VirtualBox的虚拟机在操作时,需要点击菜单栏和任务栏,但有时候我们会出现无法显示的问题。
分类: Linux
Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户、多任务、支持多线程和多CPU的操作系统。它能运行主要的UNIX工具软件、应用程序和网络协议。它支持32位和64位硬件。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。它主要用于基于Intel x86系列CPU的计算机上。这个系统是由全世界各地的成千上万的程序员设计和实现的。其目的是建立不受任何商品化软件的版权制约的、全世界都能自由使用的Unix兼容产品。
openKylin v2.0 SP2默认模式不能安装软件包的问题
最近在尝试使用国产的 openKylin ,结果在安装软件包的时候报错"当前模式禁止执行(unpack)操作",如下图:
当笔记本电脑盖子关闭时如何禁用指纹认证(ubuntu 24.04)?
To disable fingerprint authentication when the laptop lid is closed, and re-enable when it is reopened, we will use acpid to bind to the button/lid.* event to a custom script that will stop and mask the fprintd service on lid close, and unmask and start the fprintd service on lid open.
We also check that the HDMI cable is connected by testing the contents of /sys/class/drm/card1-HDMI-A-1/status.
Follow the steps below: (ThinkPad T440 ubunu 24.04)
-
Create file /etc/acpi/laptop-lid.sh with the following contents:
1234567$ sudo install acpid$ sudo mkdir /etc/acpi$ sudo install vim$ sudo vim /etc/acpi/laptop-lid.sh12345678910111213141516#!/bin/bashlock=$HOME/.fprint-disabledif grep -Fq closed /proc/acpi/button/lid/LID/state &&grep -Fxq connected /sys/class/drm/card1-HDMI-A-1/statusthentouch "$lock"systemctl mask fprintdsystemctl stop fprintdelif [ -f "$lock" ]thensystemctl unmask fprintdsystemctl start fprintdrm "$lock"fi -
Make the file executable with
1$ sudo chmod +x /etc/acpi/laptop-lid.sh -
Create file /etc/acpi/events/laptop-lid with the following contents:
1$ sudo mkdir /etc/acpi/events12event=button/lid.*action=/etc/acpi/laptop-lid.sh -
Restart the acpid service with:
1$ sudo service acpid restart
Now the fingerprint will be used only when the lid is open.
In order to restore the correct state of the fprintd service if you disconnect/reconnect while the laptop is off, you may call the above script from a systemd init file. The steps to do this are the following:
-
Create a file named /etc/systemd/system/laptop-lid.service with the following contents:
12345678910[Unit]Description=Laptop LidAfter=suspend.target[Service]ExecStart=/etc/acpi/laptop-lid.sh[Install]WantedBy=multi-user.targetWantedBy=suspend.target -
Reload the systemd config files with
1$ sudo systemctl daemon-reload -
Start the service with
1$ sudo systemctl start laptop-lid.service -
Enable the service so that it starts automatically on boot
1$ sudo systemctl enable laptop-lid.serviceNow the status should be correct even after connecting/disconnecting when the computer is off.
References used for creating the code in the answer:
参考链接
Flutter调试Linux平台代码(VSCode)
Flutter 开发过程中,需要编写调试 Linux 平台相关的代码,下面介绍一下使用 VSCode 进行调试的相关配置。
在工程根目录下的 launch.json 中增加如下配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "name": "Debug native", "type": "cppdbg", "request": "launch", "program": "${workspaceFolder}/build/linux/arm64/debug/bundle/MyApp", // Path to your compiled Flutter Linux executable "args": [], "stopAtEntry": false, "cwd": "${workspaceFolder}", "environment": [], "externalConsole": false, "MIMode": "gdb", "setupCommands": [ { "description": "Enable pretty-printing for gdb", "text": "-enable-pretty-printing", "ignoreFailures": true } ] }, |
注意 "program": "${workspaceFolder}/build/linux/arm64/debug/bundle/MyApp", // Path to your compiled Flutter Linux executable 根据项目的实际情况进行配置,主要需要修改的地方就是路径中的 arm64 或者 x64 以及最后的应用名。
完整的配置如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ // 使用 IntelliSense 了解相关属性。 // 悬停以查看现有属性的描述。 // 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Debug native", "type": "cppdbg", "request": "launch", "program": "${workspaceFolder}/build/linux/arm64/debug/bundle/MyApp", // Path to your compiled Flutter Linux executable "args": [], "stopAtEntry": false, "cwd": "${workspaceFolder}", "environment": [], "externalConsole": false, "MIMode": "gdb", "setupCommands": [ { "description": "Enable pretty-printing for gdb", "text": "-enable-pretty-printing", "ignoreFailures": true } ] }, ] } |
调试的时候,参考下图进行选择,选择的配置项目就是 "name": "Debug native",如下图:
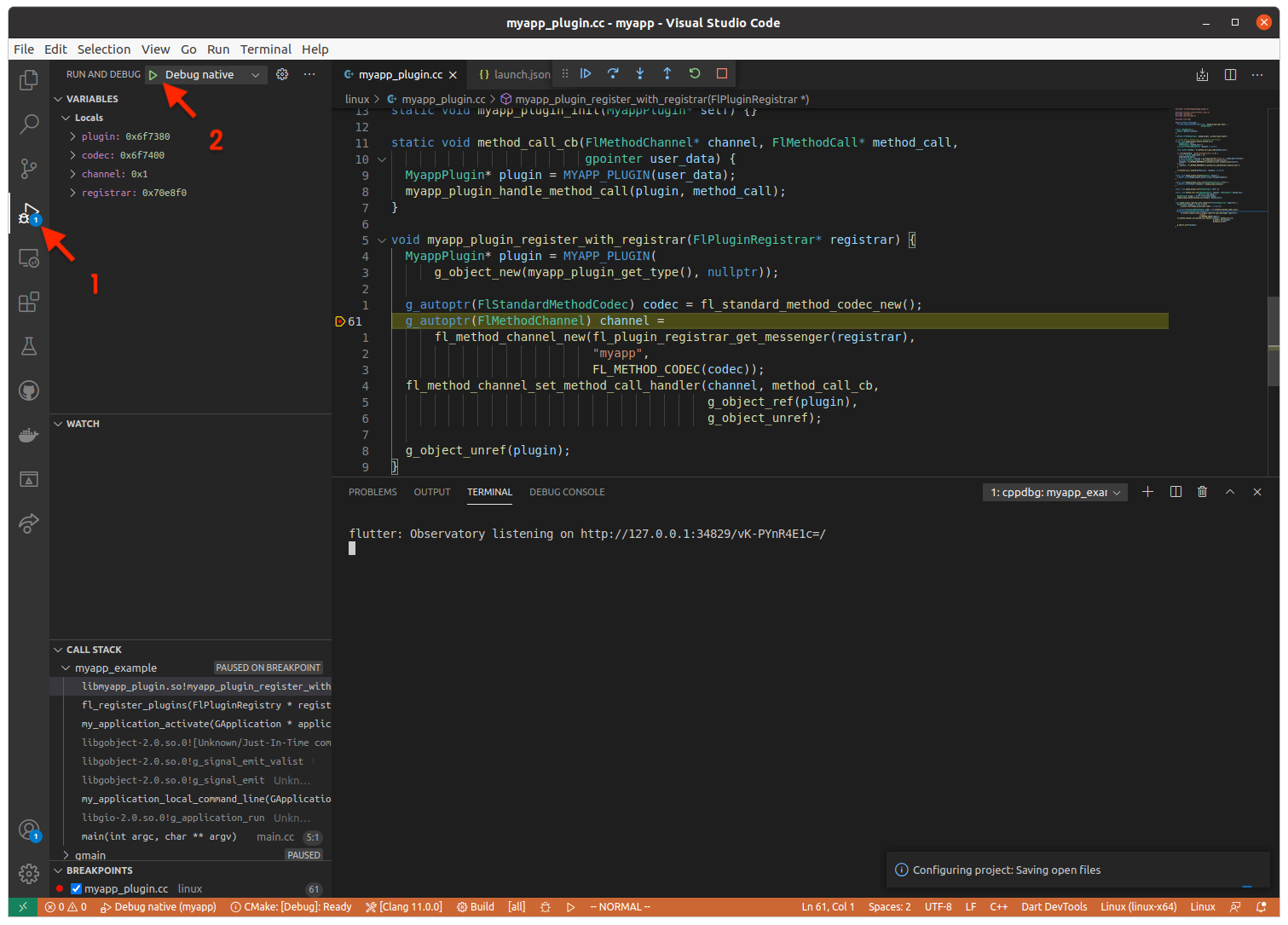
参考链接
Gtk应用内嵌网页与原生代码交互方法
前置条件
- Ubuntu 24.04.2 LTS
内容详情
在使用Gtk开发应用程序的过程中,如果需要内嵌网页,那么使用libwebkit2gtk是个非常自然和正确的选择。
那么这里就可能原生程序代码可能需要跟网页交互的问题。
Gtk程序跟网页的交互,主要有两个方面:
|
1 2 3 |
1 Gtk程序需要调用网页js代码 2 网页需要调用 Gtk 程序的功能代码 |
需求1,使用 webkit2gtk 的内置 webkit_web_view_run_javascript 函数即可解决
需求2,使用 webkit2gtk 的内置的 web extendsion 扩展支持功能解决 或 window.webkit.messageHandlers..postMessage(value)
不多说看代码吧!
