开源地址
背景
贝壳找房内部大部分的 App 都已经接入了 Flutter,而且公司在跨端方案的选择上在大力发展 Flutter 生态体系,越来越多的团队也在使用 Flutter,Flutter 虽然能带来高人效和高性能的体验,同时也导致包体积增加,包体积的增加会给我们的推广增大难度,所以我们迫切需要一套针对 Flutter 的通用瘦身方案。
现状:
以一个空工程为例,Flutter 产物主要包含两部分,App.framework 和 Flutter.framework 这两个库,这两个库达到了 16M,对我们的包体积优化会带来不小的压力,所以我们立项了 Thin-Flutter 项目,主要是为了所有 App 提供一套 Flutter 通用的瘦身方案。(由于安卓侧有比较多的手段来实现瘦身,所以本篇文章主要针对 iOS)
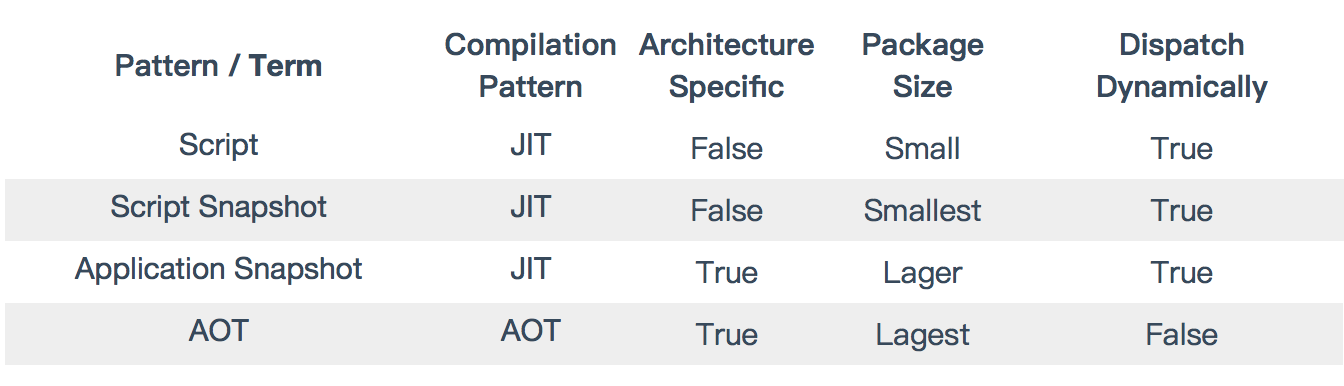
对于包大小问题,Flutter 官方也在持续跟进优化:
我们以贝壳 flutter 产物为例(Flutter SDK : 1.22.4)
App.framework 总大小 20.8M
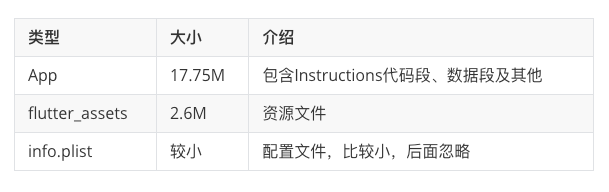
Flutter.framework 总大小 7.7M
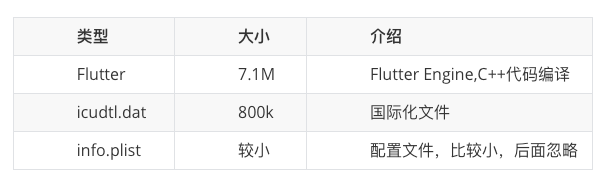
我们先来分析 Flutter 的产物构成,通过对编译命令优化后,产物如下(Release 模式):
App.framework:其中两个文件占比较大,一个是 App 可执行文件,另一个是 flutter_assets. App 可执行文件是 Dart 侧业务代码 AOT 编译的产物,会随着业务量的增多而变大,flutter_assets 包含图片、字体等资源文件。
Flutter.framework: 引擎产物,大小是固定的,但是初始占比比较大。这部分能优化的空间很小,主要是通过裁剪引擎不需要的功能,减少体积。编译引擎时可以选择性编译 skia 和 boringssl,收益大概只有几百 K。
经过对比,iOS 和 Flutter 代码量增长对于包体积的影响是有很大区别的,由于 Flutter 的 Tree Shaking 机制,未被引用的代码都会被裁剪掉,这个机制 iOS 里是没有的,那么这个机制所造成的影响就是 Flutter 包体积在初期会极速增加,到一个临界点包体积的增加会趋于平缓。
贝壳瘦身方案
一、方案调研:
包体积瘦身方法论,大概就三种,要么删减,要么压缩,要么挪走,对于删减 Flutter 自带有 tree-sharking 机制,也就是没有用到的代码会自动裁剪,所以删减不会有太明显的效果,对于压缩,各个团队都会不定时压缩图片,所以不能作为主方案,那么想要有明显的瘦身效果,最好的方面很明显是挪了。下面是一些常用的瘦身方案:
—split-debug-info 可以分离出 debug info
—strip 去除无用符号
—dwarf_stack_trace 表示在生成的动态库文件中,不使用堆栈跟踪符号
—obfuscate 表示混淆,通过减少变量名/方法名的方式减小代码体积
as String/Bool 等等,这类操作会导致 App.framework 体积显著增加,主要是他会增加类型检测及抛出异常的处理逻辑。
Flutter 引擎中包括了 Dart、skia、boringssl、icu、libpng 等多个模块,其中 Dart 和 skia 是必须的,其他模块如果用不到倒是可以考虑裁掉,能够带来几百 k 的瘦身收益。业务方可以根据业务诉求自定义裁剪。
这个不用过多解释,这种直接删代码删资源的方案是最常见的,但投入回报比并不高。
除了给各个业务线分配瘦身指标之外,通过其他方式达到了非常不错的瘦身效果,主要包括以下几方面:
-
去除符号化文件
-
Flutter 产物数据段及资源文件动态下发
-
其他方式:包括去除无用文件、无用资源等
二、具体实现:
贝壳希望有一套长期有效的瘦身方案,以及监控体系,所以贝壳的瘦身方案包括两方面,一是包大小分析及监控,二是通用的,对业务同学无感知的瘦身方案。
1.监控
为了让 Flutter 包大小结构更加一目了然,我们将 Flutter 包大小进行了线上可视化。
首先,我们对 flutter_tools 了修改,在打包过程中我们会收集各个 Flutter 组件中二进制和资源的大小并写入文件(这里的实现我们参考了 flutter_tools 中 analyze_size.dart 的代码),打包完成后会将包大小分析文件上传至服务器;然后,我们在后端对上传的包大小文件进行分析,并将各个组件对应到相应的业务线;最终,我们将分析过后的包大小文件在前端进行展示。除了展示各组件和业务线的大小之外,我们还提供了 Flutter 包大小的对比功能,这样就可以更清晰的看到各个组件和业务线的前后大小变化。
有了包大小的分析,我们就可以根据各业务线和组件的不同情况制定不同的瘦身目标。
与此同时,我们可以对包大小的变化有一个长期的监控,可以及时发觉增量大的组件或者业务方,及时做出调整。
2.瘦身方案
2.1.去除符号化文件
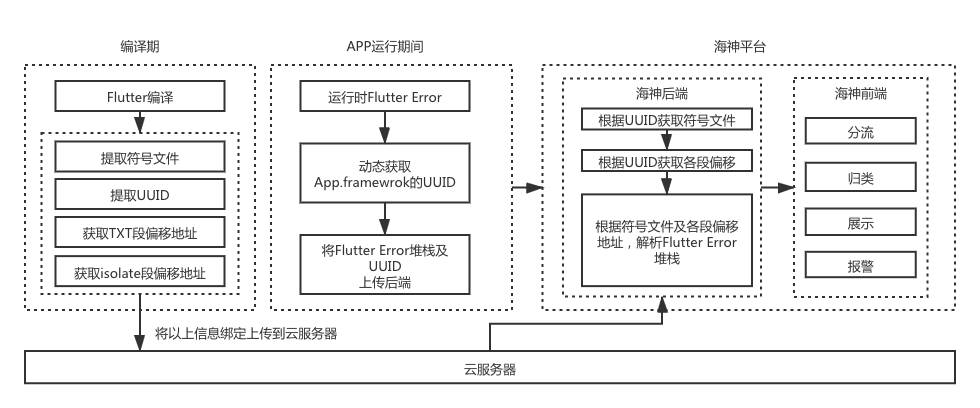
贝壳通过 podspec 注入命令的方式,将 debug 符号信息剥离到指定目录,但这样会产生一个新的问题,Flutter 侧 error 无法解析,因此,我们在编译的同时将符号文件和 uuid 唯一标识绑定上传后端归档,在 App 的 Flutter 页面发生异常时,动态获取当前运行 app App.framework 组件的 uuid 标识,连同异常堆栈上报,后端根据 uuid 匹配符号文件,并解析异常堆栈,这部分可以瘦身 1.3M 左右。
以下是 Flutter error 的解析流程图:
由各个业务方梳理无用页面及无用资源文件、图片压缩等等,其中无用代码及无用资源删减有 2M 的收益,图片压缩有 800k 的收益。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
if File.exist?("./pubspec.yaml") com_script_phase = { :name=>'build dart', :script => <<-DESC #更换SOURCE_ROOT O_SOURCE_ROOT=$SOURCE_ROOT export SOURCE_ROOT=$FLUTTER_APPLICATION_PATH/ios export TREE_SHAKE_ICONS=true export SPLIT_DEBUG_INFO="$FLUTTER_APPLICATION_PATH/ios/Flutter" if [[ $ACTION == "install" ]]; then export CONFIGURATION='Release' fi /bin/sh "$FLUTTER_ROOT/packages/flutter_tools/bin/xcode_backend.sh" build if [ $? -ne 0 ];then exit -1 fi /bin/sh "$FLUTTER_ROOT/packages/flutter_tools/bin/xcode_backend.sh" thin if [ $? -ne 0 ];then exit -1 fi DESC } |
