Caffe代码中自带一些模型的例子,这些例子在源代码的models目录下,这些都是其他项目中用来训练的配置文件,学习的时候,我们没有必要完全自己从头到尾搭建自己的网络模型,而是直接使用例子中的模型,后期在这些模型上简单调整一下,一般可以满足大多数的需求。
下面我们以models/bvlc_alexnet目录下的模型配置文件为例子,训练我们自己的神经网络。
Caffe代码中自带一些模型的例子,这些例子在源代码的models目录下,这些都是其他项目中用来训练的配置文件,学习的时候,我们没有必要完全自己从头到尾搭建自己的网络模型,而是直接使用例子中的模型,后期在这些模型上简单调整一下,一般可以满足大多数的需求。
下面我们以models/bvlc_alexnet目录下的模型配置文件为例子,训练我们自己的神经网络。
macOS Sierra (10.12.4)优酷客户端下载后的视频文件位置在:
|
1 |
/Users/你的用户名/Library/Containers/com.youku.mac/Data |
可以在命令行下执行:
|
1 |
$ open ~/Library/Containers/com.youku.mac/Data |
打开这个目录。
本文大部分内容来源于Hollow官方文档
开发过程中会遇到这样的数据:体量算不上“大数据”,数据在变化,幅度也不大。处理这类数据的时候,一般是把数据放到内存中(容器、json、xml、RDBMS),隔断时间更新一次。
这样处理有很多局限性
世界陷入水火,一般的套路现在主角就该出场了
Netflix推出了Hollow,它是数据的利剑,内存的盾牌,它将不JSON、不XML、少GC、高效率的解决问题,总而言之,他是人民的大救星,下面请一起走进科学,走进Hollow的内心世界。
Hollow致力于解决内存数据问题,处理的量级(将数据转为JSON)一般在GB级别,TB/PB就爱莫能助了。
快照-增量
生产的数据有两种类型,Snapshot、Delta,即全量、增量数据。大多数情况下,我们处理的是增量数据。
生产-消费者模式
一个生产者服务多个消费者,生产者生产快照和增量数据更新至BLOB(二进制大数据)文件,消费者在内存中使用数据,只读属性保证了消费的高效。生产文件到内存对开发者是透明的。
数据模型
数据模型基于一个POJO,又相当于数据库的一行。开发者只需要定义一个POJO,Hollow的API-Generator会生产这个POJO相应的消费文件。
它适用于只读数据、单个生产者、可能多个消费者的情形。Hollow实现持久化的唯一机制是利用BLOB存储,它只是一个文件存储,可能是S3、NFS、甚至一台FTP服务器。启动的时候,消费者们读取整个数据集的快照,并将数据集引导到内存中。通过增量的方法,可以保证内存中的数据集是最新的。对于每个消费者,内存中的数据备份是临时性的,如果消费者重新启动,需要从BLOB存储中重新加载快照。
实际上BLOB快照文件的格式很简单,它在很大程度上和在内存布局的结构相同,因此数据初始化主要是将BLOB的内容直接复制到内存中,这一步可以快速完成,确保了初始化的时间很短。
使用macOS Sierra(10.12.3)开发C/C++项目,经常用到网上的开源项目,很多项目是直接用MakeFile来管理项目的,导致在调试,编辑项目的时候,比较麻烦,搜索了半天,才找到目前看来比较方便的方式,就是结合Eclipse IDE for C/C++ Developers, CMake Editor的方式来进行处理。
继续阅读macOS Sierra (10.12.3)使用Eclipse IDE for C/C++ Developers结合CMake Editor编辑Linux MakeFile项目
macOS Sierra(10.12.3)上尝试下载Nvidia的CUDA,但是由于国内网络问题,导致使用浏览器下载的时候,不仅慢,而且还经常失败,基本上没办法下载成功。尝试使用迅雷的话,如果不是会员,貌似也没有太多的用处。另外一个比较麻烦的问题是,Nvidia下载服务器,随着下载时间的延长,会强制限制下载速度,导致越来越慢,到最后只有若干KB的速度。
继续阅读macOS Sierra (10.12.3)利用aria2解决CUDA下载失败问题
ObjectMapper写入一个数据,包含一个java.util.Date成员,报Expected class sun.util.calendar.BaseCalendar$Date but object was class java.util.Date错误。