Gtk嵌入网页Demo程序
webviewgtk.c
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 |
/** * * Copyright (C) 2020 Wei Keting<weikting@gmail.com>. All rights reserved. * @Time : 2021-04-04 12:18 * @Last Modified: 2022-12-10 17:27 * @File : webviewgtk.c * @Description : * * 依赖下载: * sudo apt install libwebkit2gtk-4.1-doc libwebkit2gtk-4.1-dev libgtk-3-dev * gcc webviewgtk.c -o webviewgtk -D_GNU_SOURCE -g3 -Wall `pkg-config --cflags --libs webkit2gtk-4.1` * */ #include <gtk/gtk.h> #include <glib.h> #include <webkit2/webkit2.h> #include <sys/types.h> #include <unistd.h> static void web_view_javascript_finished(GObject *object, GAsyncResult *result, gpointer user_data) { GError *error = NULL; JSCValue *js_result = webkit_web_view_evaluate_javascript_finish(WEBKIT_WEB_VIEW(object), result, &error); if (!js_result) { g_warning("Error running javascript: %s", error->message); g_error_free(error); return; } if (jsc_value_is_string(js_result)) { gchar *str_value = jsc_value_to_string(js_result); JSCException *exception = jsc_context_get_exception(jsc_value_get_context(js_result)); if (exception) g_warning("Error running javascript: %s", jsc_exception_get_message(exception)); else g_print("Script result: %s\n", str_value); g_free(str_value); } else { g_warning("Error running javascript: unexpected return value"); } } static gboolean on_webview_load_failed(WebKitWebView *webview, WebKitLoadEvent load_event, gchar *failing_uri, GError *error, gpointer user_data) { g_printerr("%s: %s\n", failing_uri, error->message); return FALSE; } static void handle_script_message(WebKitUserContentManager *self, WebKitJavascriptResult *js_result, gpointer user_data) { JSCValue *value = webkit_javascript_result_get_js_value(js_result); gchar *str_value = jsc_value_to_string(value); JSCException *exception = jsc_context_get_exception(jsc_value_get_context(value)); if (exception) g_warning("Error running javascript: %s", jsc_exception_get_message(exception)); else g_printerr("Script result: %s\n", str_value); g_printerr("%s: %s\n", __func__, str_value); g_free(str_value); } static gboolean handle_script_message_with_reply(WebKitUserContentManager *self, JSCValue *value, WebKitScriptMessageReply *reply, gpointer user_data) { gchar *str_value = jsc_value_to_string(value); JSCContext *context = jsc_value_get_context(value); /* It is possible to handle the reply asynchronously, * by simply calling g_object_ref() on the reply and returning TRUE. * webkit_script_message_reply_ref(reply); * * async code here * * webkit_script_message_reply_unref(reply); */ JSCValue *js_value = jsc_value_new_string(context, str_value); webkit_script_message_reply_return_value(reply, js_value); g_printerr("%s: %s\n", __func__, str_value); g_free(str_value); return TRUE; // TRUE to stop other handlers from being invoked for the event. FALSE to propagate the event further. } static void on_button_clicked(GtkButton *button, WebKitWebView *webview) { static gint t = 0; gchar buf[128] = {0}; g_snprintf(buf, sizeof(buf) - 1, "change_span_id('_n%d')", t); t += 1; // 在webview当前的html页面中直接运行js代码 webkit_web_view_evaluate_javascript(webview, buf, -1, NULL, NULL, NULL, web_view_javascript_finished, NULL); } static void webkit_web_extension_initialize(WebKitWebContext *context, gpointer user_data) { g_printerr("%s: %d\n", __FUNCTION__, getpid()); // 设置web extendsion扩张.so文件的搜索目录 webkit_web_context_set_web_extensions_directory(context, "."); } /** ** 创建window,添加webkit控件 ** **/ static void on_activate(GtkApplication *app) { g_assert(GTK_IS_APPLICATION(app)); GtkWindow *window = gtk_application_get_active_window(app); if (window == NULL) window = g_object_new(GTK_TYPE_WINDOW, "application", app, "default-width", 600, "default-height", 300, NULL); // 注册处理web extensions的初始化函数 g_signal_connect(webkit_web_context_get_default(), "initialize-web-extensions", G_CALLBACK(webkit_web_extension_initialize), NULL); GtkWidget *webview = webkit_web_view_new(); g_signal_connect(webview, "load-failed", G_CALLBACK(on_webview_load_failed), NULL); // 加载网页 GFile *file = g_file_new_for_path("webview.html"); gchar *uri = g_file_get_uri(file); webkit_web_view_load_uri(WEBKIT_WEB_VIEW(webview), uri); g_free(uri); g_object_unref(file); // 注册 window.webkit.messageHandlers.msgToNative.postMessage(value) 的回调函数 WebKitUserContentManager *manager = webkit_web_view_get_user_content_manager( WEBKIT_WEB_VIEW(webview)); g_signal_connect(manager, "script-message-received::msgToNative", G_CALLBACK(handle_script_message), NULL); webkit_user_content_manager_register_script_message_handler(manager, "msgToNative"); // 注册 window.webkit.messageHandlers.msgToNativeReply.postMessage(value) 的回调函数 // 函数调用有返回值 g_signal_connect(manager, "script-message-with-reply-received::msgToNativeReply", G_CALLBACK(handle_script_message_with_reply), NULL); webkit_user_content_manager_register_script_message_handler_with_reply(manager, "msgToNativeReply", NULL); /* Enable the developer extras */ WebKitSettings *setting = webkit_web_view_get_settings(WEBKIT_WEB_VIEW(webview)); g_object_set(G_OBJECT(settings), "enable-developer-extras", TRUE, NULL); GtkWidget *vbox = gtk_box_new(GTK_ORIENTATION_VERTICAL, 0); GtkWidget *button = gtk_button_new_with_label("change span"); gtk_box_pack_start(GTK_BOX(vbox), GTK_WIDGET(webview), TRUE, TRUE, 0); gtk_box_pack_start(GTK_BOX(vbox), GTK_WIDGET(button), FALSE, TRUE, 0); gtk_container_add(GTK_CONTAINER(window), GTK_WIDGET(vbox)); gtk_widget_show_all(GTK_WIDGET(vbox)); gtk_window_present(window); g_signal_connect(button, "clicked", G_CALLBACK(on_button_clicked), webview); } int main(int argc, char *argv[]) { g_autoptr(GtkApplication) app = gtk_application_new("com.weiketing.webkit_webview", G_APPLICATION_DEFAULT_FLAGS); g_signal_connect(app, "activate", G_CALLBACK(on_activate), NULL); return g_application_run(G_APPLICATION(app), argc, argv); } |
Web Extension Demo
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
/** * * Copyright (C) 2020 Wei Keting<weikting@gmail.com>. All rights reserved. * @Time : 2021-04-04 12:18 * @File : web_exten.c * @Description : * * 依赖下载: * sudo apt install libwebkit2gtk-4.1-doc libwebkit2gtk-4.1-dev libgtk-3-dev * gcc web_exten.c -o libweb_exten.so -shared -Wl,-soname,libweb_exten.so -D_GNU_SOURCE -g3 -Wall `pkg-config --cflags --libs webkit2gtk-4.1` **/ #include <glib.h> #include <webkit2/webkit-web-extension.h> #include <sys/types.h> #include <unistd.h> static gint js_app_add(gpointer *first, gint num) { static gint N = 0; g_printerr("%s: %p\n", __FUNCTION__, first); N += num; return N; } static void window_object_cleared_callback(WebKitScriptWorld *world, WebKitWebPage *web_page, WebKitFrame *frame, gpointer user_data) { JSCContext *jsContext; jsContext = webkit_frame_get_js_context_for_script_world(frame, world); //添加一个js全局变量gtkValue jsc_context_set_value(jsContext, "gtkValue", jsc_value_new_string(jsContext, "__test_js_exten")); /* Use JSC API to add the JavaScript code you want */ //注册一个名为NativeTest的js类 JSCClass *app = jsc_context_register_class(jsContext, "NativeTest", NULL, NULL, NULL); // g_object_new(JSC_TYPE_CLASS, "name", "JSApp", "context", jsContext, NULL); //给JSCClass类添加add方法 jsc_class_add_method(app, "add", G_CALLBACK(js_app_add), NULL, NULL, G_TYPE_INT, 1, G_TYPE_INT, NULL); //创建一个obj,作为JSCClass类绑定实例,JSCClass方法回调的第一个参数就是obj GObject *obj = g_object_new(G_TYPE_OBJECT, NULL); jsc_context_set_value(jsContext, "GtkNative", jsc_value_new_object(jsContext, obj, app)); g_printerr("%s: %d %p\n", __FUNCTION__, getpid(), obj); g_object_unref(obj); } G_MODULE_EXPORT void webkit_web_extension_initialize(WebKitWebExtension *extension) { //web extension的初始化函数 g_signal_connect(webkit_script_world_get_default(), "window-object-cleared", G_CALLBACK(window_object_cleared_callback), NULL); } |
内嵌的网页示例 webview.html
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
<!DOCTYPE html> <html lang="zh"> <!--filename: webview.html --> <head> <meta charset="utf-8" /> <meta http-equiv="Content-Language" content="zh-CN"> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" /> <meta name="referrer" content="always" /> <title>Webkit Webview test</title> <script type="text/javascript"> function change_span_id(v = '') { //alert("test") document.getElementById('span_id').innerHTML = 'test' + v + gtkValue return v } function native_add(num) { //调用自定义添加的js接口 i = GtkNative.add(num) document.getElementById('add').innerHTML = i } function send2Gtk() { e = document.getElementById('msg') window.webkit.messageHandlers.msgToNative.postMessage(e.value) } async function send2GtkReply() { e = document.getElementById('msgReply') // 调用自定义添加的js接口,并获取返回值 res = await window.webkit.messageHandlers.msgToNativeReply.postMessage(e.value) document.getElementById('span_id').innerHTML = res } </script> </head> <body> <span>words for test: </span><span id="span_id"></span> <br /> <button onclick="change_span_id()">change span id</button> <br /> <span>Native add: </span><span id='add'></span> <br /> <button onclick="native_add(2)">Native Add</button> <br /> <input type="text" id="msg" /> <br /> <button onclick="send2Gtk()">Send to Native</button> <br /> <input type="text" id="msgReply" /> <br /> <button onclick="send2GtkReply()">Send to Native Wait Reply</button> </body> </html> |
示例运行
安装依赖:
|
1 |
$ sudo apt install libwebkit2gtk-4.1-doc libwebkit2gtk-4.1-dev libgtk-3-dev |
把webviewgtk.c,web_exten.c,webview.html 放在同一目录下。
编译程序:
|
1 2 3 |
$ gcc web_exten.c -o libweb_exten.so -shared -Wl,-soname,libweb_exten.so -D_GNU_SOURCE -g3 -Wall `pkg-config --cflags --libs webkit2gtk-4.1` $ gcc webviewgtk.c -o webviewgtk -D_GNU_SOURCE -g3 -Wall `pkg-config --cflags --libs webkit2gtk-4.1` |
运行程序:
|
1 |
$ ./webviewgtk |
参考链接
- Gtk应用内嵌网页与原生代码交互方法
- 在WebKitGTK 中扩展JS
- WebKit2 > UserContentManager > register_script_message_handler_with_reply
- Integrating WPE: URI Scheme Handlers and Script Messages
- How does the iOS 14 API WKScriptMessageHandlerWithReply work for communicating with JavaScript from iOS?