我们完成剪裁以后,还需要进一步研究其他瘦身手段,比如动态下发。
2.2Flutter 产物数据段及资源的动态下发
是否可以将两个动态库 App.framework 和 Flutter.framework 全部动态下发?答案是不行的,原因是由于 iOS 系统的限制,可执行文件是不可以动态下发的。
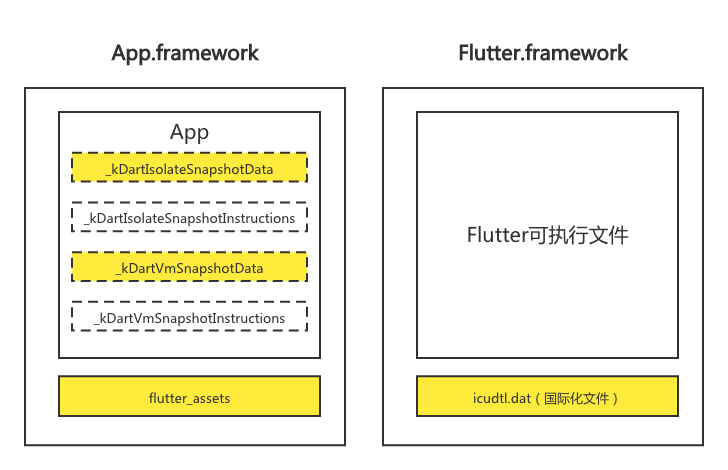
那我们进一步分析,哪些东西是可以动态下发的,哪些东西是不可以动态下发的。参考图 1,首先 flutter_assets 和 icudtl.dat 是资源文件,不存在权限的问题,所以可以动态下发,那么除了这些资源文件,其他部分是否可以动态下发呢?我们接着看。
实现环境:Flutter SDK 2.2.2(目前 Flutter 官方已经发布了 Flutter 2 版本,贝壳也已经适配了 Flutter2.2.2 版本,因此后面基于 Flutter2.2.2 版本进行分析)首先我们看下 Flutter 是如何编译出产物的。
App.framework 的可执行文件经过编译命令优化后,主要由以下四部分构成:
kDartIsolateSnapshotData //代表 Dart 堆的初始状态,并包含 isolate 专属的信息。
kDartVmSnapshotData //代表 isolate 之间共享的 Dart 堆 (heap) 的初始状态。有助于更快地 启动 Dart isolate,但不包含任何 isolate 专属的信息。
kDartIsolateSnapshotInstructions //包含由 Dart isolate 执行的 AOT 代码。
kDartVmSnapshotInstructions //包含 VM 中所有 Dart isolate 之间共享的通用例程的 AOT 指令。这种快照的体积通常非常小,并且大多会包含程序桩 (stub)。
首先了解下什么是 isolate,DartVM 采用了所谓快照的方式,即 JIT 运行时编译后的基本结构与 AOT 编译的基本结构相同。将类信息、全局变量、函数指令直接以序列化的方式存在磁盘中,称为 Snapshot(快照)。同一个进程里可以有很多 isolate,但两个 isolate 的堆区是不能共享的,所以官方设计了 VM isolate,也就是 kDartVmSnapshot,用来多个 isolate 之间的交互。kDartVmSnapshot 分为指令段和数据段,对应上面的 kDartVmSnapshotData 和 kDartVmSnapshotInstructions,内置在 App.framework 里。具体关系如图:
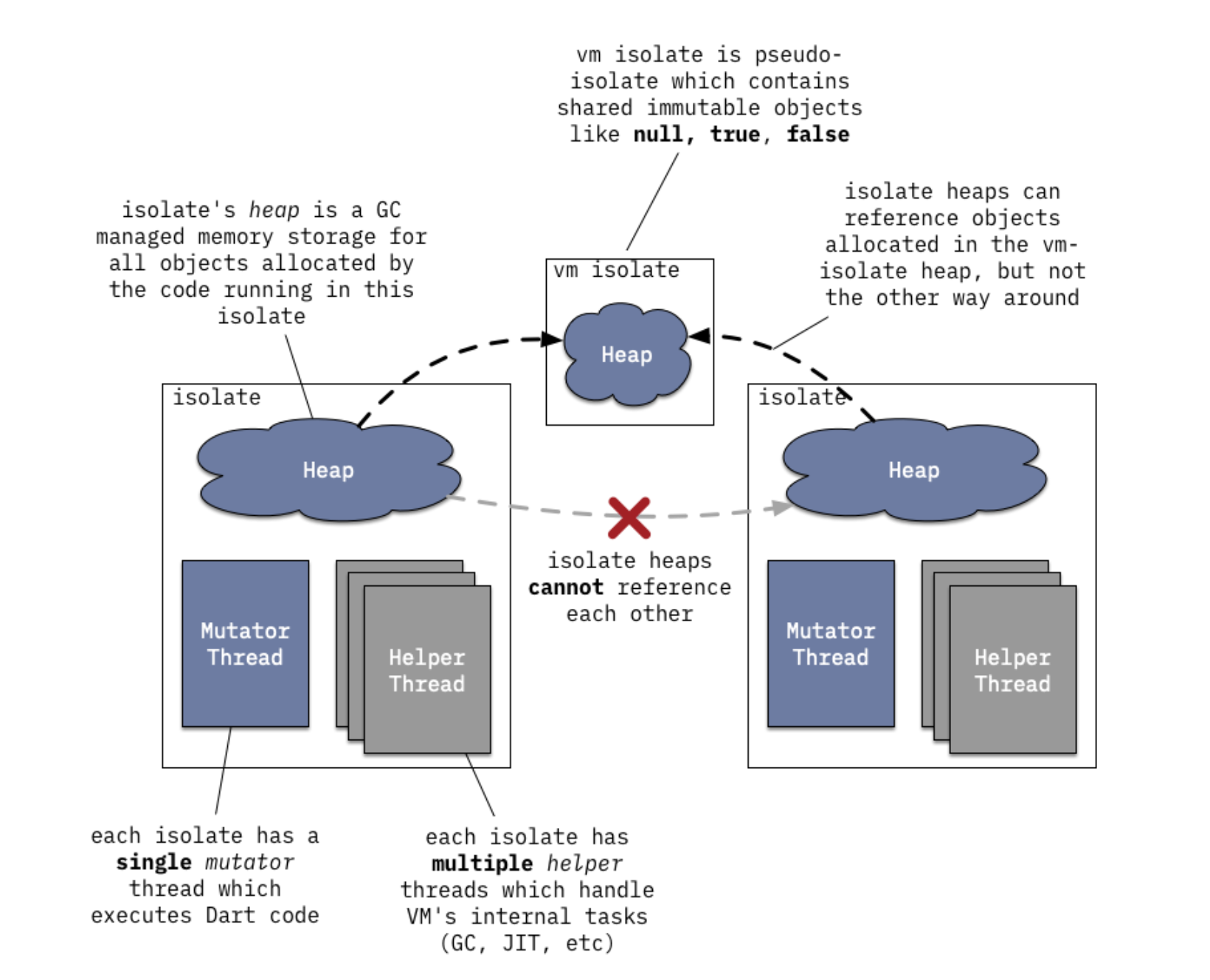
而 isolate 对应的就是 kDartIsolateSnapshot,同样也分为指令段和数据段,对应上面的 kDartIsolateSnapshotData 和 kDartIsolateSnapshotInstructions。
官方文档解释 From the VM's perspective, this just needs to be loaded in memory with READ permissions and does not need WRITE or EXECUTE permissions. Practically this means it should end up in rodata when putting the snapshot in a shared library.
iOS 系统是不允许动态下发可执行二进制代码的,但 kDartIsolateSnapshotData 和 kDartVmSnapshotData 两个数据段的加载是不受系统限制的,所以我们要针对这两部分(上图黄色部分),制定具体的分离方案以及加载方案。
2.2.1、如何分离数据段并回写到磁盘
从上图可以看出 gen_snapshot 为 Dart 编译器,编译后的产物 snapshot_assembly.S 文件再根据不同的平台,编译出不通平台的产物。
分离数据段分为两部分:
-
将数据段回写到磁盘上,放入云端服务器动态下发。
-
将数据段从 App.framework 中剔除,达到瘦身效果
我们从 gen_snapshot 入手,将数据段产物剥离出来。具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
MaybeLoadCode(); //根据不同模式,编译不同的产物 switch (snapshot_kind) { case kCore: CreateAndWriteCoreSnapshot(); break; case kCoreJIT: CreateAndWriteCoreJITSnapshot(); break; case kApp: CreateAndWriteAppSnapshot(); break; case kAppJIT: //JIT模式也就是平时的debug模式编译流程 CreateAndWriteAppJITSnapshot(); break; case kAppAOTAssembly: case kAppAOTElf: //经过验证release模式下的编译流程 CreateAndWritePrecompiledSnapshot(); break; case kVMAOTAssembly: { File* file = OpenFile(assembly_filename); RefCntReleaseScope<File> rs(file); result = Dart_CreateVMAOTSnapshotAsAssembly(StreamingWriteCallback, file); CHECK_RESULT(result); break; } default: UNREACHABLE(); } |
经过验证,release 模式下走的是 CreateAndWritePrecompiledSnapshot 编译流程,因此我们将其改造,将数据段回写到磁盘,需要重写 CreateAppAOTSnapshotAsAssembly 方法。至于回写文件,我们发现 debug 模式下会使用 WriteFile 方法写入文件,这里仿照 debug 模式,将回传的数据段写入./ios/Flutter/Resource/路径下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