这是hollow v2.1.0以下的一个bug,详见:
https://github.com/Netflix/hollow/issues/13
| Thanks very much for the report! I verified the issue and released a fix in v2.1.1. |
有趣的是,将hollow替换成2.1.1,还是报这个错误,替换成2.2.1就好了
这句I verified the issue and released a fix in v2.1.1.像极了研发的口头禅‘下个版本修复’,承包了我一上午的笑点。
caffe程序自带有一张小猫图片,存放路径为caffe根目录下的examples/images/cat.jpg, 如果我们想用一个训练好的caffemodel来对这张图片进行分类,那该怎么办呢? 如果不用这张小猫图片,换一张别的图片,又该怎么办呢?如果学会了小猫图片的分类,那么换成其它图片,程序实际上是一样的。
开发caffe的贾大牛团队,利用imagenet图片和caffenet模型训练好了一个caffemodel,供大家下载。要进行图片的分类,这个caffemodel是最好不过的了。所以,不管是用C++来进行分类,还是用python接口来分类,我们都应该准备这样三个文件:
1. caffemodel文件
可以直接在浏览器里输入地址下载,也可以运行脚本文件下载。下载地址:http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel
文件名称为:bvlc_reference_caffenet.caffemodel,文件大小为230M左右,为了代码的统一,将这个caffemodel文件下载到caffe根目录下的models/bvlc_reference_caffenet/文件夹下面。也可以运行脚本文件进行下载:
|
1 |
$ ./scripts/download_model_binary.py models/bvlc_reference_caffenet |
2. 均值文件
有了caffemodel文件,就需要对应的均值文件,在测试阶段,需要把测试数据减去均值。这个文件我们用脚本来下载,在caffe根目录下执行:
|
1 |
$ sh ./data/ilsvrc12/get_ilsvrc_aux.sh |
执行并下载后,均值文件放在 data/ilsvrc12/ 文件夹里。
3. synset_words.txt文件
在调用脚本文件下载均值的时候,这个文件也一并下载好了。里面放的是1000个类的名称。
数据准备好了,我们就可以开始分类了,我们给大家提供两个版本的分类方法:
一. C++方法
在caffe根目录下的examples/cpp-classification/文件夹下面,有个classification.cpp文件,就是用来分类的。当然编译后,放在/build/examples/cpp_classification/下面
我们就直接运行命令:
|
1 2 3 4 5 6 |
# sudo ./build/examples/cpp_classification/classification.bin \ models/bvlc_reference_caffenet/deploy.prototxt \ models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel \ data/ilsvrc12/imagenet_mean.binaryproto \ data/ilsvrc12/synset_words.txt \ examples/images/cat.jpg |
命令很长,用了很多的\符号来换行。可以看出,从第二行开始就是参数,每行一个,共需要4个参数
运行成功后,输出top-5结果:
|
1 2 3 4 5 6 |
---------- Prediction for examples/images/cat.jpg ---------- 0.3134 - "n02123045 tabby, tabby cat" 0.2380 - "n02123159 tiger cat" 0.1235 - "n02124075 Egyptian cat" 0.1003 - "n02119022 red fox, Vulpes vulpes" 0.0715 - "n02127052 lynx, catamount" |
即有0.3134的概率为tabby cat, 有0.2380的概率为tiger cat ......