- webkit2gtk的自定义协议与内容交互
- WebKitWebInspector
应用内嵌WebKitGTK报错“Unacceptable TLS certificate”
在 ubuntu 24.04 系统开发内嵌 webkit2gtk-4.1 的应用,打开部分 HTTPS 网页报错“Unacceptable TLS certificate”, 如下图:
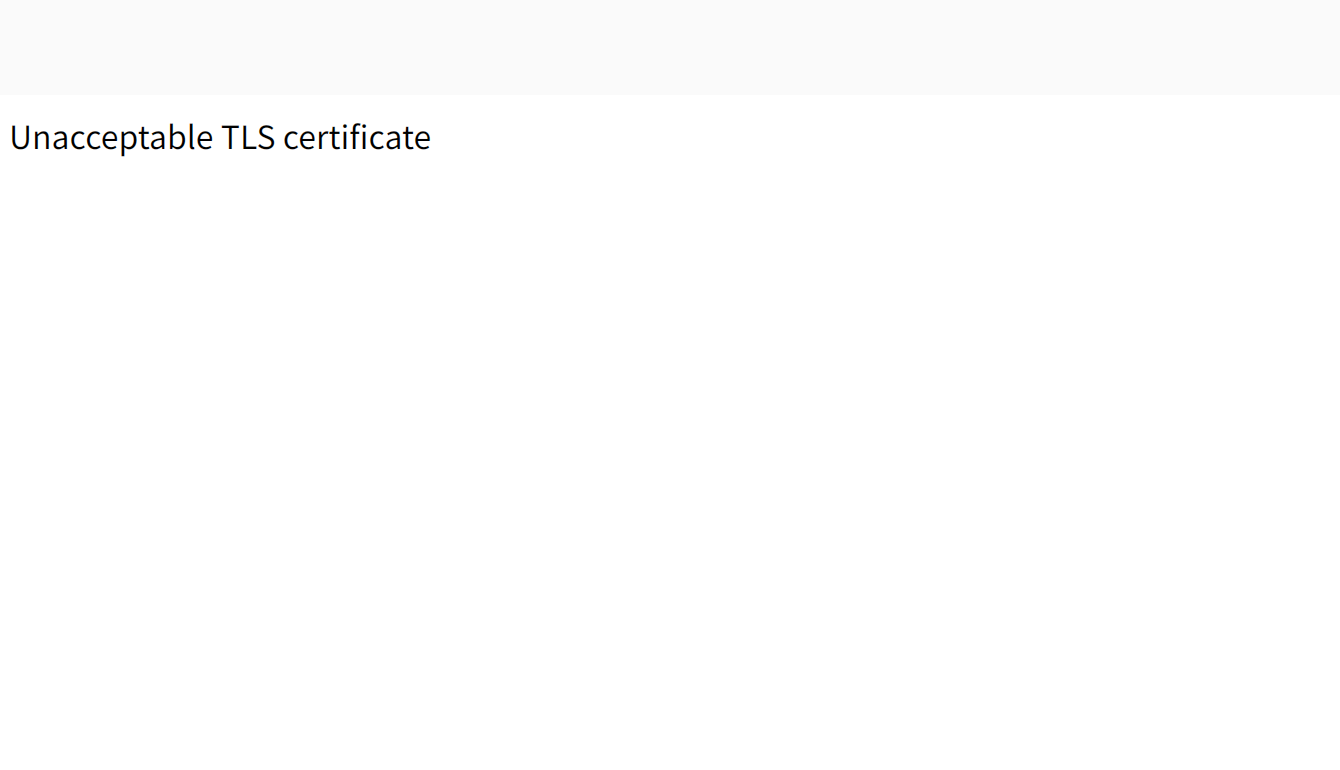
但是相同的页面使用 FireFox/Safari/Chrome/IE/Edge 等主流浏览器打开都是正常显示的。
调试代码,发现是 WebKitWebView 的 on_load_failed_with_tls_errors 回调函数返回了错误 G_TLS_CERTIFICATE_GENERIC_ERROR(64),如下图:
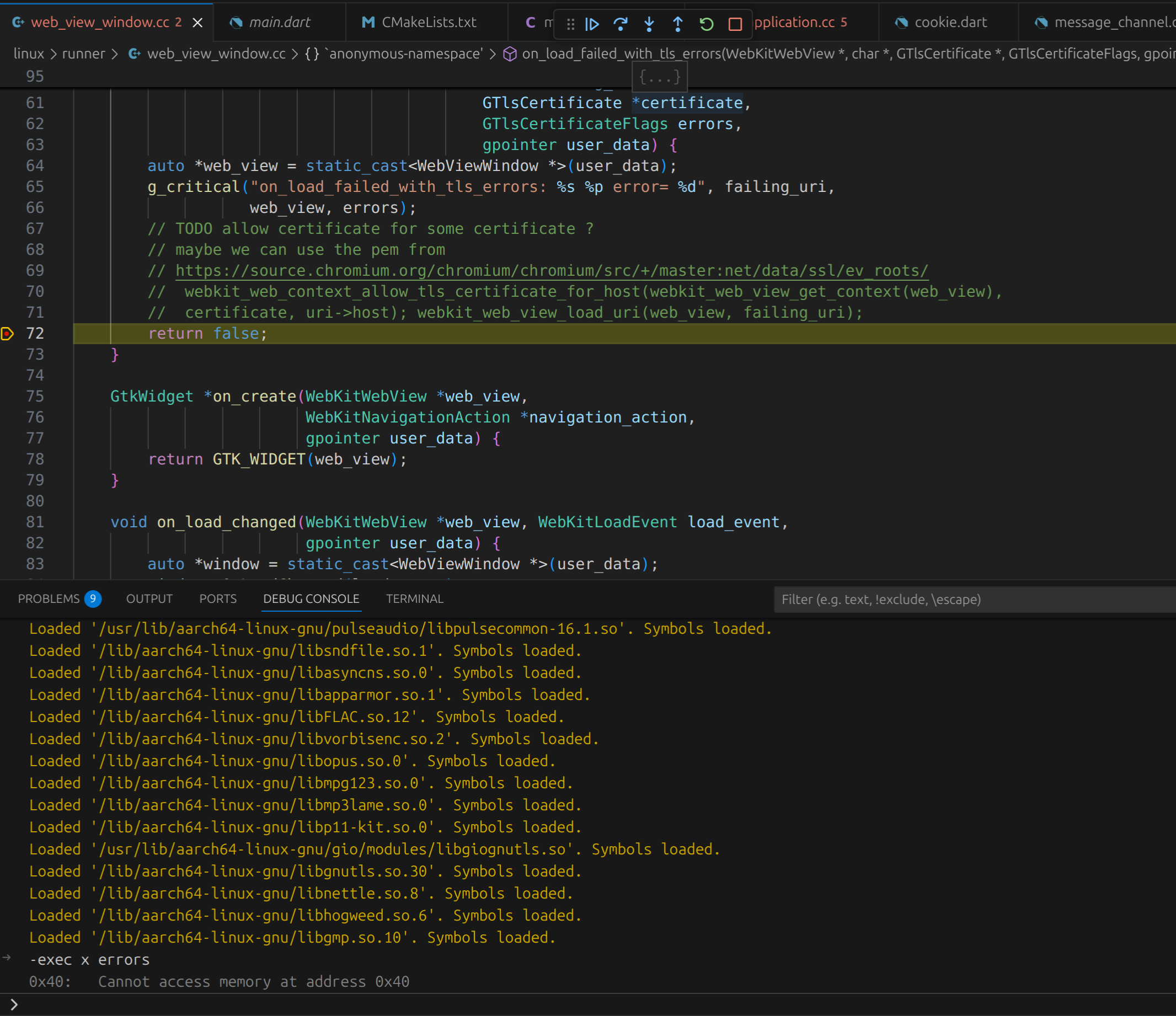
于是安装 Gnome 官方的浏览器 Epiphany 进行测试,该浏览器底层也是调用 WebKit2GTK,在 ubuntu 24.04 系统,可以执行如下命令进行安装:
|
1 |
$ sudo apt install epiphany-browser |
打开相同的页面,同样报错,显示服务器不可信。
由于 WebKit2GTK 底层的 TLS 通信调用库调用的是 GnuTLS 。于是尝试通过命令行对 TLS 证书认证过程进行验证,执行如下命令:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ sudo apt install gnutls-bin $ gnutls-cli www.xxxx.com Processed 146 CA certificate(s). Resolving 'www.xxxx.com:443'... Connecting to 'xxx.xxx.xxx.xxx:443'... ........................................................................ ........................................................................ - Certificate[4] info: - subject `CN=Baltimore CyberTrust Root,OU=CyberTrust,O=Baltimore,C=IE', issuer `CN=Baltimore CyberTrust Root,OU=CyberTrust,O=Baltimore,C=IE', serial xxxxxx, RSA key 2048 bits, signed using RSA-SHA1 (broken!), activated `xxxx-xx-xx xx:xx:xx UTC', expires `xxxx-xx-xx xx:xx:xx UTC', pin-sha256="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" - Status: The certificate is NOT trusted. The certificate chain violates the signer's constraints. *** PKI verification of server certificate failed... *** Fatal error: Error in the certificate. |
可以看到,网站的根证书无法通过 GnuTLS 的验证,原因在于网站的证书链中的根证书使用的 RSA-SHA1 签名,该类型签名存在 “弱哈希算法签名的SSL证书(CVE-2004-2761)漏洞” 进而被 GnuTLS 拒绝。
针对此问题的更详细的描述参考 GnuTLS 文档 8.2 Disabling algorithms and protocols 。
针对此问题的解决方法:
-
联系网站,更新证书,重新以 RSA-SHA256 签发证书。由于是公司内部网址,因此联系网络更新即可;
-
应用内嵌网站证书,通过 webkit_web_context_allow_tls_certificate_for_host 要求 webkit 通过提供的证书进行网站验证。此种情况适用于 APP 内嵌自己网站页面的情况,同样适用于自签名证书的情况;
-
如果纯粹测试,可以在加载页面之前调用
123456789// 网站证书存在问题,此处仅为测试场景下,临时关闭TLS证书验证auto context = webkit_web_view_get_context(WEBKIT_WEB_VIEW(web_view_));// 低版本 4.0webkit_web_context_set_tls_errors_policy(context, WEBKIT_TLS_ERRORS_POLICY_IGNORE);// 高版本 4.1auto manager = webkit_web_context_get_website_data_manager(context);webkit_website_data_manager_set_tls_errors_policy(manager, WEBKIT_TLS_ERRORS_POLICY_IGNORE);要求 webkit 无视证书错误。此方法生产环境不可取,非常不安全,仅可用于内部测试;
-
此方案目前测试已经不可用:
调用 gnutls_sign_set_secure_for_certs API 许可部分不安全的证书签名算法123456// pkg_check_modules(GnuTLS REQUIRED IMPORTED_TARGET gnutls>=3.7.3)// target_link_libraries(${BINARY_NAME} PRIVATE PkgConfig::GnuTLS)// #include <gnutls/gnutls.h>gnutls_sign_set_secure_for_certs(GNUTLS_SIGN_RSA_SHA1, 1);相对来说,联系不上网站的情况下,又需要在保证安全的前提下,尽量兼容网站,推荐此种方式; -
自行接管证书验证过程,实现比较复杂,极其容易产生安全漏洞,不建议;
参考链接
mdadm软Raid1升级容量
2块12TB做了软RAID1,需要升级成2块16TB盘
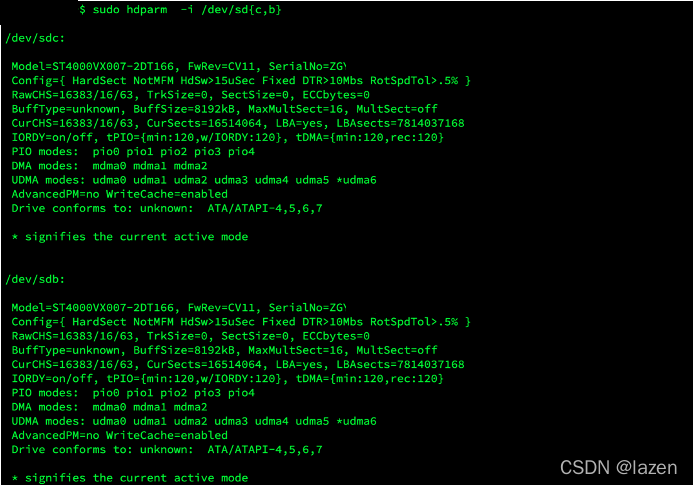
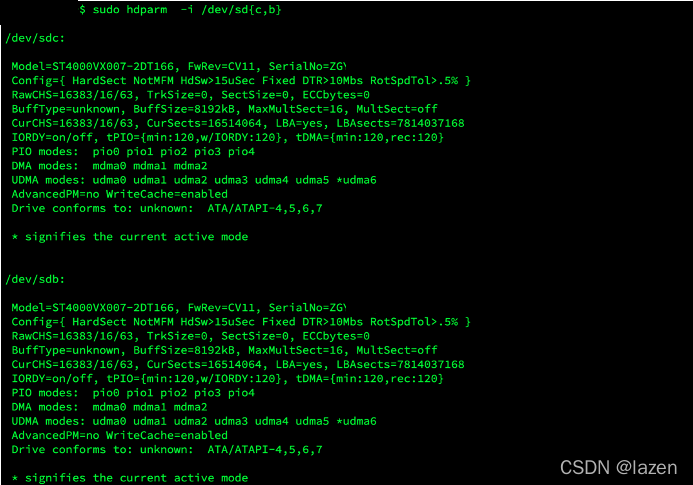
1. 查看磁盘信息,SerialNumber 等会儿会用到,防止换错盘
|
1 |
$ sudo hdparm -i /dev/sd{c,b} |
2. 运行 sync 命令刷写
3. 查看 md 状态
|
1 |
$ sudo hdparm -i /dev/sd{c,b} |
4. 查看 md 容量
|
1 2 3 |
$ df -h | grep md $ mdadm --detail /dev/md127 |
剔除磁盘 /dev/sdc
|
1 |
$ sudo mdadm --manage /dev/md127 --fail /dev/sdc |

5. 关机换盘(支持热插拔的可以开机更换)
6. 更换硬盘后加回硬盘
lsblk查看换回来的设备名称
由于是原位置更换,盘的名称还是 /dev/sdc
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# cat /proc/sys/dev/raid/speed_limit_max # 200000 # cat /proc/sys/dev/raid/speed_limit_min # 1000 # 临时修改 raid 的同步速度限制,默认限制最低 1KB/S(1000) 同步速度太慢了,我们把这个速度限制放宽到 最低200MB/S,最高 400MB/S 。同步完成后再改回来即可,或者重启系统即可恢复成默认设置 $ sudo sysctl -w dev.raid.speed_limit_min=200000 $ sudo sysctl -w dev.raid.speed_limit_max=400000 $ sudo mdadm --manage /dev/md127 --add /dev/sdc $ cat /proc/mdstat |


7. 等待同步完成后,依照第一块盘的方式,更换掉第二块盘再次等待同步完成。
8. mdadm 扩容
|
1 |
$ sudo mdadm --grow --size max /dev/mdxx |
文件系统扩容
|
1 2 3 4 5 6 7 |
$ sudo parted /dev/md127 "resizepart 1 100%" # resize2fs 只能处理 ext4/ext3/ext2 # 如果是xfs需要使用 xfs_grows # 如果是btrfs 则需要执行 btrfs 命令 $ sudo resize2fs /dev/md127p1 ( 这里我只分了一个分区,ext4格式) |
如果上述命令报错
|
1 2 3 4 5 |
$ sudo LANG=C resize2fs /dev/md1 resize2fs 1.47.0 (5-Feb-2023) resize2fs: Device or resource busy while trying to open /dev/md1 Couldn't find valid filesystem superblock. |
则执行如下命令,观察一下是否分区是 LVM分区格式
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS ............................................................. sda 8:0 0 14.6T 0 disk └─sda1 8:1 0 14.6T 0 part └─md1 9:1 0 10.9T 0 raid1 └─vg0-volume_0 252:0 0 10.9T 0 lvm /home/data ............................................................... sdd 8:48 0 14.6T 0 disk └─sdd1 8:49 0 14.6T 0 part ............................................................... |
并且检查文件系统是 btrfs 格式,如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ df -Th 文件系统 类型 大小 已用 可用 已用% 挂载点 tmpfs tmpfs 1.6G 4.8M 1.6G 1% /run /dev/sde3 ext4 219G 105G 103G 51% / tmpfs tmpfs 7.8G 336K 7.8G 1% /dev/shm tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs tmpfs 7.8G 0 7.8G 0% /run/qemu /dev/sde2 vfat 512M 6.2M 506M 2% /boot/efi /dev/mapper/vg0-volume_0 btrfs 11T 11T 707G 94% /home/data tmpfs tmpfs 1.6G 204K 1.6G 1% /run/user/1001 tmpfs tmpfs 1.6G 144K 1.6G 1% /run/user/128 tmpfs tmpfs 1.6G 132K 1.6G 1% /run/user/1000 |
如果类似上述情况,需要额外执行如下命令:
|
1 |
$ sudo mdadm --grow --size max /dev/md1 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS ............................................................. sda 8:0 0 14.6T 0 disk └─sda1 8:1 0 14.6T 0 part └─md1 9:1 0 14.6T 0 raid1 └─vg0-volume_0 252:0 0 10.9T 0 lvm /home/data ............................................................... sdd 8:48 0 14.6T 0 disk └─sdd1 8:49 0 14.6T 0 part ............................................................... |
|
1 2 3 |
