 并使用 no-sandbox 参数。
4.2 风险修复
4.2.1 通用修复方案
无论是客户端还是服务端,为了解决Chrome漏洞的远程命令执行风险,启用Chrome Sandbox,去除启动Chrome组件时的 —no-sandbox参数都是必须推进的安全实践。
如果客户端程序直接使用了Chrome的最新版本,且未进行过于复杂的二次开发和迁移,没有历史包袱的话,在客户端里开启Chrome Sandbox,其实就是使用Chrome组件的默认安全设计,障碍是比较小的。
此处根据不同场景和需求,存在三种不同的修复方案:
方案1. 启用Sandbox
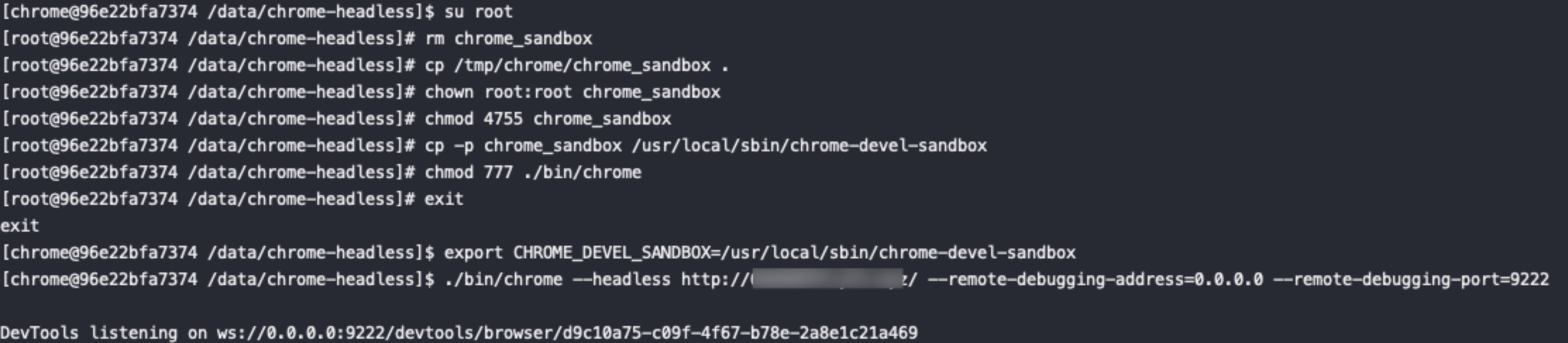
1、启动 Chrome 时切勿使用 —no-sandbox 参数,错误的例子如:./bin/chrome --remote-debugging-address=0.0.0.0 --remote-debugging-port=9222 --disable-setuid-sandbox --no-sandbox
2、使用普通用户而非 root 用户启动 chrome headless 进程
方案2. 更新Chromium内核版本(后续维护成本极高):
下载 https://download-chromium.appspot.com/ 中的最新版本进行更新,并在后续迭代中持续升级到最新版(Chromium的最新版本会编译最新的MR和Commit,因此也会修复Chrome未修复的0.5Day漏洞,下载链接包含了所有的操作系统的 Chromium ,例如Linux 可访问 https://download-chromium.appspot.com/?platform=Linux_x64&type=snapshots 下载)。
请注意,如果不希望相似的安全风险如之前的Fastjson那样需要反复跟进并且高频推动业务修复,强烈建议安全团队推动业务参考方案一开启Sandbox,方案二可以当成短期方案规避当前风险。经统计,2010年至今Google共对外公开Chromium高危漏洞1800多个;Chromium的漏洞修复十分频繁,若不开启Sandbox,需持续更新最新版本。
若要启用Sandbox,需要解决一定的依赖:首先,Chrome的Sandbox技术依赖于Linux内核版本,低版本的内核无法使用。各Sandbox技术Linux内核依赖可参考下图

Chrome 运行时会寻找 chrome-sandbox 文件,一般下载 Chrome 的 Release 时,Chrome程序目录下都包含了 Sandbox 程序,若无法寻找到 chrome-sandbox 文件可能会产生下述 Error 信息:
[0418/214027.785590:FATAL:zygote_host_impl_linux.cc(116)] No usable sandbox! Update your kernel or see https://chromium.googlesource.com/chromium/src/+/master/docs/linux/suid_sandbox_development.md for more information on developing with the SUID sandbox. If you want to live dangerously and need an immediate workaround, you can try using —no-sandbox.