二. python方法
python接口可以使用jupyter notebook来进行可视化操作,因此推荐使用这种方法。
在这里我就不用可视化了,编写一个py文件,命名为py-classify.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#coding=utf-8 #加载必要的库 import numpy as np import sys,os #设置当前目录 caffe_root = '/home/xxx/caffe/' sys.path.insert(0, caffe_root + 'python') import caffe os.chdir(caffe_root) net_file=caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt' caffe_model=caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel' mean_file=caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy' net = caffe.Net(net_file,caffe_model,caffe.TEST) transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) transformer.set_transpose('data', (2,0,1)) transformer.set_mean('data', np.load(mean_file).mean(1).mean(1)) transformer.set_raw_scale('data', 255) transformer.set_channel_swap('data', (2,1,0)) im=caffe.io.load_image(caffe_root+'examples/images/cat.jpg') net.blobs['data'].data[...] = transformer.preprocess('data',im) out = net.forward() imagenet_labels_filename = caffe_root + 'data/ilsvrc12/synset_words.txt' labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t') top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1] for i in np.arange(top_k.size): print top_k[i], labels[top_k[i]] |
对于macOS Sierra (10.12.3)来说,需要设置python环境,(参考源代码中的python/requirements.txt),如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#切换到我们自己安装的python版本,系统自带版本会在安装插件时候由于权限问题而失败 $ brew install python #安装必要的python包 $ sudo pip install Cython $ sudo pip install numpy $ sudo pip install scipy #只能安装编译好的包,源代码安装失败 $ sudo pip install scikit-image $ sudo pip install matplotlib $ sudo pip install ipython $ sudo pip install h5py $ sudo pip install leveldb $ sudo pip install networkx $ sudo pip install nose $ sudo pip install pandas $ sudo pip install python-dateutil $ sudo pip install protobuf $ sudo pip install python-gflags $ sudo pip install pyyaml $ sudo pip install Pillow $ sudo pip install six |
执行这个文件,输出:
|
1 2 3 4 5 |
281 n02123045 tabby, tabby cat 282 n02123159 tiger cat 285 n02124075 Egyptian cat 277 n02119022 red fox, Vulpes vulpes 287 n02127052 lynx, catamount |
caffe开发团队实际上也编写了一个python版本的分类文件,路径为 python/classify.py
运行这个文件必需两个参数,一个输入图片文件,一个输出结果文件。而且运行必须在python目录下。假设当前目录是caffe根目录,则运行:
|
1 2 |
$ cd python $ sudo python classify.py ../examples/images/cat.jpg result.npy |
分类的结果保存为当前目录下的result.npy文件里面,是看不见的。而且这个文件有错误,运行的时候,会提示
|
1 |
Mean shape incompatible with input shape |
的错误。因此,要使用这个文件,我们还得进行修改:
1.修改均值计算:
定位到
|
1 |
mean = np.load(args.mean_file) |
这一行,在下面加上一行:
|
1 |
mean=mean.mean(1).mean(1) |
则可以解决报错的问题。
2.修改文件,使得结果显示在命令行下:
定位到
|
1 2 3 4 |