$ sudo pvresize /dev/md1 $ sudo lvextend -l +100%FREE /dev/mapper/vg0-volume_0 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS ............................................................. sda 8:0 0 14.6T 0 disk └─sda1 8:1 0 14.6T 0 part └─md1 9:1 0 14.6T 0 raid1 └─vg0-volume_0 252:0 0 14.6T 0 lvm /home/data ............................................................... sdd 8:48 0 14.6T 0 disk └─sdd1 8:49 0 14.6T 0 part ............................................................... |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ df -Th 文件系统 类型 大小 已用 可用 已用% 挂载点 tmpfs tmpfs 1.6G 4.8M 1.6G 1% /run /dev/sde3 ext4 219G 105G 103G 51% / tmpfs tmpfs 7.8G 336K 7.8G 1% /dev/shm tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs tmpfs 7.8G 0 7.8G 0% /run/qemu /dev/sde2 vfat 512M 6.2M 506M 2% /boot/efi /dev/mapper/vg0-volume_0 btrfs 11T 11T 707G 94% /home/data tmpfs tmpfs 1.6G 204K 1.6G 1% /run/user/1001 tmpfs tmpfs 1.6G 144K 1.6G 1% /run/user/128 tmpfs tmpfs 1.6G 132K 1.6G 1% /run/user/1000 |
|
1 2 3 4 |
$ sudo apt install btrfs-progs $ sudo btrfs filesystem resize max /home/data Resize device id 1 (/dev/mapper/vg0-volume_0) from 10.91TiB to max |
|
1 2 3 4 5 6 7 8 9 10 11 |
$ df -Th 文件系统 类型 大小 已用 可用 已用% 挂载点 tmpfs tmpfs 1.6G 5.1M 1.6G 1% /run /dev/sde3 ext4 219G 106G 102G 52% / tmpfs tmpfs 7.8G 336K 7.8G 1% /dev/shm tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock tmpfs tmpfs 7.8G 0 7.8G 0% /run/qemu /dev/sde2 vfat 512M 6.2M 506M 2% /boot/efi /dev/mapper/vg0-volume_0 btrfs 15T 11T 4.4T 71% /home/data tmpfs tmpfs 1.6G 304K 1.6G 1% /run/user/1001 tmpfs tmpfs 1.6G 180K 1.6G 1% /run/user/1000 |
删除新添加硬盘分区,并且添加新分区,保持与原磁盘一致:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 |
$ sudo gdisk /dev/sdd GPT fdisk (gdisk) version 1.0.10 Partition table scan: MBR: protective BSD: not present APM: not present GPT: present Found valid GPT with protective MBR; using GPT. Command (? for help): ? b back up GPT data to a file c change a partition's name d delete a partition i show detailed information on a partition l list known partition types n add a new partition o create a new empty GUID partition table (GPT) p print the partition table q quit without saving changes r recovery and transformation options (experts only) s sort partitions t change a partition's type code v verify disk w write table to disk and exit x extra functionality (experts only) ? print this menu Command (? for help): p Disk /dev/sdd: 31251759104 sectors, 14.6 TiB Model: WUH721816ALE6L4 Sector size (logical/physical): 512/4096 bytes Disk identifier (GUID): C37D08FC-C28D-401A-8EE9-8A4994A47A49 Partition table holds up to 128 entries Main partition table begins at sector 2 and ends at sector 33 First usable sector is 2048, last usable sector is 31251759070 Partitions will be aligned on 2048-sector boundaries Total free space is 0 sectors (0 bytes) Number Start (sector) End (sector) Size Code Name 1 2048 31251757055 14.6 TiB FD00 2 31251757056 31251759070 1007.5 KiB 8300 Linux filesystem Command (? for help): d 1 Partition number (1-2): 1 Command (? for help): d Using 2 Command (? for help): p Disk /dev/sdd: 31251759104 sectors, 14.6 TiB Model: WUH721816ALE6L4 Sector size (logical/physical): 512/4096 bytes Disk identifier (GUID): C37D08FC-C28D-401A-8EE9-8A4994A47A49 Partition table holds up to 128 entries Main partition table begins at sector 2 and ends at sector 33 First usable sector is 2048, last usable sector is 31251759070 Partitions will be aligned on 2048-sector boundaries Total free space is 31251757023 sectors (14.6 TiB) Number Start (sector) End (sector) Size Code Name Command (? for help): n Partition number (1-128, default 1): First sector (2048-31251759070, default = 2048) or {+-}size{KMGTP}: Last sector (2048-31251759070, default = 31251757055) or {+-}size{KMGTP}: Current type is 8300 (Linux filesystem) Hex code or GUID (L to show codes, Enter = 8300): Changed type of partition to 'Linux filesystem' Command (? for help): p Disk /dev/sdd: 31251759104 sectors, 14.6 TiB Model: WUH721816ALE6L4 Sector size (logical/physical): 512/4096 bytes Disk identifier (GUID): C37D08FC-C28D-401A-8EE9-8A4994A47A49 Partition table holds up to 128 entries Main partition table begins at sector 2 and ends at sector 33 First usable sector is 2048, last usable sector is 31251759070 Partitions will be aligned on 2048-sector boundaries Total free space is 2015 sectors (1007.5 KiB) Number Start (sector) End (sector) Size Code Name 1 2048 31251757055 14.6 TiB 8300 Linux filesystem Command (? for help): w Final checks complete. About to write GPT data. THIS WILL OVERWRITE EXISTING PARTITIONS!! Do you want to proceed? (Y/N): Y OK; writing new GUID partition table (GPT) to /dev/sdd. The operation has completed successfully. |
如果后续添加磁盘的时候报错:
|
1 2 |
$ sudo mdadm --manage /dev/md1 --add /dev/sdd1 mdadm: /dev/sdd1 not large enough to join array |
则需要复制分区表,解决磁盘分区差异导致报错新硬盘空间不足问题,如下:
|
1 2 3 4 5 6 7 |
$ sudo sfdisk -d /dev/sda > part_table $ grep -v ^label-id part_table | sed -e 's/, *uuid=[0-9A-F-]*//' | sudo sfdisk /dev/sdd $ sudo sfdisk -d /dev/sda1 > part_table_1 $ grep -v ^label-id part_table_1 | sed -e 's/, *uuid=[0-9A-F-]*//' | sudo sfdisk /dev/sdd1 |
如果上述命令继续报错
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
$ grep -v ^label-id part_table_1 | sed -e 's/, *uuid=[0-9A-F-]*//' | sudo sfdisk /dev/sdd1 请检查现在是不是有人在使用此磁盘... 好的 Disk /dev/sdd1:14.55 TiB,16000898564096 字节,31251755008 个扇区 单元:扇区 / 1 * 512 = 512 字节 扇区大小(逻辑/物理):512 字节 / 4096 字节 I/O 大小(最小/最佳):4096 字节 / 4096 字节 磁盘标签类型:gpt 磁盘标识符:F941003D-163E-43B8-93A6-61BE96B51BC6 旧状况: >>> 已接受脚本标头(header)。 >>> 已接受脚本标头(header)。 >>> 已接受脚本标头(header)。 >>> 已接受脚本标头(header)。 >>> 已接受脚本标头(header)。 >>> 已接受脚本标头(header)。 >>> 完成。 脚本指定的最后一个 LBA 超出范围。 脚本指定的最后一个 LBA 超出范围。 脚本指定的最后一个 LBA 超出范围。 无法应用脚本标头(header),未创建磁盘标签。 离开中。 |
那么就没办法与原始磁盘保持相同的分区模式了,只能是直接使用整个硬盘,不指定硬盘下的具体分区,修改命令如下:
|
1 2 |
$ sudo mdadm --manage /dev/md1 --add /dev/sdd mdadm: added /dev/sdd |
再次检查磁盘分区情况:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS ............................................................. sda 8:0 0 14.6T 0 disk └─sda1 8:1 0 14.6T 0 part └─md1 9:1 0 14.6T 0 raid1 └─vg0-volume_0 252:0 0 14.6T 0 lvm /home/data ............................................................... sdd 8:48 0 14.6T 0 disk └─sdd1 8:49 0 14.6T 0 part └─vg0-volume_0 252:0 0 14.6T 0 lvm /home/data ............................................................... |
参考链接
- 记一次mdadm软raid1升级容量
- 为什么你的 mdadm 同步这么慢
- 如何将mdadm制作的软RAID数组迁移到新服务器和新操作系统?