可参考
https://github.com/puppeteer/puppeteer/blob/main/docs/troubleshooting.md#alternative-setup-setuid-sandbox 进行配置。若服务器的 Chrome 目录下包含了 chrome-sandbox 文件,则可以直接修改配置运行,若不包含,可前往 https://download-chromium.appspot.com/ 下载对应版本的 chrome-sandbox 文件使用。(注:Chrome 可执行文件的同一目录内包含 chrome-sandbox 程序,则无需手动设置 CHROME_DEVEL_SANDBOX 环境变量)
方案3、客户端选择系统默认浏览器打开外链URL
另外一个更加合适合理的设计是尽量避免使用应用内置的浏览器打开开放性URL页面。我们应该尽量使用系统的浏览器去打开非公司域名的URL链接(同时应该注意公司域名下的URL跳转风险);把打开URL的能力和场景交还给系统浏览器或专门的浏览器应用;保障应用内加载的资源都是可控的。
此方案同样适用于:客户端内置的Chromium Webview组件短时间内无法随系统快速更新,且由于历史包袱无法Webview组件无法开启沙箱。此时,在客户端引入一个“降级”逻辑,将不可信的页面跳转交给系统默认的浏览器打开。由于系统默认的浏览器通常默认是打开沙箱的,因此不失为一种“缓兵之计”。
4.2.2 云原生时代下,针对Chrome组件容器化的风险修复指引
业界云原生实践的发展非常迅速,企业应用容器化、组件容器化的脚步也势不可挡。从当前的Kubernetes应用设计的角度出发,Chrome Headless组件在逻辑上是非常适用于无状态应用的设计的,所以Chrome组件在容器化的进程也比较快。也因此,在HIDS进程大盘中, 启用 —no-sandbox 的 Chrome headless 进程也一直在持续增多。
如果 Chrome 浏览器组件已经实现了容器化,那么您想使用 Chrome sandbox 肯定会遇到各种麻烦;网络上有很多不完全安全的建议和文档,请尽量不要给容器添加 privileged 权限和 SYS_ADMIN 权限,这将可能引入新的风险,详情可参考我们之前的文章《红蓝对抗中的云原生漏洞挖掘及利用实录》。
我们应该尽量使用例如 —security-opt 的方案对容器权限进行可控范围内的限制,构建一个 Seccomp 白名单用于更安全的支持容器场景,这是一个足够优雅且较为通用的方式。如果企业已经践行了K8s容器集群安全管理的规范和能力,在集群内新建带有privileged 权限或 SYS_ADMIN 权限的应用容器是会被集群管理员明确拒绝的,Seccomp是一个安全且可管理的方案。
你可以参考下述方式启动一个带有 seccomp 配置的容器:
docker run -it —security-opt seccomp:./chrome.json chrome-sandbox-hub-image-near —headless —dump-dom https://github.com/neargle
实际上seccomp配置文件规定了一个可管理的syscall白名单,我们的配置文件就是需要把Sandbox所需的系统权限用白名单方式赋予给容器,使得容器可以调用多个原本默认禁止的 syscall。可以使用下列命令来检测当前的操作系统是否支持 seccomp:
➜ grep CONFIG_SECCOMP= /boot/config-$(uname -r)
CONFIG_SECCOMP=y
如果你的容器使用K8s进行部署,那你可以在 spec.securityContext.seccompProfile 中配置上述 chrome.json 文件。
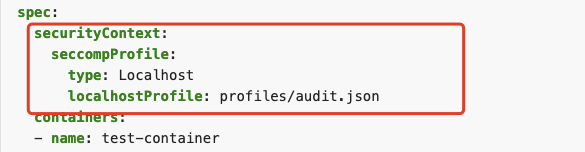
通过白名单设置 Chrome 所需的 syscall 以最小化容器权限,避免容器逃逸的风险,同时也符合多租户容器集群的安全设计,是一个推荐的方案;设置 Seccomp 后,容器内可正常启用 chrome-sandbox,如下图。

