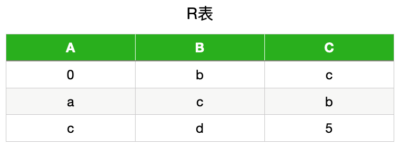
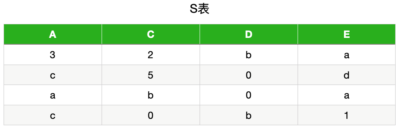
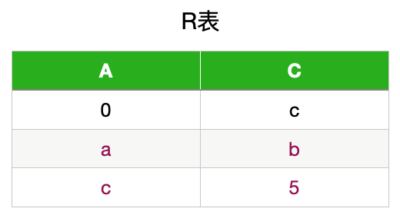
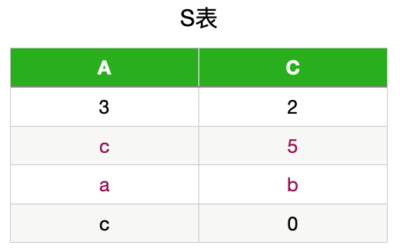
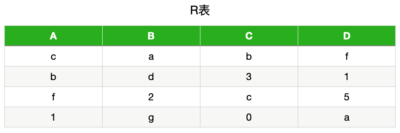
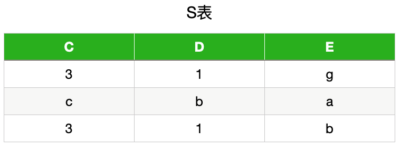
mysql> show collation like 'utf8mb4%';
+----------------------------+---------+-----+---------+----------+---------+---------------+
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
+----------------------------+---------+-----+---------+----------+---------+---------------+
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE |
| utf8mb4_croatian_ci | utf8mb4 | 245 | | Yes | 8 | PAD SPACE |
| utf8mb4_cs_0900_ai_ci | utf8mb4 | 266 | | Yes | 0 | NO PAD |
| utf8mb4_cs_0900_as_cs | utf8mb4 | 289 | | Yes | 0 | NO PAD |
| utf8mb4_czech_ci | utf8mb4 | 234 | | Yes | 8 | PAD SPACE |
| utf8mb4_danish_ci | utf8mb4 | 235 | | Yes | 8 | PAD SPACE |
| utf8mb4_da_0900_ai_ci | utf8mb4 | 267 | | Yes | 0 | NO PAD |
| utf8mb4_da_0900_as_cs | utf8mb4 | 290 | | Yes | 0 | NO PAD |
| utf8mb4_de_pb_0900_ai_ci | utf8mb4 | 256 | | Yes | 0 | NO PAD |
| utf8mb4_de_pb_0900_as_cs | utf8mb4 | 279 | | Yes | 0 | NO PAD |
| utf8mb4_eo_0900_ai_ci | utf8mb4 | 273 | | Yes | 0 | NO PAD |
| utf8mb4_eo_0900_as_cs | utf8mb4 | 296 | | Yes | 0 | NO PAD |
| utf8mb4_esperanto_ci | utf8mb4 | 241 | | Yes | 8 | PAD SPACE |
| utf8mb4_estonian_ci | utf8mb4 | 230 | | Yes | 8 | PAD SPACE |
| utf8mb4_es_0900_ai_ci | utf8mb4 | 263 | | Yes | 0 | NO PAD |
| utf8mb4_es_0900_as_cs | utf8mb4 | 286 | | Yes | 0 | NO PAD |
| utf8mb4_es_trad_0900_ai_ci | utf8mb4 | 270 | | Yes | 0 | NO PAD |
| utf8mb4_es_trad_0900_as_cs | utf8mb4 | 293 | | Yes | 0 | NO PAD |
| utf8mb4_et_0900_ai_ci | utf8mb4 | 262 | | Yes | 0 | NO PAD |
| utf8mb4_et_0900_as_cs | utf8mb4 | 285 | | Yes | 0 | NO PAD |
| utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 | PAD SPACE |
| utf8mb4_german2_ci | utf8mb4 | 244 | | Yes | 8 | PAD SPACE |
| utf8mb4_hr_0900_ai_ci | utf8mb4 | 275 | | Yes | 0 | NO PAD |
| utf8mb4_hr_0900_as_cs | utf8mb4 | 298 | | Yes | 0 | NO PAD |
| utf8mb4_hungarian_ci | utf8mb4 | 242 | | Yes | 8 | PAD SPACE |
| utf8mb4_hu_0900_ai_ci | utf8mb4 | 274 | | Yes | 0 | NO PAD |
| utf8mb4_hu_0900_as_cs | utf8mb4 | 297 | | Yes | 0 | NO PAD |
| utf8mb4_icelandic_ci | utf8mb4 | 225 | | Yes | 8 | PAD SPACE |
| utf8mb4_is_0900_ai_ci | utf8mb4 | 257 | | Yes | 0 | NO PAD |
| utf8mb4_is_0900_as_cs | utf8mb4 | 280 | | Yes | 0 | NO PAD |
| utf8mb4_ja_0900_as_cs | utf8mb4 | 303 | | Yes | 0 | NO PAD |
| utf8mb4_ja_0900_as_cs_ks | utf8mb4 | 304 | | Yes | 24 | NO PAD |