- 使用 mdadm 管理 RAID 阵列
- 5 Tips To Speed Up Linux Software Raid Rebuilding And Re-syncing
- How to force mdadm to stop RAID5 array?
- How do I resize the filesystem on a RAID array?
- lvextend 逻辑卷扩容(xfs_growfs、resize2fs配合扩展文件系统)
- 如何在 Linux 上调整 XFS/Btrfs 文件系统的大小
- 记录:飞牛os更换硬盘并扩容
- linux中对标准分区(part分区)进行扩容(不需格式化)的方法
- Linux下删除分区的三种方法
- parted命令详解
- 更换 RAID1 磁盘 - 分区大小不同
- 【小工具】 - 修复软raid阵列状态为inacitve的方法
Raspberry Pi 配置成不间断电源 UPS 服务器
UPS (Uninterruptible Power Supply),是一种含有储能装置的不间断电源。主要用于给部分对电源稳定性要求较高的设备,提供不间断的电源。
一般的 UPS 都支持通过 USB 连接到电脑或者 NAS 等设备上,Linux/Mac/Windows 均支持使用 UPS。
因为电路不稳定,存在偶尔断电的情况,因此希望通过 UPS 保护树莓派、路由器、光猫、硬盘录像机等设备;将 UPS 通过 USB 接口连接到树莓派,由树莓派控制其他设备在断电时关机。
当前主要有两个方案,一个是 NUT(Network UPS Tools) 另一个是使用 apcupsd (Apcupsd UPS control software),两者二选一即可。
如果是群晖,可能只有使用 NUT(Network UPS Tools) ,如果使用 U-NAS 可能只能使用 apcupsd (Apcupsd UPS control software)。
从配置简便性上,推荐 apcupsd (Apcupsd UPS control software)。
apcupsd 配置

虽然施奈德官方提供的 PowerChute 软件只支持 Windows 系统,但 Linux 下亦有 apcupsd 可以使用。该软件以守护进程的方式运行,通过串行数据通信的方式(串口或 USB )实时获取 UPS 电源信息,包括当前外部输入电压、负载功率、电池电量等。当电池电量低于指定值时,会自动运行脚本程序 /etc/apcupsd/apccontrol ,以实现电脑系统的自动关闭或任何用户指定的操作。
把 UPS 电源与电脑连好后,根据 apcupsd 的说明文档,我们首先使用 lsusb 命令检查 Linux 系统是否能检测到已连接的 UPS 电源。
|
1 2 |
$ lsusb | grep Uninterruptible Bus 002 Device 004: ID 051d:0002 American Power Conversion Uninterruptible Power Supply |
确认能够找到设备后。
安装:
|
1 |
$ sudo apt install apcupsd |
编辑 apcupsd 的配置文件 /etc/apcupsd/apcupsd.conf,将其中 UPSCABLE 与 UPSTYPE 两项均设为 usb 。
|
1 2 3 |
UPSCABLE usb UPSTYPE usb |
因为台式机与 UPS 电源之间是通过 USB 通讯的,所以需要注释掉配置文件中的串口设置部分:
|
1 |
DEVICE /dev/ttyS0 |
将 NISIP 值设为 0.0.0.0 或你想绑定的指定主机 IP
|
1 |
NISIP 0.0.0.0 |
其余保持默认即可。
至此,可以启动 apcupsd 系统服务了。
|
1 |
$ sudo systemctl restart apcupsd |
该服务启动后,除了正常的 UPS 电源实时监测外,还会在本机的端口上开启一个服务器。我们可以在命令行终端使用apcaccess命令来获得电源的运行状态。其中的主要参数为:
-
LINEV:线电压 -
LOADPCT:负载占比 -
TIMELEFT:电池剩余维持时间 -
LOTRANS:最低容许输入电压 -
HITRANS:最高容许输入电压 -
BATTV:电池输出电压 -
NOMPOWER:额定功率
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
$ sudo apcaccess status APC : 001,036,0870 DATE : 2021-09-03 13:09:29 +0800 HOSTNAME : [YOUR-HOST-NAME] VERSION : 3.14.14 (31 May 2016) debian UPSNAME : [YOUR-UPS-NAME] CABLE : USB Cable DRIVER : USB UPS Driver UPSMODE : Stand Alone STARTTIME: 2021-09-03 13:03:24 +0800 MODEL : Back-UPS BK650M2-CH STATUS : ONLINE LINEV : 226.0 Volts LOADPCT : 20.0 Percent BCHARGE : 100.0 Percent TIMELEFT : 29.9 Minutes MBATTCHG : 5 Percent MINTIMEL : 3 Minutes MAXTIME : 0 Seconds SENSE : Low LOTRANS : 160.0 Volts HITRANS : 278.0 Volts ALARMDEL : 30 Seconds BATTV : 13.5 Volts LASTXFER : No transfers since turnon NUMXFERS : 0 TONBATT : 0 Seconds CUMONBATT: 0 Seconds XOFFBATT : N/A SELFTEST : OK STATFLAG : 0x05000008 SERIALNO : 000000000000 BATTDATE : 2001-01-01 NOMINV : 220 Volts NOMBATTV : 12.0 Volts NOMPOWER : 390 Watts FIRMWARE : 294803G -292804G END APC : 2021-09-03 13:09:39 +0800 |
客户端配置:
安装:
|
1 |
$ sudo apt install apcupsd |
打开 apcupsd 配置文件 /etc/apcupsd/apcupsd.conf
- 将
UPSCABLE值设为ether - 将
UPSTYPE值设为net - 将
DEVICE值设为你的 apcupsd 服务端地址和端口(也就是和 UPS 以 USB 相连接的主机)
与 NIS 相关的设置保持默认(也就是保持 NETSERVER 为 on)
|
1 2 3 4 5 |
UPSCABLE ether UPSTYPE net DEVICE 10.10.10.125:3551 |
启动 apcupsd 服务,输入 apcaccess 命令,你应该能看到 apcupsd 输出电源信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
$ sudo systemctl restart apcupsd $ sudo apcaccess status APC : 001,035,0891 DATE : 2024-10-01 12:45:29 +0800 HOSTNAME : hpgen8 VERSION : 3.14.14 (31 May 2016) debian UPSNAME : raspberrypi CABLE : Ethernet Link DRIVER : NETWORK UPS Driver UPSMODE : Stand Alone STARTTIME: 2024-10-01 12:45:29 +0800 MASTERUPD: 2024-10-01 12:45:29 +0800 MASTER : 10.10.10.125:3551 MODEL : Back-UPS 650 STATUS : ONLINE SLAVE LINEV : 224.0 Volts LOADPCT : 36.0 Percent BCHARGE : 100.0 Percent TIMELEFT : 3.4 Minutes MBATTCHG : 5 Percent MINTIMEL : 3 Minutes MAXTIME : 0 Seconds SENSE : Low LOTRANS : 165.0 Volts HITRANS : 266.0 Volts BATTV : 13.6 Volts LASTXFER : Unacceptable line voltage changes NUMXFERS : 0 TONBATT : 0 Seconds CUMONBATT: 0 Seconds XOFFBATT : N/A STATFLAG : 0x05000408 SERIALNO : ********** BATTDATE : 2018-11-04 NOMINV : 220 Volts NOMBATTV : 12.0 Volts FIRMWARE : 822.A3.I USB FW:A3 END APC : 2024-10-01 12:45:31 +0800 |
NUT 配置
安装 NUT
NUT (Network UPS Tools) 是一种开源软件工具,其主要功能特点是实时监控与管理不间断电源(UPS)设备,支持多种通信协议,自动执行操作以应对电力故障,适用于多平台,并允许集中管理多个UPS设备,以确保与这些设备连接的计算机和设备在电力问题发生时能够继续正常运行或安全关闭。
NUT中的主要软件组件和功能:
-
Driver(驱动程序):NUT包括各种不同制造商的UPS设备的驱动程序,使NUT能够与多种型号的UPS设备通信。这些驱动程序负责与UPS设备建立连接,并获取有关电源状态、电池状态和其他参数的信息。
-
upsd(UPS守护进程):upsd是NUT的核心守护进程,负责与UPS设备通信,并将UPS状态信息提供给其他NUT组件和客户端。它可以通过网络协议(如SNMP、HTTP、XML-RPC等)向其他计算机提供UPS状态信息。
-