static void CreateAndWritePrecompiledSnapshot() { ASSERT(IsSnapshottingForPrecompilation()); Dart_Handle result; // Precompile with specified embedder entry points result = Dart_Precompile(); CHECK_RESULT(result); // Create a precompiled snapshot. if (snapshot_kind == kAppAOTAssembly) { if (strip && (debugging_info_filename == nullptr)) { Syslog::PrintErr( "Warning: Generating assembly code without DWARF debugging" " information.\n"); } if (loading_unit_manifest_filename == nullptr) { File* file = OpenFile(assembly_filename); RefCntReleaseScope<File> rs(file); File* debug_file = nullptr; if (debugging_info_filename != nullptr) { debug_file = OpenFile(debugging_info_filename); } //在flutter编译目录下创建Resource目录,用于存放数据段产物 FILE *fp = NULL; fp = fopen("./ios/Flutter/Resource/", "w"); if (!fp) { mkdir("./ios/Flutter/Resource/", 0775); } else { fclose(fp); } //创建data_buffer对象用于回写数据段 uint8_t* vm_snapshot_data_buffer = NULL; intptr_t vm_snapshot_data_size = 0; uint8_t* isolate_snapshot_data_buffer = NULL; intptr_t isolate_snapshot_data_size = 0; //对Dart_CreateAppAOTSnapshotAsAssembly方法改造,将数据 段回写到磁盘上 result = Dart_CreateAppAOTSnapshotAsAssembly( &vm_snapshot_data_buffer, &vm_snapshot_data_size, &isolate_snapshot_data_buffer, &isolate_snapshot_data_size, StreamingWriteCallback, file, strip, debug_file); //写入isolate_snapshot_data数据段 WriteFile("./ios/Flutter/Resource/isolate_snapshot_data", isolate_snapshot_data_buffer, isolate_snapshot_data_size); //写入vm_snapshot_data数据段 WriteFile("./ios/Flutter/Resource/vm_snapshot_data", vm_snapshot_data_buffer, vm_snapshot_data_size); if (debug_file != nullptr) debug_file->Release(); CHECK_RESULT(result); } else { } ..... 此处省略无关代码 ....... } |
Dart_CreateAppAOTSnapshotAsAssembly 具体实现为在 dart_api_impl.cc 文件,gen_snapshot 编译器会将 dart 代码编译为 snapshot_assembly.S 文件,而 snapshot_assembly.S 文件实际上就包含了
kDartIsolateSnapshotData //数据段
kDartVmSnapshotData //数据段
kDartIsolateSnapshotInstructions //代码段
kDartVmSnapshotInstructions //代码段
这几部分。那么我们找到如何将数据段和代码段写入 snapshot_assembly.S 文件,把数据段分离出来不就可以了吗?我们在 FullSnapshotWriter 里发现了整个 snapshot_assembly.S 的写入过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
DART_EXPORT Dart_Handle //增加四个参数用于回写数据段 Dart_CreateAppAOTSnapshotAsAssembly(uint8_t** vm_snapshot_data_buffer, intptr_t* vm_snapshot_data_size, uint8_t** isolate_snapshot_data_buffer, intptr_t* isolate_snapshot_data_size, Dart_StreamingWriteCallback callback, void* callback_data, bool strip, void* debug_callback_data) { #if defined(TARGET_ARCH_IA32) return Api::NewError("AOT compilation is not supported on IA32."); #elif defined(TARGET_OS_WINDOWS) return Api::NewError("Assembly generation is not implemented for Windows."); #elif !defined(DART_PRECOMPILER) return Api::NewError( "This VM was built without support for AOT compilation."); #else DARTSCOPE(Thread::Current()); API_TIMELINE_DURATION(T); CHECK_NULL(callback); // Mark as not split. T->isolate_group()->object_store()->set_loading_units(Object::null_array()); GrowableArray<LoadingUnitSerializationData*>* units = nullptr; LoadingUnitSerializationData* unit = nullptr; uint32_t program_hash = 0; const bool generate_debug = debug_callback_data != nullptr; ZoneWriteStream vm_snapshot_data(T->zone(), FullSnapshotWriter::kInitialSize); ZoneWriteStream vm_snapshot_instructions(T->zone(), kInitialSize); ZoneWriteStream isolate_snapshot_data(T->zone(), FullSnapshotWriter::kInitialSize); ZoneWriteStream isolate_snapshot_instructions(T->zone(), kInitialSize); StreamingWriteStream