#!/usr/bin/expect -f
#开启内部动作调试输出,观察是否正确执行 1 代表打开调试,0代表关闭调试
exp_internal 0
set HostAddr "www.mobibrw.com"
set HostPort 22
set UserName "user"
set BackupShell "hostback.sh"
set Password "password"
set BakDir "backup"
set timeout -1
#由于通过FTP传输的文件格式可能\n被替换为\r\n 的情况,因此需要执行一下 dos2unix 转化到 \n
spawn dos2unix $BackupShell
expect eof
spawn ssh $HostAddr -p $HostPort -l $UserName rm -rf ~/$BackupShell
expect -re ".*assword:"
send "$Password\r"
expect eof
spawn scp $BackupShell $UserName@$HostAddr:~/$BackupShell
expect -re ".*assword:"
send "$Password\r"
expect eof
spawn ssh $HostAddr -p $HostPort -l $UserName chmod +x ~/$BackupShell
expect -re ".*assword:"
send "$Password\r"
expect eof
#解决在群晖NAS系统上TCP超时问题,增加心跳保持参数
#同时注意,远端语言有可能不是英文,因此需要增加LC_ALL=C强制切换到英文,否则后续匹配可能无法完成
spawn ssh $HostAddr -o TCPKeepAlive=yes -o ServerAliveInterval=30 -p $HostPort -l $UserName "LC_ALL=C sudo -E bash ~/$BackupShell"
expect -re ".*assword:"
send "$Password\r"
expect eof
spawn scp -r $UserName@$HostAddr:~/$BakDir ./
expect -re ".*assword:"
send "$Password\r"
expect eof
#backup-20151227.log\nbash: warning: setlocale: LC_ALL: cannot change locale (zh_CN.utf8) 这种情况要注意
proc getFilterFile { host port user bakdir password filter regx} {
spawn ssh $host -p $port -l $user ls ~/$bakdir | grep $filter
expect -re ".*assword:"
send "$password\r"
expect -re "$regx"
expect eof
return [string trimright $expect_out(0,string)]
}
cd ./$BakDir
#校验MD5,SHA1
set MD5File [getFilterFile $HostAddr $HostPort $UserName $BakDir $Password "md5" "md5(.*).txt"]
puts stdout $MD5File
#修改语言环境,否则md5sum,sha1sum返回的结果中可能不会出现"OK",而是会出现“确定”
#“失败”
if {[info exists ::env(LANG)]==1} {
set ORG_LANG "$env(LANG)"
puts stdout "$env(LANG)"
set env(LANG) "C"
puts stdout "$env(LANG)"
}
if {[info exists ::env(LC_ALL)]==1} {
set ORG_LC_ALL "$env(LC_ALL)"
puts stdout "$env(LC_ALL)"
set env(LC_ALL) "C"
puts stdout "$env(LC_ALL)"
}
spawn md5sum -c $MD5File
expect -re ".*OK"
expect eof
set Sha1File [getFilterFile $HostAddr $HostPort $UserName $BakDir $Password "sha1" "sha1(.*).txt"]
puts stdout $Sha1File
spawn sha1sum -c $Sha1File
expect -re ".*OK"
expect eof
#还原语言设置
if {[info exists ::env(LANG)]==1} {
puts stdout "$env(LANG)"
set env(LANG) "$ORG_LANG"
puts stdout "$env(LANG)"
}
if {[info exists ::env(LC_ALL)]==1} {
puts stdout "$env(LC_ALL)"
set env(LC_ALL) "$ORG_LC_ALL"
puts stdout "$env(LC_ALL)"
}
#打印本次的备份日志出来
set LogFile [getFilterFile $HostAddr $HostPort $UserName $BakDir $Password "backup" "backup(.*).log"]
puts stdout $LogFile
set f [ open $LogFile r]
while { [ gets $f line ] >= 0 } { puts stdout $line;}
#删除远端的备份脚本
spawn ssh $HostAddr -p $HostPort -l $UserName sudo rm -rf ~/$BackupShell
expect -re ".*assword:"
send "$Password\r"
expect eof
#删除远端的备份目录
spawn ssh $HostAddr -p $HostPort -l $UserName sudo rm -rf ~/$BakDir
expect -re ".*assword:"
send "$Password\r"
expect eof
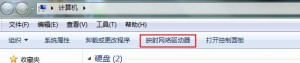
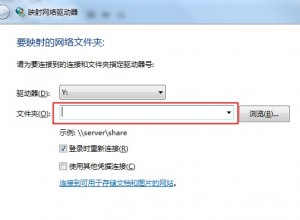
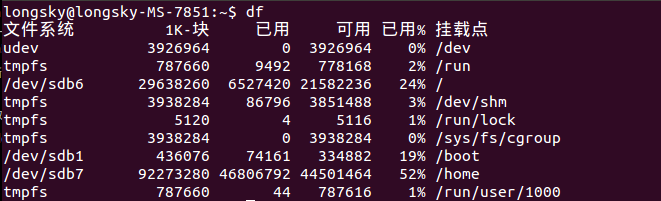
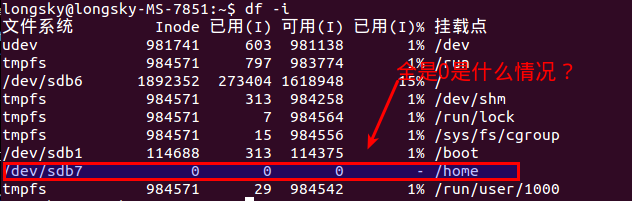 后来才知道,btrfs格式是不能使用df命令的,btrfs有自己的单独的命令查询.
后来才知道,btrfs格式是不能使用df命令的,btrfs有自己的单独的命令查询.