| utf8mb4_latvian_ci | utf8mb4 | 226 | | Yes | 8 | PAD SPACE |
| utf8mb4_la_0900_ai_ci | utf8mb4 | 271 | | Yes | 0 | NO PAD |
| utf8mb4_la_0900_as_cs | utf8mb4 | 294 | | Yes | 0 | NO PAD |
| utf8mb4_lithuanian_ci | utf8mb4 | 236 | | Yes | 8 | PAD SPACE |
| utf8mb4_lt_0900_ai_ci | utf8mb4 | 268 | | Yes | 0 | NO PAD |
| utf8mb4_lt_0900_as_cs | utf8mb4 | 291 | | Yes | 0 | NO PAD |
| utf8mb4_lv_0900_ai_ci | utf8mb4 | 258 | | Yes | 0 | NO PAD |
| utf8mb4_lv_0900_as_cs | utf8mb4 | 281 | | Yes | 0 | NO PAD |
| utf8mb4_persian_ci | utf8mb4 | 240 | | Yes | 8 | PAD SPACE |
| utf8mb4_pl_0900_ai_ci | utf8mb4 | 261 | | Yes | 0 | NO PAD |
| utf8mb4_pl_0900_as_cs | utf8mb4 | 284 | | Yes | 0 | NO PAD |
| utf8mb4_polish_ci | utf8mb4 | 229 | | Yes | 8 | PAD SPACE |
| utf8mb4_romanian_ci | utf8mb4 | 227 | | Yes | 8 | PAD SPACE |
| utf8mb4_roman_ci | utf8mb4 | 239 | | Yes | 8 | PAD SPACE |
| utf8mb4_ro_0900_ai_ci | utf8mb4 | 259 | | Yes | 0 | NO PAD |
| utf8mb4_ro_0900_as_cs | utf8mb4 | 282 | | Yes | 0 | NO PAD |
| utf8mb4_ru_0900_ai_ci | utf8mb4 | 306 | | Yes | 0 | NO PAD |
| utf8mb4_ru_0900_as_cs | utf8mb4 | 307 | | Yes | 0 | NO PAD |
| utf8mb4_sinhala_ci | utf8mb4 | 243 | | Yes | 8 | PAD SPACE |
| utf8mb4_sk_0900_ai_ci | utf8mb4 | 269 | | Yes | 0 | NO PAD |
| utf8mb4_sk_0900_as_cs | utf8mb4 | 292 | | Yes | 0 | NO PAD |
| utf8mb4_slovak_ci | utf8mb4 | 237 | | Yes | 8 | PAD SPACE |
| utf8mb4_slovenian_ci | utf8mb4 | 228 | | Yes | 8 | PAD SPACE |
| utf8mb4_sl_0900_ai_ci | utf8mb4 | 260 | | Yes | 0 | NO PAD |
| utf8mb4_sl_0900_as_cs | utf8mb4 | 283 | | Yes | 0 | NO PAD |
| utf8mb4_spanish2_ci | utf8mb4 | 238 | | Yes | 8 | PAD SPACE |
| utf8mb4_spanish_ci | utf8mb4 | 231 | | Yes | 8 | PAD SPACE |
| utf8mb4_sv_0900_ai_ci | utf8mb4 | 264 | | Yes | 0 | NO PAD |
| utf8mb4_sv_0900_as_cs | utf8mb4 | 287 | | Yes | 0 | NO PAD |
| utf8mb4_swedish_ci | utf8mb4 | 232 | | Yes | 8 | PAD SPACE |
| utf8mb4_tr_0900_ai_ci | utf8mb4 | 265 | | Yes | 0 | NO PAD |
| utf8mb4_tr_0900_as_cs | utf8mb4 | 288 | | Yes | 0 | NO PAD |
| utf8mb4_turkish_ci | utf8mb4 | 233 | | Yes | 8 | PAD SPACE |
| utf8mb4_unicode_520_ci | utf8mb4 | 246 | | Yes | 8 | PAD SPACE |
| utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 8 | PAD SPACE |
| utf8mb4_vietnamese_ci | utf8mb4 | 247 | | Yes | 8 | PAD SPACE |
| utf8mb4_vi_0900_ai_ci | utf8mb4 | 277 | | Yes | 0 | NO PAD |
| utf8mb4_vi_0900_as_cs | utf8mb4 | 300 | | Yes | 0 | NO PAD |
| utf8mb4_zh_0900_as_cs | utf8mb4 | 308 | | Yes | 0 | NO PAD |
+----------------------------+---------+-----+---------+----------+---------+---------------+
75 rows in set (0.01 sec)