assembly_stream(kAssemblyInitialSize, callback, callback_data); StreamingWriteStream debug_stream(generate_debug ? kInitialDebugSize : 0, callback, debug_callback_data); auto const elf = generate_debug ? new (Z) Elf(Z, &debug_stream, Elf::Type::DebugInfo, new (Z) Dwarf(Z)) : nullptr; AssemblyImageWriter image_writer(T, &assembly_stream, strip, elf); FullSnapshotWriter writer(Snapshot::kFullAOT, &vm_snapshot_data, &isolate_snapshot_data, &image_writer, &image_writer); if (unit == nullptr || unit->id() == LoadingUnit::kRootId) { writer.WriteFullSnapshot(units); } else { writer.WriteUnitSnapshot(units, unit, program_hash); } image_writer.Finalize(); //数据段大小与buffer *vm_snapshot_data_buffer = vm_snapshot_data.buffer(); *vm_snapshot_data_size = vm_snapshot_data.bytes_written(); *isolate_snapshot_data_buffer = isolate_snapshot_data.buffer(); *isolate_snapshot_data_size = isolate_snapshot_data.bytes_written(); return Api::Success(); #endif } |
到这一步我们已经将数据段回写到磁盘上了,Resource 下成功写入了两个数据段产物,如下图:
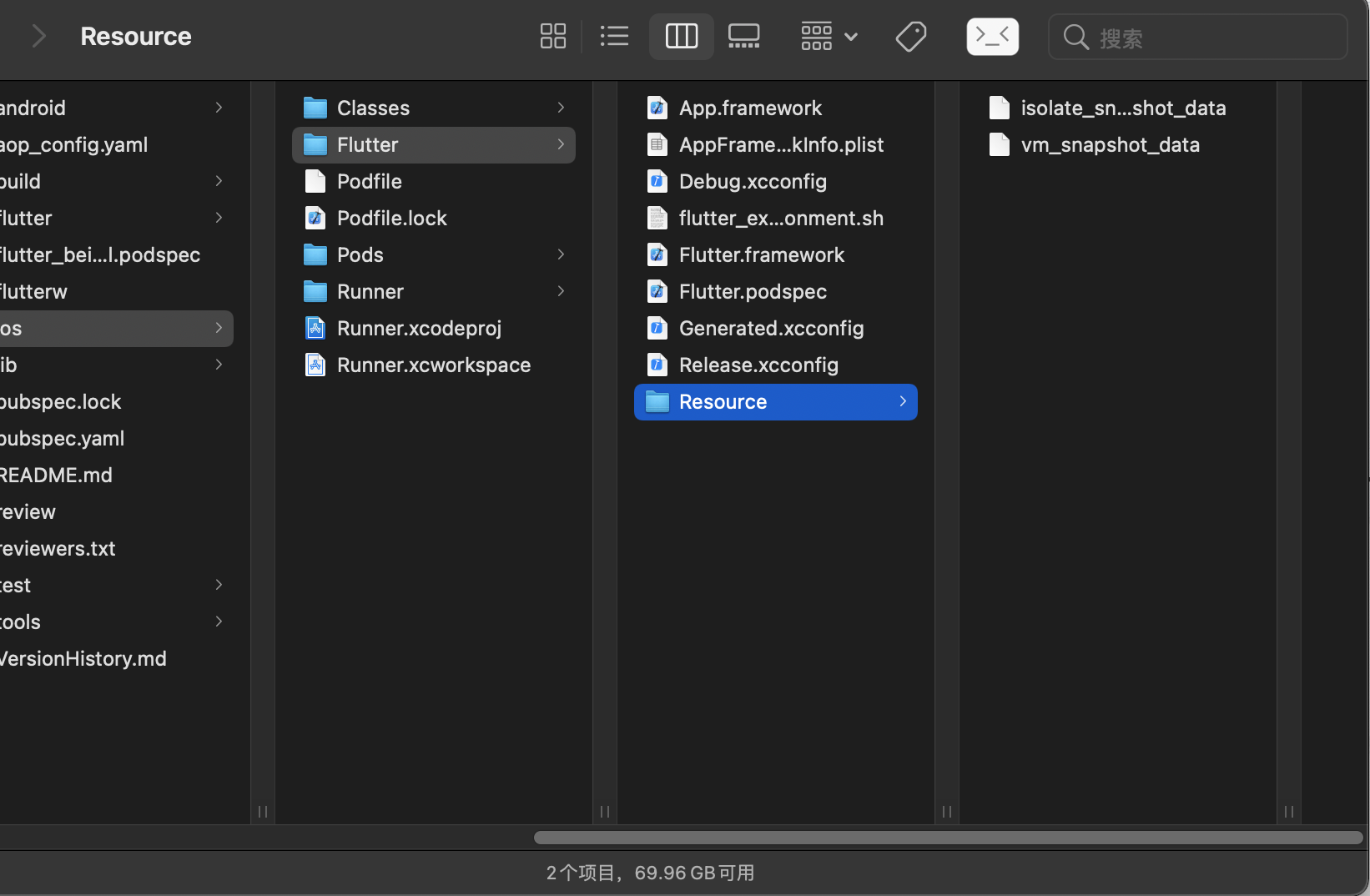
2.2.2、将数据段从可执行文件中剔除
同理,找到写入数据段的位置,将其剔除,我们本着改动量最小的原则,分析原有写入逻辑,发现源码里已经将不同符号类型的数据归类,那么顺着原有逻辑,在写入符号的时候,将数据段类型剔除即可。具体源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
//判断符号类型 const char* ImageWriter::SectionSymbol(ProgramSection section, bool vm) const { switch (section) { case ProgramSection::Text: return vm ? kVmSnapshotInstructionsAsmSymbol : kIsolateSnapshotInstructionsAsmSymbol; case ProgramSection::Data: return vm ? kVmSnapshotDataAsmSymbol : kIsolateSnapshotDataAsmSymbol; case ProgramSection::Bss: return vm ? kVmSnapshotBssAsmSymbol : kIsolateSnapshotBssAsmSymbol; case ProgramSection::BuildId: return kSnapshotBuildIdAsmSymbol; } return nullptr; } // void AssemblyImageWriter::WriteROData(NonStreamingWriteStream* clustered_stream, bool vm) { ImageWriter::WriteROData(clustered_stream, vm); if (!EnterSection(ProgramSection::Data, vm, ImageWriter::kRODataAlignment)) { return; } WriteBytes(clustered_stream->buffer(), clustered_stream->bytes_written()); ExitSection(ProgramSection::Data, vm, clustered_stream->bytes_written()); } bool AssemblyImageWriter::EnterSection(ProgramSection section, bool vm, intptr_t alignment) { ASSERT(FLAG_precompiled_mode); ASSERT(current_section_symbol_ == nullptr); bool global_symbol = false; switch (section) { case ProgramSection::Text: assembly_stream_->WriteString(".text\n"); global_symbol = true; break; case ProgramSection::Data: #if defined(TARGET_OS_LINUX) || defined(TARGET_OS_ANDROID) || \ defined(TARGET_OS_FUCHSIA) assembly_stream_->WriteString(".section .rodata\n"); #elif defined(TARGET_OS_MACOS) || defined(TARGET_OS_MACOS_IOS) assembly_stream_->WriteString(".const\n"); #else UNIMPLEMENTED(); #endif global_symbol = true; break; case ProgramSection::Bss: assembly_stream_->WriteString(".bss\n"); break; case ProgramSection::BuildId: break; } current_section_symbol_ = SectionSymbol(section, vm); ASSERT(current_section_symbol_ != nullptr); //SectionSymbol方法返回current_section_symbol对象是否是数据段类型,若为true,则返回false不写入。注:strcmp(str1,str2),若str1=str2,则返回零;若str1<str2,则返回负数;若str1>str2,则返回正数。 if (strcmp(current_section_symbol_, kVmSnapshotDataAsmSymbol) == 0 || strcmp(current_section_symbol_, kIsolateSnapshotDataAsmSymbol) == 0) { return false; } if (global_symbol) { assembly_stream_->Printf(".globl %s\n", current_section_symbol_); } Align(alignment); assembly_stream_->Printf("%s:\n", current_section_symbol_); return true; } |