upsmon(UPS监控守护进程):upsmon监控守护进程用于监视UPS状态,并在检测到电力问题时执行操作。它可以配置为执行自定义脚本、关闭计算机或发送警报通知,以确保系统的连续性和数据完整性。
-
upslog(UPS事件记录器):upslog用于记录UPS事件和状态信息,以便后续分析和故障排除。它可以生成日志文件,其中包含UPS的运行历史和电力事件。
-
nutclient(NUT客户端工具):NUT提供了一些用于监控和管理UPS的命令行工具,例如upsc用于查询UPS状态,upscmd用于发送命令到UPS,以及upsrw用于修改UPS配置。
-
安装
|
1 |
apt update && apt install -y nut |
通过 USB 连接 UPS
在将 UPS 通过 USB 连接到树莓派后,可以通过查看 USB 设备进行检查
- 检查 USB 连接
|
1 |
sudo lsusb |
其中的 Device 003 就是 UPS,说明 USB 连接正常
|
1 2 3 4 5 6 7 |
Bus 001 Device 004: ID 051d:0002 American Power Conversion Uninterruptible Power Supply Bus 003 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub Bus 002 Device 002: ID 174c:55aa ASMedia Technology Inc. ASM1051E SATA 6Gb/s bridge, ASM1053E SATA 6Gb/s bridge, ASM1153 SATA 3Gb/s bridge, ASM1153E SATA 6Gb/s bridge Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 003: ID 0463:ffff MGE UPS Systems UPS Bus 001 Device 002: ID 2109:3431 VIA Labs, Inc. Hub Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub |
- 通过
nut-scanner检查 UPS 设备
|
1 |
sudo nut-scanner -q |
正确识别到连接的 UPS 设备,驱动为 usbhid-ups,产品为 SANTAK TG-BOX
|
1 2 3 4 5 6 7 8 9 |
[nutdev1] driver = "usbhid-ups" port = "auto" vendorid = "0463" productid = "FFFF" product = "SANTAK TG-BOX" serial = "Blank" vendor = "EATON" bus = "001" |
或者如下:
|
1 2 3 4 5 6 7 8 9 |
[nutdev1] driver = "usbhid-ups" port = "auto" vendorid = "051D" productid = "0002" product = "Back-UPS 650 FW:822.A3.I USB FW:A3" serial = "**********" vendor = "APC" bus = "001" |
配置 UPS
###配置 UPS 驱动
驱动程序负责与UPS设备建立连接,并获取有关电源状态、电池状态和其他参数的信息
- 将 UPS 设备添加到 NUT
使用 nut-scanner 将连接的 UPS 信息追加到 /etc/nut/ups.conf 配置中,其中的 nutdev1 是设备的名称,可以自定义
|
1 |
sudo nut-scanner -q | sudo tee -a /etc/nut/ups.conf |
- 启动 NUT
使用 upsdrvctl 命令启动 NUT
|
1 |
sudo upsdrvctl start |
配置 UPS 守护进程
upsd 负责与UPS设备通信,并将UPS状态信息提供给其他NUT组件和客户端
- 启动 upsd
|
1 2 3 4 |
# 配置NUT为UPS服务器模式 sudo sed -i "s/^MODE=.*/MODE=netserver/g" /etc/nut/nut.conf sudo upsd |
查看 UPS 状态
使用 upsc 命令查看 UPS 设备的状态;其中的 nutdev1 是 /etc/nut/ups.conf 中配置的名称
|
1 |
sudo upsc nutdev1@localhost |
该命令会返回 UPS 设备的所有信息
|
1 2 3 4 5 6 7 8 9 |
Init SSL without certificate database battery.charge: 98 battery.charge.low: 20 battery.runtime: 2744 battery.type: PbAc device.mfr: EATON device.model: SANTAK TG-BOX 600 device.serial: Blank ... |
也可以指定名称查看 UPS 状态
|
1 |
sudo upsc nutdev1@localhost ups.status |
|
1 2 |
Init SSL without certificate database OL |
配置关机策略
配置 upsd 用户
upsd 用户对应的配置文件是 /etc/nut/upsd.users,配置用户用于读取 UPS的信息;在以下配置中,用户名是 upsmon,密码是 123456,运行模式是 master,即该设备为主节点(如果有同时使用其他 UPS则可以是 slave)
|
1 2 3 |
[upsmon] password = "123456" upsmon master |
- 重启 upsd
|
1 |
sudo upsd -c reload |
配置关机策略
关机策略使用的是 upsmon,upsmon 监控守护进程用于监视UPS状态,并在检测到电力问题时执行操作,它可以配置为执行自定义脚本、关闭计算机或发送警报通知
- 配置关机策略
修改 /etc/nut/upsmon.conf,添加如下配置,使用的是刚才创建的用户信息,这样,当设备监听到 UPS 发出的 LOWBATT 命令后,就会执行关闭系统
|
1 |
MONITOR ups@localhost 1 monuser 123456 master |
这个命令告诉NUT要监控名为 “ups” 的UPS设备,该设备位于本地主机上。监控用户 “monuser”,可以使用密码 “123456” 连接到NUT,并具有 “master” 角色的权限。这允许用户通过NUT连接来监视和管理UPS设备
- 启动 upsmon
|
1 |
sudo upsmon |
执行自定义动作
NUT 通过 upssched 支持监听 UPS 事件并执行指定脚本,因此可以用于执行一些自定义的动作,如发送通知等
配置 upsmon
修改 /etc/nut/upsmon.conf 文件,添加如下配置
- 指定运行命令
该配置用于在发生事件时运行 /sbin/upssched 服务
|
1 |
NOTIFYCMD /sbin/upssched |
- 配置触发条件
|
1 2 3 4 5 |
NOTIFYFLAG ONLINE SYSLOG+WALL+EXEC NOTIFYFLAG ONBATT SYSLOG+WALL+EXEC NOTIFYFLAG LOWBATT SYSLOG+WALL+EXEC |
这里监听了 ONLINE, ONBATT, 和 LOWBATT三个事件,分别是电源供电、电池供电和低电量事件;SYSLOG声明记录事件日志到系统中,WALL声明通知所有在线用户,EXEC 声明需要执行命令
配置 upssched
配置好 upsmon 后,还需要配置 upssched 执行相关的命令,需要将以下内容添加到 /etc/nut/upssched.conf 中
- 配置 upsmon
|
1 2 3 4 5 6 7 8 9 10 |
CMDSCRIPT /usr/local/bin/upssched-script.sh PIPEFN /run/nut/upssched/upssched.pipe LOCKFN /run/nut/upssched/upssched.lock AT ONBATT * EXECUTE battery_on # 发送断电的消息 AT ONLINE * EXECUTE power_online # 发送来电的消息 AT ONBATT * START-TIMER watch_battery 60 # 60 秒后执行监控电池状态 AT ONLINE * CANCEL-TIMER watch_battery # 取消 监控电池状态 AT LOWBATT * EXECUTE low_battery # 低电量 |
CMDSCRIPT 指定了监听到事件后需要执行的脚本 PIPEFN和LOCKFN指定了监听事件的管道并加锁,避免被修改 AT 和 EXECUTE 指定了监听的事件并执行相关的脚本;当监听到 ONBATT, ONLINE 和 LOWBATT 时执行 CMDSCRIPT指定的脚本,并将 battery_on, power_online 和 low_battery作为参数 AT 和 START-TIMER 启动了一个计时器,在 60s 后执行 AT 和 CANCEL-TIMER 指定如果在启动计时器60s 内发生了 ONLINE事件,则取消计时器
- 配置 upssched-script.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