# Classify. start = time.time() predictions = classifier.predict(inputs, not args.center_only) print("Done in %.2f s." % (time.time() - start)) |
这个地方,在后面加上几行,如下所示:
|
1 2 3 4 5 6 7 8 9 |
# Classify. start = time.time() predictions = classifier.predict(inputs, not args.center_only) print("Done in %.2f s." % (time.time() - start)) imagenet_labels_filename = '../data/ilsvrc12/synset_words.txt' labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t') top_k = predictions.flatten().argsort()[-1:-6:-1] for i in np.arange(top_k.size): print top_k[i], labels[top_k[i]] |
就样就可以了。运行不会报错,而且结果会显示在命令行下面。
默认情况下,当你使用WordPress来搭建网站的时候,WordPress会在你的网站上留下个标记:这就是WordPress的版本号。在某些时候,这个标记也会成为网站的安全漏洞。
打开你的WordPress网站,在浏览中的空白地方点击右键,选择查看源代码,通常你会找到有这样一行代码:
|
1 |
<meta name="generator" content="WordPress 4.4.1" /> |
这是WordPress自动生成的代码,向外界宣告你所使用的WordPress版本。如果你的网站一直使用的是最新版WordPress,那你基本无需担心因为泄露版本号而导致的安全问题。但是,由于某些特殊的原因,如果你使用的是旧版本的软件,那么暴露WordPress版本号可能会成为你网站的安全漏洞。
因此,在这种情况下,你应该隐藏网站所使用的WordPress版本号。
在你的网站中,有四个地方容易暴露WordPress的版本号:
meta标签里:RSS feeds中:readme.html文件中。网络中各种隐藏WordPress版本号的技巧很多,功能最为完整且简洁的代码,应当是属于下面这段:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
<?php /* 在 js 文件和 css 文件中隐藏 WordPress 版本号 * @return {string} $src * @filter script_loader_src * @filter style_loader_src */ function wpchina_remove_wp_version_strings( $src ) { global $wp_version; parse_str(parse_url($src, PHP_URL_QUERY), $query); if ( !empty($query['ver']) && $query['ver'] === $wp_version ) { $src = remove_query_arg('ver', $src); } return $src; } add_filter( 'script_loader_src', 'wpchina_remove_wp_version_strings' ); add_filter( 'style_loader_src', 'wpchina_remove_wp_version_strings' ); /* 在 generator meta 标签中隐藏 WordPress版本号 */ function wpchina_remove_version() { return ''; } add_filter('the_generator', 'wpchina_remove_version'); ?> |
这段代码可以移除前面3个地方中所包含的WP版本号。记得要把这段代码放在你所用主题(或子主题)的funcitons.php模板文件中。
修改完成后,如果是使用PHP-FPM来进行处理的服务器,需要重启PHP-FPM服务否则代码可能不能及时生效:
|
1 |
$ sudo service php5-fpm restart |
对于上面第4点提到的,位于WordPress根目录下的readme.html文件,你直接删除该文件就可以了。这份文件是关于WordPress的简单介绍和安装说明,安装好账户就没有什么用途了。
如果使用的是Apache服务器,也可以简单的在根目录下面建立.htaccess文件,里面增加如下内容:
|
1 2 3 4 5 |
# 禁止 readme.html 的访问,这个文件会暴露版本号信息 <Files readme.html> order deny,allow deny from all </Files> |
当然,以上这些做法,隐藏了WordPress的版本号,并不能真正解决网站中所存在的安全漏洞。确保网站安全的第一要素,还是要及时更新WordPress核心软件,所使用的主题、插件;使用健壮的用户名和密码;不要使用来历不明的盗版主题和插件等。
用WordPress比较长的时间了,一直是在首页显示文章全文的,但是最近由于摘抄的某些文章中的图片非常多,导致每次加载首页会下载非常多的图片资源,整个页面加载速度都被拖慢了,于是想只在首页显示摘要,而不是全文显示。
网上搜索了一下,发现WordPress早就有这个功能了,如下图:
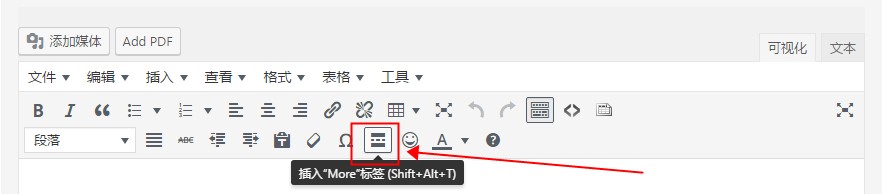
如果想手工编辑Html的话,只要简单的加入
|
1 |
<!--more--> |
标签就可以达到相同的效果了。
这个一般是指QuickTimePlayer,用这种方法对Mac屏幕录像,很多人会反应说“没有声音”,到底是怎么回事呢?让我们使用一遍就知道了。