通过 nm 命令验证 App 文件中是否只剩下代码段:

对比剥离之前:
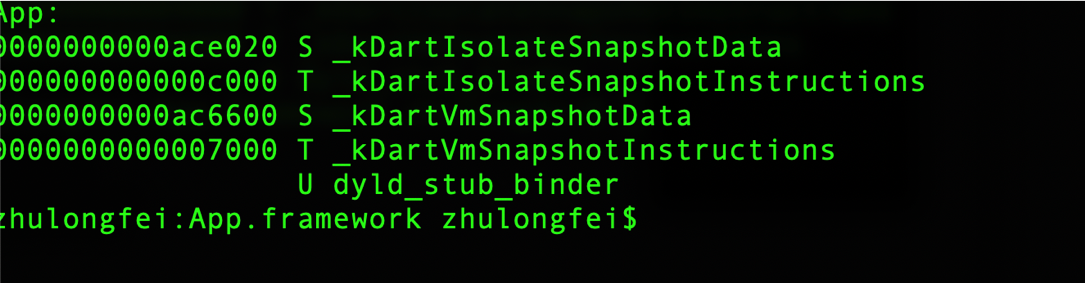
数据段剥离之后,也就完成了我们瘦身的目的,但是 App 运行时,没有数据段是不行的,会造成 App 崩溃,因此我们还需要一套完善的方案,来保证数据段从远端下发之后,安全的被加载。
2.2.3、如何加载分离后的数据段
我们来看下加载流程

Flutter 引擎启动的时候,会创建 DartVM,同时加载可执行文件中的代码段和数据段。具体方法可追溯到 ResolveVMData、ResolveVMInstructions、ResolveIsolateData、ResolveIsolateInstructions 等四个方法,分别加载了数据段与代码段,而这四个方法都指向了同一个方法,也就是 SearchMapping 方法,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
static std::shared_ptr<const fml::Mapping> ResolveVMData( const Settings& settings) { #if DART_SNAPSHOT_STATIC_LINK return std::make_unique<fml::NonOwnedMapping>(kDartVmSnapshotData, 0); #else // DART_SNAPSHOT_STATIC_LINK return SearchMapping( settings.vm_snapshot_data, // embedder_mapping_callback settings.vm_snapshot_data_path, // file_path settings.application_library_path, // native_library_path DartSnapshot::kVMDataSymbol, // native_library_symbol_name false // is_executable ); #endif // DART_SNAPSHOT_STATIC_LINK } static std::shared_ptr<const fml::Mapping> ResolveVMInstructions( const Settings& settings) { #if DART_SNAPSHOT_STATIC_LINK return std::make_unique<fml::NonOwnedMapping>(kDartVmSnapshotInstructions, 0); #else // DART_SNAPSHOT_STATIC_LINK return SearchMapping( settings.vm_snapshot_instr, // embedder_mapping_callback settings.vm_snapshot_instr_path, // file_path settings.application_library_path, // native_library_path DartSnapshot::kVMInstructionsSymbol, // native_library_symbol_name true // is_executable ); #endif // DART_SNAPSHOT_STATIC_LINK } static std::shared_ptr<const fml::Mapping> ResolveIsolateData( const Settings& settings) { #if DART_SNAPSHOT_STATIC_LINK return std::make_unique<fml::NonOwnedMapping>(kDartIsolateSnapshotData, 0); #else // DART_SNAPSHOT_STATIC_LINK return SearchMapping( settings.isolate_snapshot_data, // embedder_mapping_callback settings.isolate_snapshot_data_path, // file_path settings.application_library_path, // native_library_path DartSnapshot::kIsolateDataSymbol, // native_library_symbol_name false // is_executable ); #endif // DART_SNAPSHOT_STATIC_LINK } static std::shared_ptr<const fml::Mapping> ResolveIsolateInstructions( const Settings& settings) { #if DART_SNAPSHOT_STATIC_LINK return std::make_unique<fml::NonOwnedMapping>( kDartIsolateSnapshotInstructions, 0); #else // DART_SNAPSHOT_STATIC_LINK return SearchMapping( settings.isolate_snapshot_instr, // embedder_mapping_callback settings.isolate_snapshot_instr_path, // file_path settings.application_library_path, // native_library_path DartSnapshot::kIsolateInstructionsSymbol, // native_library_symbol_name true // is_executable ); #endif // DART_SNAPSHOT_STATIC_LINK } |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