#!/bin/bash BARK_URL=${BARK_URL:-"https://api.day.app/xxxxxx"} function send_message() { message="$1" echo "发送通知:${message}" curl -X "POST" "$BARK_URL" \ -H 'Content-Type: application/json; charset=utf-8' \ -d "{ \"title\": \"UPS 状态发生变化\", \"body\": \"${message}\", \"group\": \"UPS\" }" } case $1 in battery_on) battery_charge=$(upsc ups@localhost battery.charge) send_message "UPS 电池已启用,目前电量: ${battery_charge}" ;; power_online) battery_charge=$(upsc ups@localhost battery.charge) send_message "UPS 已恢复供电,目前电量: ${battery_charge}" ;; watch_battery) battery_charge=$(upsc ups@localhost battery.charge) send_message "UPS 目前电量: ${battery_charge}" ;; low_battery) battery_charge=$(upsc ups@localhost battery.charge) send_message "UPS 低电量: ${battery_charge},开始关机" ;; *) logger -t upssched-cmd "其他未知指令: $1" ;; esac |
这段脚本用于接收事件,并执行动作;这里通过 Bark 发送了通知
记录 UPS 日志
ups 支持通过 upslog 记录 UPS 日志
|
1 |
sudo upslog -l /var/log/ups.log -i 1 -s ups@localhost -f "%TIME @Y-@m-@d @H:@M:@S%, battery.charge:%VAR battery.charge%, input.voltage:%VAR input.voltage%, ups.load:%VAR ups.load%, ups.status:[%VAR ups.status%], ups.temperature:%VAR ups.temperature%, input.frequency:%VAR input.frequency%" |
这段命令中,通过 -l指定了输出文件为 /var/log/ups.log,-i 1 表示1s输出一次,-s ups@localhost指定了 UPS 位置,-f 指定了日志输出格式
输出日志参考:
|
1 |
2023-10-06 19:58:38, battery.charge:78, input.voltage:NA, ups.load:8, ups.status:[OL], ups.temperature:NA, input.frequency:NA |
配置 UPS 监控
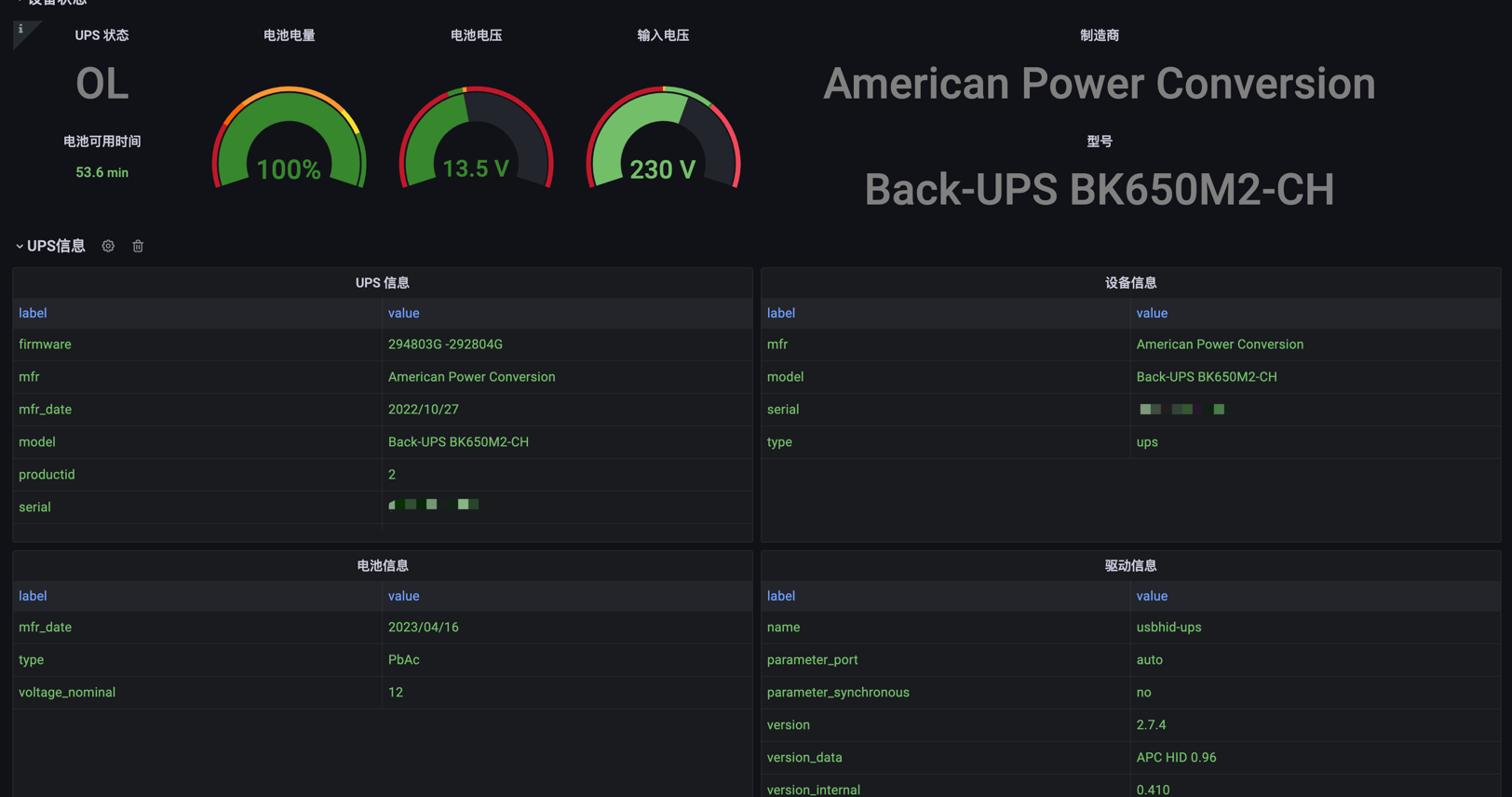
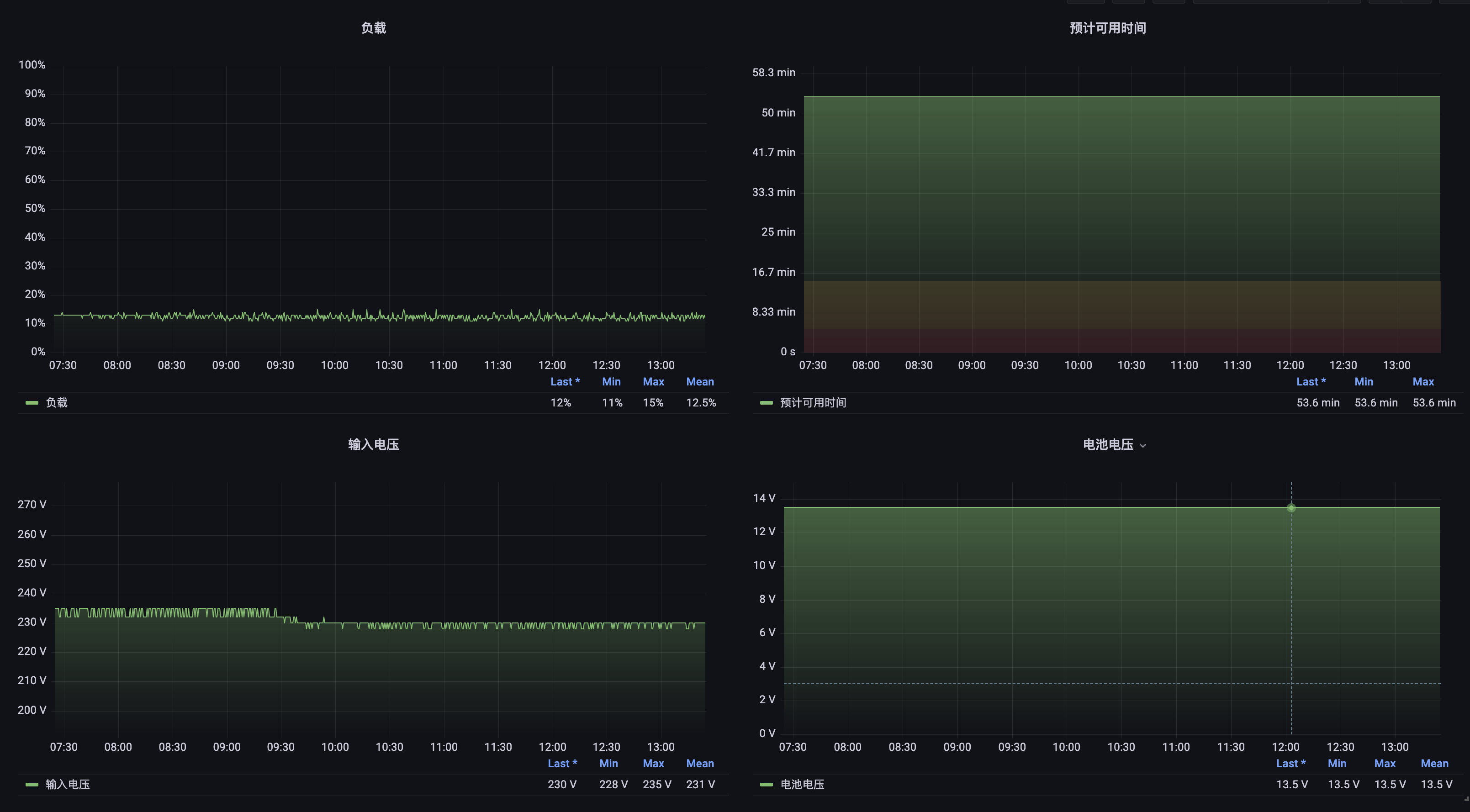
NUT 支持通过 HTTP 接口对外提供 UPS 的信息,因此可以用于监控 UPS; https://github.com/helloworlde/nut_exporter 提供了 Prometheus Exporter,可以使用 Prometheus 和 Grafana 对 UPS 进行监控
修改 NUT 运行模式
配置文件是 /etc/nut/nut.conf;将模式修改为 netserver的目的是允许通过局域网访问 UPS 的设备信息,用于其他设备监控、监听 UPS 的状态;如果不需要监听则不需要配置
|
1 |
MODE=netserver |
配置 upsd
修改 upsd 对应的配置文件 /etc/nut/upsd.conf,添加监听的地址和端口;添加局域网 IP 是用于局域网内其他设备进行监控,否则可能会拒绝连接
|
1 2 3 4 5 |
LISTEN 127.0.0.1 3493 LISTEN ::1 3493 LISTEN 0.0.0.0 3493 |
- 重启 upsd
|
1 2 3 |
sudo upsd -c reload sudo reboot |
配置 NUT Exporter
- 配置
docker-compose.yaml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
version: "3" services: nut-exporter: image: hellowoodes/nut-exporter container_name: nut-exporter hostname: nut-exporter restart: unless-stopped command: --log.level=debug ports: - "9199:9199" environment: - NUT_EXPORTER_SERVER=${NUT_EXPORTER_SERVER} - NUT_EXPORTER_USERNAME=${NUT_EXPORTER_USERNAME} - NUT_EXPORTER_PASSWORD=${NUT_EXPORTER_PASSWORD} - NUT_EXPORTER_VARIABLES=${NUT_EXPORTER_VARIABLES} volumes: - "/etc/localtime:/etc/localtime:ro" |
- 配置
.env
Server 的地址即为树莓派局域网的IP地址,用户名和密码是 upsd 的用户和密码;NUT_EXPORTER_VARIABLES是需要抓取的监控指标类型,不同的设备可能指标不一样;可以通过 upsc ups@localhost 获取所有的指标名称进行替换
|
1 2 3 4 5 6 7 |
NUT_EXPORTER_SERVER=192.168.31.11 NUT_EXPORTER_USERNAME=monuser NUT_EXPORTER_PASSWORD=123456 NUT_EXPORTER_VARIABLES=battery.charge,battery.charge.low,battery.runtime,battery.type,device.mfr,device.model,device.serial,device.type,driver.name,driver.parameter.pollfreq,driver.parameter.pollinterval,driver.parameter.port,driver.parameter.product,driver.parameter.productid,driver.parameter.serial,driver.parameter.synchronous,driver.parameter.vendor,driver.parameter.vendorid,driver.version,driver.version.data,driver.version.internal,input.transfer.high,input.transfer.low,outlet.1.desc,outlet.1.id,outlet.1.status,outlet.1.switchable,outlet.desc,outlet.id,outlet.switchable,output.frequency.nominal,output.voltage,output.voltage.nominal,ups.beeper.status,ups.delay.shutdown,ups.delay.start,ups.firmware,ups.load,ups.mfr,ups.model,ups.power.nominal,ups.productid,ups.serial,ups.status,ups.timer.shutdown,ups.timer.start,ups.type,ups.vendorid |
- 配置 Prometheus
|
1 2 3 4 5 6 7 8 9 |
- job_name: ups-exporter honor_timestamps: true scrape_interval: 15s scrape_timeout: 10s metrics_path: /ups_metrics scheme: http static_configs: - targets: - 192.168.31.11:9199 |
- 配置 Grafana 面板
导入 https://github.com/helloworlde/nut_exporter/blob/master/dashboard/dashboard.json 即可
参考链接
ubuntu 24.04使用SMB给macOS做无线Time Machine备份
前要:
一直以来使用外置硬盘给 Mac 做 Time Machine 备份盘,但是存在若干不够方便的地方,如:
- 磁盘需要格式化为 APFS 格式,虽然 APFS 的“卷共享容器空间”的机制可以很方便的让 Time Machine 卷和其他资料卷共用空间,而不是像传统的分盘让空间分隔,还要考虑空间分配问题。但 APFS 格式只在 macOS 设备间方便使用
- 虽然在不连接磁盘的情况下,内置存储也会保留24小时内到每小时快照,但总是需要刻意记起找出插入硬盘进行备份的操作
正好最近使用旧电脑刷了 Ubuntu 用作 NAS 使用,于是想了解关于如何配置无线 Time Machine。
无线Time Machine的共享协议选择:
最开始找到的教程是使用 AFP 的开源实现 netatalk 让 Linux 支持 AFP 共享协议,然后作为 Time Machine 盘。但发现 netatalk 最近曝出过严重漏洞,项目本身在GitHub也只有 0.2K Star 的关注。主观感觉其稳定性是存在疑问的。
后来发现,并不一定是 AFP 协议的共享才能做 Time Machine 备份盘;Samba 只要进行一些配置就能做 Time Machine 备份用了。
在 Apple 官方文档中说明有写到
【提示】如果可以选择 SMB 或 AFP,请使用 SMB 来备份到外置备份磁盘。
目前 Apple 官方也是更推荐使用 SMB 协议来作为无线 Time Machine 备份的。
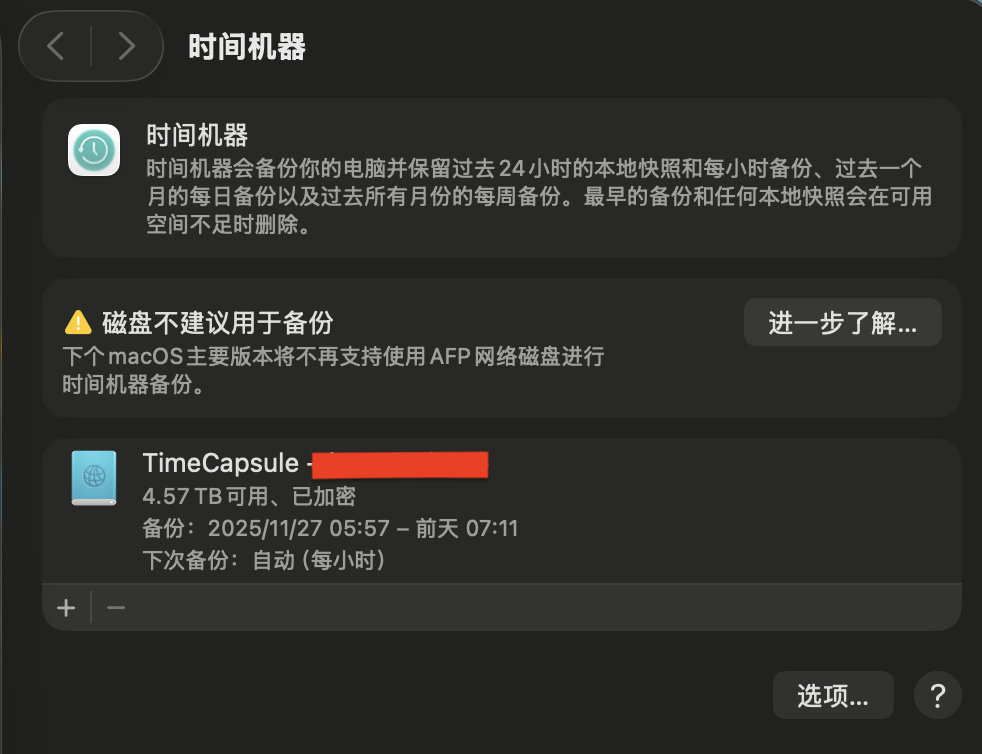
最新的 macOS Tahoe 26.2 已经提示下个版本不再支持 AFP 进行备份了,如下图:
ubuntu 24.04上Samba的配置
安装 avahi 和 samba :
|
1 2 3 4 5 6 7 8 9 10 |
$ sudo apt install samba avahi-daemon # 变更目录所有者权限,给予目标用户写入权限,此处假定用户名为 tms # 否则可能出现目录只读的情况 # # 如果发生目录可以浏览,但是创建文件失败,一定要确认一下这个目录的所有者是不是指定的用户 $ sudo chown -R tms:tms /home/data/.timemachine $ sudo chmod -R 775 /home/data/.timemachine |