根据在HIDS收集到的资产和内部操作系统的特性,可以利用 strace 工具很容易收集到启动 Sandbox 所需的 SysCall,并根据 SysCall 编写所需的 seccomp 配置文件。当然直接使用开源社区里现成的配置文件也能适用于绝大部分环境,著名前端测试工具 lighthouse 所用的配置文件是一个非常不错的参考:https://github.com/GoogleChrome/lighthouse-ci/blob/main/docs/recipes/docker-client/seccomp-chrome.json。
V. 总结
随着Chromium在企业各场景下的广泛应用,需要针对性地设置风险例行检测及应急响应方案,涉及的风险与应用场景、检查及修复方式,可概括如下:
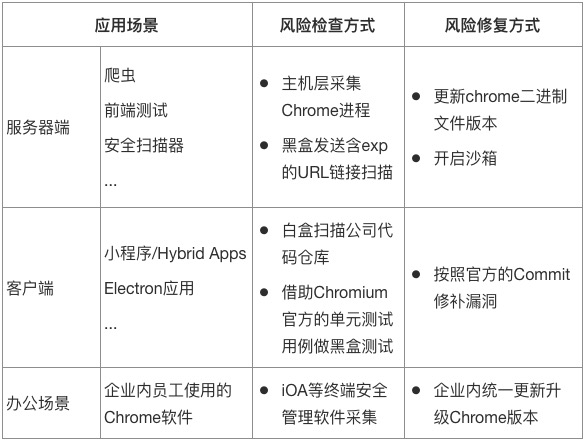
除Chromium外,企业开发时也不乏会涉及到Safari、Firefox等其他浏览器类组件的场景,在进行风险排查和响应时可借鉴类似的思路。
参考及引用
[1] Linux Sandboxing
https://chromium.googlesource.com/chromium/src/+/HEAD/docs/linux/sandboxing.md
[2] The Security Architecture of the Chromium Browser
https://seclab.stanford.edu/websec/chromium/chromium-security-architecture.pdf
[3] My Take on Chrome Sandbox Escape Exploit Chain
https://medium.com/swlh/my-take-on-chrome-sandbox-escape-exploit-chain-dbf5a616eec5
[4] Linux SUID Sandbox
https://chromium.googlesource.com/chromium/src/+/HEAD/docs/linux/suid_sandbox.md
[5] How Blink Works
https://docs.google.com/document/d/1aitSOucL0VHZa9Z2vbRJSyAIsAz24kX8LFByQ5xQnUg/edit
[6] Chrome浏览器引擎 Blink & V8
https://zhuanlan.zhihu.com/p/279920830
[7] Blink-in-JavaScript
https://docs.google.com/presentation/d/1XvZdAF29Fgn19GCjDhHhlsECJAfOR49tpUFWrbtQAwU/htmlpresent
[8] core/script: How a Script Element Works in Blink
https://docs.google.com/presentation/d/1H-1U9LmCghOmviw0nYE_SP_r49-bU42SkViBn539-vg/edit#slide=id.gc6f73
[9] [TPSA21-12] 关于Chrome存在安全问题可能影响Windows版本微信的通告
https://mp.weixin.qq.com/s/qAnxwM1Udulj1K3Wn2awVQ
[10] Hacking Team Android Browser Exploit代码分析
https://security.tencent.com/index.php/blog/msg/87
[11] 物联网安全系列之远程破解Google Home
https://security.tencent.com/index.php/blog/msg/141
[12] Android Webview UXSS 漏洞攻防
https://security.tencent.com/index.php/blog/msg/70