static std::shared_ptr<const fml::Mapping> SearchMapping( MappingCallback embedder_mapping_callback, const std::string& file_path, const std::vector<std::string>& native_library_path, const char* native_library_symbol_name, bool is_executable) { // Ask the embedder. There is no fallback as we expect the embedders (via // their embedding APIs) to just specify the mappings directly. if (embedder_mapping_callback) { return embedder_mapping_callback(); } //从settings.vm_snapshot_data_path或settings.isolate_snapshot_data_path加载 // Attempt to open file at path specified. if (file_path.size() > 0) { if (auto file_mapping = GetFileMapping(file_path, is_executable)) { return file_mapping; } } // 从 settings.application_library_path 中加载 // Look in application specified native library if specified. for (const std::string& path : native_library_path) { auto native_library = fml::NativeLibrary::Create(path.c_str()); auto symbol_mapping = std::make_unique<const fml::SymbolMapping>( native_library, native_library_symbol_name); if (symbol_mapping->GetMapping() != nullptr) { return symbol_mapping; } } // 从native_library_symbol_name加载 { auto loaded_process = fml::NativeLibrary::CreateForCurrentProcess(); auto symbol_mapping = std::make_unique<const fml::SymbolMapping>( loaded_process, native_library_symbol_name); if (symbol_mapping->GetMapping() != nullptr) { return symbol_mapping; } } return nullptr; } |
从 SearchMapping 方法中可以判断,加载顺序为,先从 settings.vm_snapshot_data 或 settings.isolate_snapshot_data 加载,若不存在则从 settings.vm_snapshot_data_path 或 settings.isolate_snapshot_data_path 读取,再然后从 settings.application_library_path 中加载。
那么如果我们篡改 settings.vm_snapshot_data_path 和 settings.isolate_snapshot_data_path 的指向,是否可以将我们本地的数据段正确加载呢?答案是肯定的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
struct Settings { Settings(); Settings(const Settings& other); ~Settings(); // VM settings std::string vm_snapshot_data_path; // deprecated MappingCallback vm_snapshot_data; std::string vm_snapshot_instr_path; // deprecated MappingCallback vm_snapshot_instr; std::string isolate_snapshot_data_path; // deprecated MappingCallback isolate_snapshot_data; std::string isolate_snapshot_instr_path; // deprecated MappingCallback isolate_snapshot_instr; std::string assets_path; //flutter_assets路径 std::string icu_data_path; //icu_data国际化路径 .... 此部分省略 .... } |
从上面的加载流程图里可以看出来 Setting 类的初始化是在 FlutterDartProject 类里。我们在 FlutterDartProject 重设数据段路径、flutter_assets 路径和 icu_data 国际化文件路径。
首先我们在 App 启动时将分离产物下载到沙盒内的指定路径下:Document/flutter_resource/Resource/*
然后将 setting 类中 path 指定到此路径下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
NSLog(@"开始设置路径"); //设置沙盒路径 NSArray * documentPaths = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES); NSString * documentDirectory = [documentPaths objectAtIndex:0]; //设置vm_snapshot_data路径 NSString *vm_snapshot_data_path = [NSString stringWithFormat:@"%@/flutter_resource/Resource/vm_snapshot_data",documentDirectory]; if ([[NSFileManager defaultManager] fileExistsAtPath:vm_snapshot_data_path]) { settings.vm_snapshot_data_path = vm_snapshot_data_path.UTF8String; } //设置isolate_snapshot_data路径 NSString *isolate_snapshot_data_path = [NSString stringWithFormat:@"%@/flutter_resource/Resource/isolate_snapshot_data",documentDirectory]; if ([[NSFileManager defaultManager] fileExistsAtPath:isolate_snapshot_data_path]) { settings.isolate_snapshot_data_path = isolate_snapshot_data_path.UTF8String; } //设置资源路径 NSString *assets_path = [NSString stringWithFormat:@"%@/flutter_resource/Resource/flutter_assets",documentDirectory]; if ([[NSFileManager defaultManager] fileExistsAtPath:assets_path]) { settings.assets_path = assets_path.UTF8String; } else { NSString* assetsName = [FlutterDartProject flutterAssetsName:bundle]; NSString* assetsPath = [bundle pathForResource:assetsName ofType:@""]; if (assetsPath.length == 0) { assetsPath = [mainBundle pathForResource:assetsName ofType:@""]; } if (assetsPath.length == 0) { NSLog(@"Failed to find assets path for \"%@\"", assetsName); } else { settings.assets_path = assetsPath.UTF8String; } } //设置icu_data_path NSString *icu_data_path = [NSString stringWithFormat:@"%@/flutter_resource/Resource/icudtl.dat",documentDirectory]; if ([[NSFileManager defaultManager] fileExistsAtPath:icu_data_path]) { settings.icu_data_path = icu_data_path.UTF8String; } else { NSString* icuDataPath = [engineBundle pathForResource:@"icudtl" ofType:@"dat"]; if (icuDataPath.length > 0) { settings.icu_data_path = icuDataPath.UTF8String; } } if ([[NSFileManager defaultManager] fileExistsAtPath:vm_snapshot_data_path] && [[NSFileManager defaultManager] fileExistsAtPath:isolate_snapshot_data_path] ) { NSLog(@"data存在"); } else { NSLog(@"data不存在"); } NSLog(@"路径设置完毕"); |
设置完成以后,DartVM 启动所需要的各种资源与二进制就可以正常加载了。
工程化落地
有了初步的瘦身方案,具体落地还需要很多配套措施,比如持续集成,私有云及监控体系。
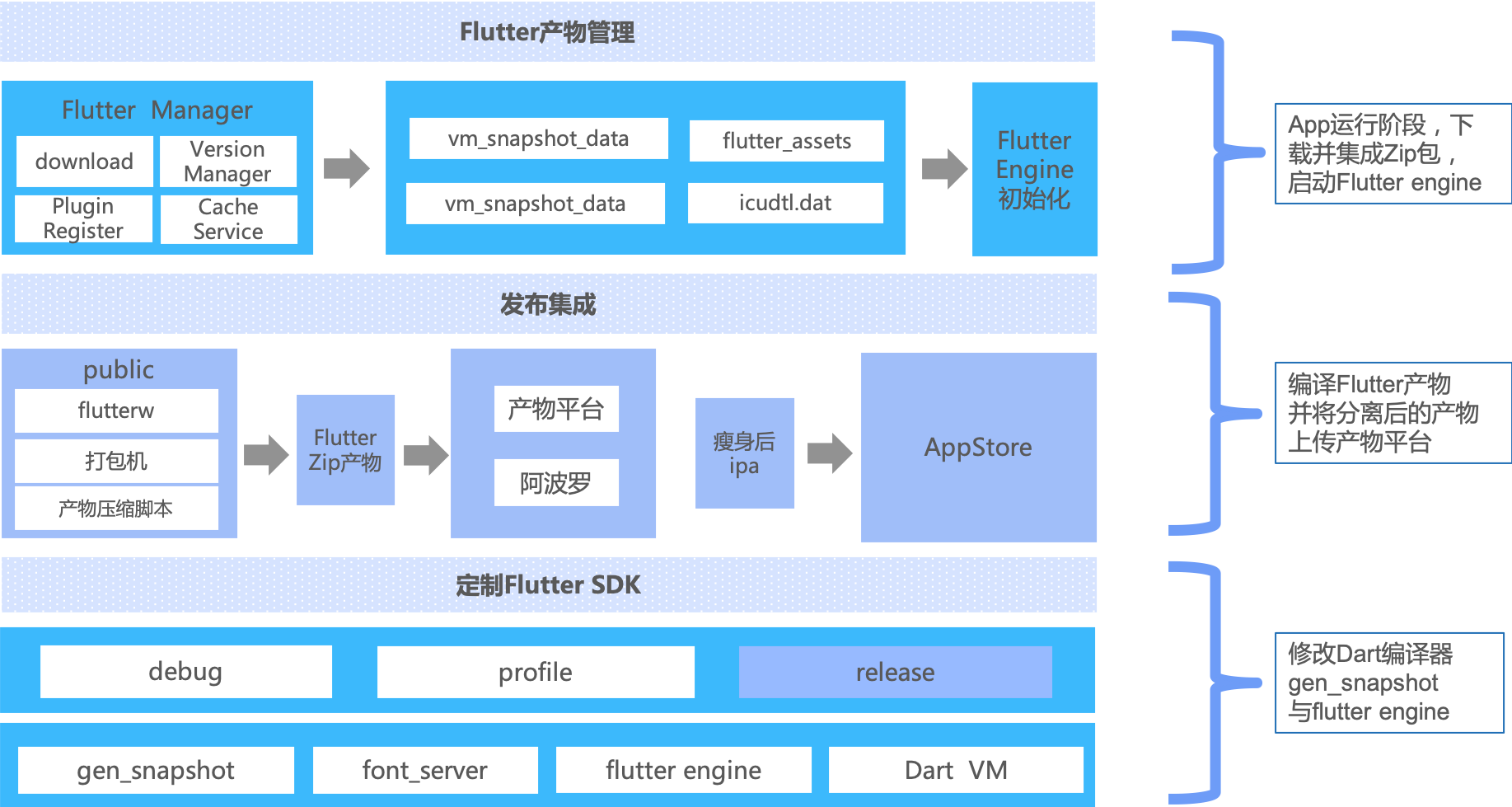
工程化落地主要包括三部分:
第一部分:定制 Flutter SDK
一、将 Flutter.framework 文件和 gen_snapshot 文件进行归档,同时需要制作 dSYM 符号表文件。
iOS 提供了两个工具,一个是用于 Flutter.framework 的规定及符号表导出,另一个是用于 gen_snapshot 文件的归档,他们位于 engine/src/flutter/sky/tools/create_ios_framework.py 和 engine/src/flutter/sky/tools/create_macos_gen_snapshots.py。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
cd /path/to/engine/src ./flutter/sky/tools/create_ios_framework.py \ --arm64-out-dir /path/engine/src/out/ios_release \ --armv7-out-dir /path/engine/src/out/ios_release_arm \ --simulator-out-dir /path/engine/src/out/ios_debug_sim \ --dst /path/engine/src/out/flutter-engine/artifacts/ios-release \ --strip --dsym ./flutter/sky/tools/create_ios_framework.py \ --arm64-out-dir /path/engine/src/out/ios_profile \ --armv7-out-dir /path/engine/src/out/ios_profile_arm \ --simulator-out-dir /path/engine/src/out/ios_debug_sim \ --dst /path/engine/src/out/flutter-engine/artifacts/ios-profile \ --dsym ./flutter/sky/tools/create_ios_framework.py \ --arm64-out-dir /path/engine/src/out/ios_debug \ --armv7-out-dir /path/engine/src/out/ios_debug_arm \ --simulator-out-dir /path/engine/src/out/ios_debug_sim \ --dst /path/engine/src/out/flutter-engine/artifacts/ios \ --dsym ./flutter/sky/tools/create_macos_gen_snapshots.py \ --arm64-out-dir /path/engine/src/out/ios_release \ --armv7-out-dir /path/engine/src/out/ios_release_arm \ --dst /path/engine/src/out/flutter-engine/artifacts/ios-release ./flutter/sky/tools/create_macos_gen_snapshots.py \ --arm64-out-dir /path/engine/src/out/ios_profile \ --armv7-out-dir /path/engine/src/out/ios_profile_arm \ --dst /path/engine/src/out/flutter-engine/artifacts/ios-profile ./flutter/sky/tools/create_macos_gen_snapshots.py \ --arm64-out-dir /path/engine/src/out/ios_debug \ --armv7-out-dir /path/engine/src/out/ios_debug_arm \ --dst /path/engine/src/out/flutter-engine/artifacts/ios |