在原来的 /etc/samba/smb.conf 尾部增加如下配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
[TimeMachine] # 存储路径 path = /home/data/.timemachine # 是否允许遍历目录 browseable = yes # 是否只读 read only = no # 是否允许游客访问 guest ok = no # 注释 comment = Backup for Mac Computers # 指定可以访问的用户名,多个用户使用空格分割,用户名必须是已经存在的,这里只是许可已经存在的用户可以访问 # 如果可以看到目录,但是点击目录报错文件不存在,重点检查用户名是否正确 valid users = tms # 指定可以写入文件的用户名列表,多个用户使用空格分割,用户名必须是已经存在的,这里只是许可已经存在的用户可以访问 # 如果可以看到目录,但是点击目录报错文件不存在,重点检查用户名是否正确 write list = tms # vfs_catia 提供非法字符转换以正确映射 Apple 路径。 vfs_fruit 是用于实现与 Apple SMB 客户端兼容,vfs_streams_xattr 是允许在底层文件系统中存储 NTFS 备用数据流的主要模块 vfs objects = catia fruit streams_xattr fruit:aapl = yes fruit:time machine = yes # 设置最大可用空间 # fruit:time machine max size = 500G |
更详细的配置可参考
Configure Samba to Work Better with Mac OS X
检查配置语法是否正确:
|
1 2 3 |
# 检查Samba配置文件语法 $ sudo testparm |
如果配置正确,应该返回类似如下内容:
|
1 2 3 4 5 6 |
Load smb config files from /etc/samba/smb.conf Loaded services file OK. Server role: ROLE_STANDALONE Press enter to see a dump of your service definitions ... |
创建 smb 配置文件中指定的用户:
|
1 2 3 |
# 给可以访问的用户设置密码,用户名必须是已经存在的,否则会失败 $ sudo smbpasswd -a tms |
重启服务,使得配置生效,如下:
|
1 |
$ sudo systemctl restart smbd |
检测连接是否正常,查看详细错误代码:
|
1 2 3 |
$ sudo apt install smbclient $ smbclient //localhost/TimeMachine -U tms |
macOS上的配置:
打开访达,边栏上应该能直接看到服务器,点击后点上面的“连接身份...”,再点“注册用户”,输入用户和密码,勾选“在我的钥匙串中记住此密码”,点连接,随后会显示出多个共享,多选连接即可。
如果边栏没有,则需按command+K来手动连接,输入 smb://xiaomingnas.local。这里xiaomingnas.local中的xiaomingnas是主机的hostname,通常avahi的mDNS服务会使用<hostname>.local作为域名。点连接,后续步骤与上述相同。
随后在 Mac 的系统设置-通用-时间机器,点+号,就能选择设置的 Time Machine 进行备份了。然后根据提示设置登录用户名,时间机器的加密密码即可。
无线备份受限于网络传输速度,首次备份可能需要数小时才能完成,可耐心等待。
Time Machine 默认设置了速度限制,以保障网络和磁盘可正常使用,首次备份可以在 Mac 上暂时解除该限制
|
1 2 3 4 5 6 7 8 |
# 解除限制 $ sudo sysctl debug.lowpri_throttle_enabled=0 # 恢复速度限制: $ sudo sysctl debug.lowpri_throttle_enabled=1 # 查看状态 $ sysctl -n debug.lowpri_throttle_enabled |
用外置磁盘和无线共享设置Time Machine的区别:
使用外置磁盘备份,点击边栏上的卷后,可以看到目录形式展示的每次的备份,并直接查看其中的目录文件。还可以方便地多选备份进行删除,来腾出空间占用
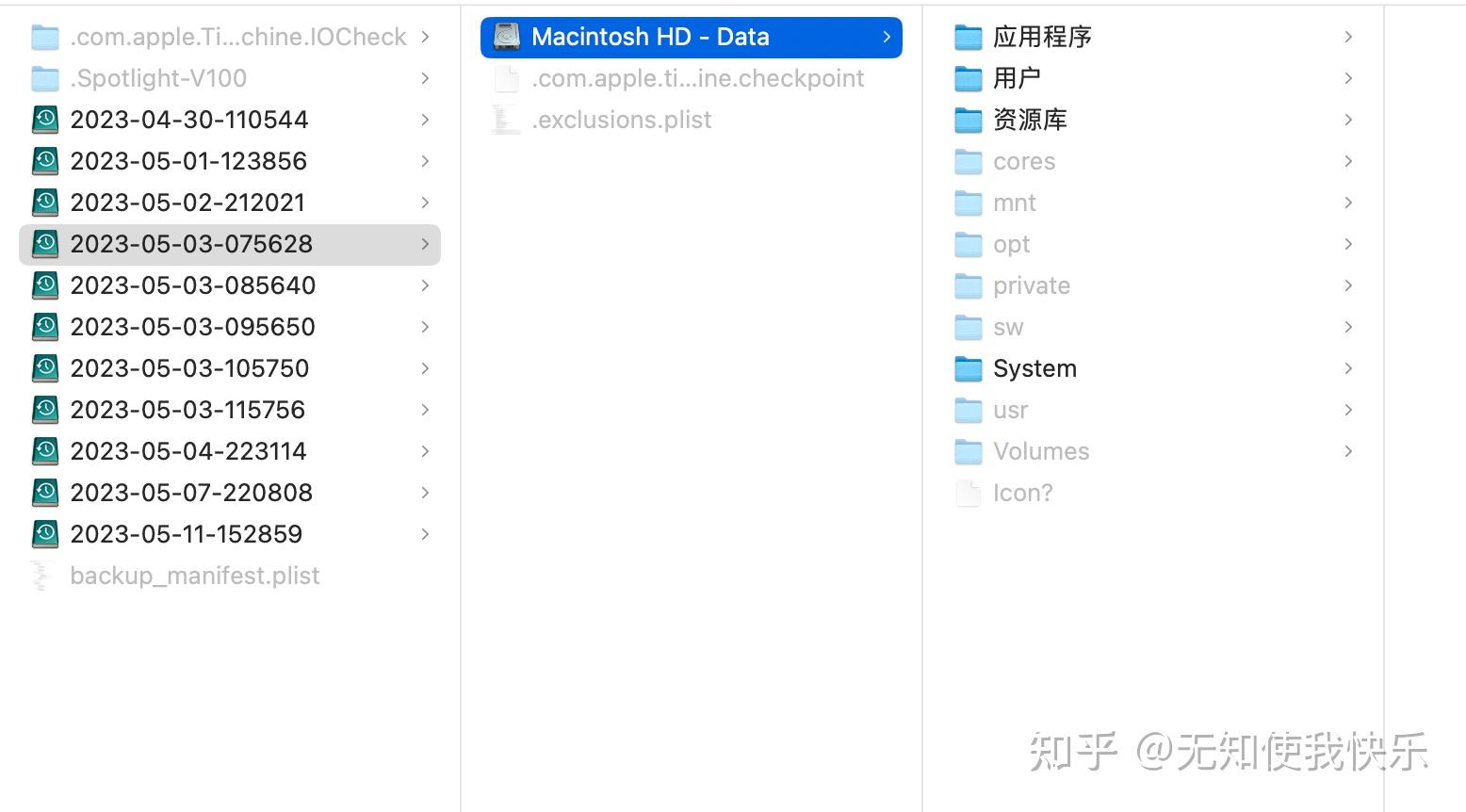
而使用 SMB 共享作为备份盘。这会在共享路径下生成一个类似“小明的MacBook Air.sparsebundle”目录。大致结构如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ tree -L 2 . └── 小明的MacBook Air.sparsebundle ├── bands ├── com.apple.TimeMachine.MachineID.bckup ├── com.apple.TimeMachine.MachineID.plist ├── com.apple.TimeMachine.Results.plist ├── com.apple.TimeMachine.SnapshotHistory.plist ├── Info.bckup ├── Info.plist ├── lock ├── mapped └── token |
其中 bands 目录中会有大量固定大小为 67MB 的二进制文件,这些便是备份的数据。
Apple 官方对 sparsebundle 的解释的大致意思是,它是一个以二进制形式存储的,可按需收缩和扩大的可扩展文件。
这样看用 SMB 共享设置 Time Machine 实际上更加灵活,相比之下不挑磁盘格式,且备份在 Linux 上的磁盘中仅作为某个路径下的某个目录存在,而不像使用外置磁盘备份一样单独占据一个 APFS 卷。
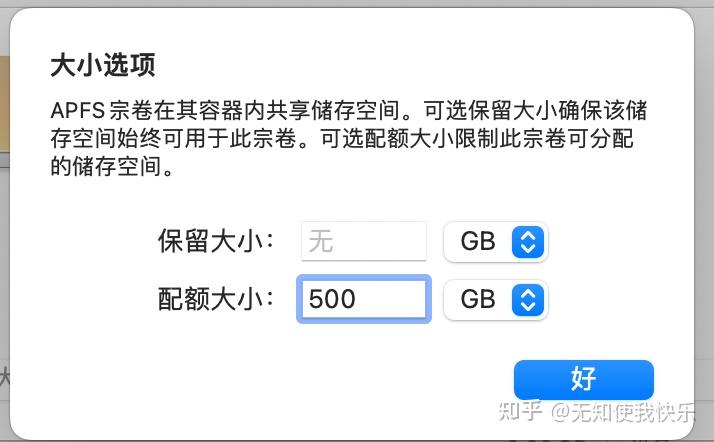
但其不能像外置磁盘一样,可以任意多选删除备份来腾出空间。但可以设置 fruit:time machine max size 来限制备份大小,这样达到空间临界点时 macOS 就会自动删除最旧的备份来腾出空间。当然,磁盘备份同样也可以在添加 APFS 卷时,通过设置“配额大小”来限制 Time Machine 过度膨胀(但设置完毕后不易变更)
参考链接
- Linux使用SMB给macOS做无线Time Machine备份
- 用 samba 来低成本搭建 Time Machine 备份服务器
- Linux 通过 Samba+Avahi 搭建 Time Machine 服务
- [Help]: Can't Connect to Time Machine #170
- Raspberry Pi Time machine
- Using a Raspberry Pi for Time Machine
- samba 共享目录write permission deny问题修复 可读取内容但不可修改 删除 新增文件
- Samba documentation
- Setting up Samba as a Standalone Server
Coping with the TCP TIME-WAIT state on busy Linux servers
TL;DR
Do not enable
net.ipv4.tcp_tw_recycle—it doesn’t even exist anymore since Linux 4.12. Most of the time,TIME-WAITsockets are harmless. Otherwise, jump to the summary for the recommended solutions.
The Linux kernel documentation is not very helpful about what net.ipv4.tcp_tw_recycle and net.ipv4.tcp_tw_reuse do. This lack of documentation opens the path to numerous tuning guides advising to set both these settings to 1 to reduce the number of entries in the TIME-WAIT state. However, as stated by the tcp(7) manual page, the net.ipv4.tcp_tw_recycle option is quite problematic for public-facing servers as it won’t handle connections from two different computers behind the same NAT device, which is a problem hard to detect and waiting to bite you:
Enable fast recycling of
TIME-WAITsockets. Enabling this option is not recommended since this causes problems when wrking with NAT (Network Address Translation).
I will provide here a more detailed explanation of how to properly handle the TIME-WAIT state. Also, keep in mind we are looking at the TCP stack of Linux. This is completely unrelated to Netfilter connection tracking which may be tweaked in other ways.1
继续阅读Coping with the TCP TIME-WAIT state on busy Linux servers