最终如图所示
ios-release 文件夹就是我们我最终改造完的产物,接下来就是定制 sdk 了。
实际上 Flutter sdk 里会根据不同的平台,不同的 build model 选择不同的编译器和 Flutter engine,如下图所示:
我们只需要把刚刚归档出来的 ios-release 替换 Flutter sdk 里的 ios-release 文件夹,之后 release 模式下打 iOS 产物,App.framework 就会是剥离出数据段的产物。
二、结合 flutterw 部署定制 sdk
由于目前公司 Flutter sdk 存在多个版本,比如 1.12.13、1.22.4 等,因此我们开发了 Flutter sdk 自动化管理工具 flutterw,可以根据项目的不同配置,切换不同的 Flutter sdk,包括官方 sdk,并且自动同步官方新版本。因此我们借助 flutterw 的能力,部署定制的 Flutter sdk,在有瘦身需求的项目里配置 sdk 版本即可。
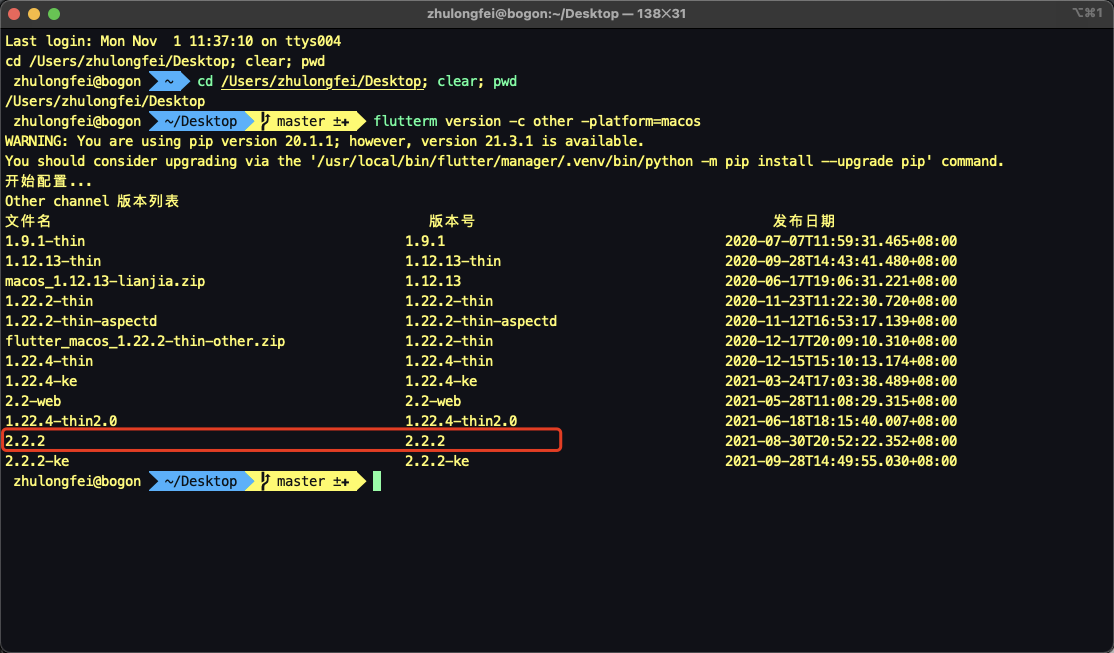
首先发布定制 sdk:
|
|
$ flutterm upload -l /path/flutter -n 2.2.2 -c other -v 2.2.2 --platform macos |
结果如图:
接着在对应的项目中配置相应的 flutter sdk 版本,如下图:
三、改造 xcode_backend.sh 编译脚本,将数据段、资源包等压缩
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
ljEmbedFlutterFrameworks() { project_path=$1 if [ ! -d "${project_path}/ios/Flutter" ]; then return 0 fi local build_product_path="${project_path}/ios/Flutter" local app_framewok_path="${build_product_path}/App.framework" local thin_resource_zip="${app_framewok_path}/flutter_resource.zip" local thin_uuid_txt="${app_framewok_path}/uuid_app.txt" local flutter_framewok_path="${build_product_path}/Flutter.framework" RunCommand cp -rf "${BUILT_PRODUCTS_DIR}/App.framework" "${build_product_path}" RunCommand cp -rf "${BUILT_PRODUCTS_DIR}/Flutter.framework" "${build_product_path}" #当前编译uuid local uuid=`dwarfdump -u --arch=$ARCHS "${app_framewok_path}/App" | awk -F ' ' '{print $2}'` echo $uuid local old_uuid="" #判断上一步产物uuid是否一致 if [ -f $thin_uuid_txt ];then old_uuid=$(cat $thin_uuid_txt); fi local tmep_assets_path="$app_framewok_path/flutter_assets" if [[ $uuid != "" && $uuid == $old_uuid ]];then if [ -f "${tmep_assets_path}/NOTICES" ];then RunCommand rm -rf "${tmep_assets_path}/NOTICES" fi if [ -d "${tmep_assets_path}/fonts" ];then RunCommand rm -rf "${tmep_assets_path}/fonts" fi unzip -o $thin_resource_zip -d $build_product_path if [ -d $tmep_assets_path ];then if [ -d "$build_product_path/Resource/flutter_assets" ];then RunCommand rm -rf "$build_product_path/Resource/flutter_assets" fi RunCommand cp -rf $tmep_assets_path "$build_product_path/Resource" fi local temp_resource_zip="$build_product_path/flutter_resource.zip" RunCommand cd ${build_product_path} && zip -r flutter_resource.zip ./Resource RunCommand cd ${build_product_path} && zip -r $thin_resource_zip ./Resource RunCommand cp -rf $temp_resource_zip $app_framewok_path RunCommand rm -rf $tmep_assets_path RunCommand rm -rf $temp_resource_zip RunCommand rm -rf "$build_product_path/Resource" RunCommand rm -rf "$flutter_framewok_path/icudtl.dat" else if [[ ${thin_resource} != "" && -d ${thin_resource} ]];then if [ -f "${tmep_assets_path}/NOTICES" ];then RunCommand rm -rf "${tmep_assets_path}/NOTICES" fi if [ -d "${tmep_assets_path}/fonts" ];then RunCommand rm -rf "${tmep_assets_path}/fonts" fi RunCommand cp -rf ${tmep_assets_path} ${thin_resource} if [ -f "$flutter_framewok_path/icudtl.dat" ];then RunCommand cp -f "$flutter_framewok_path/icudtl.dat" ${thin_resource} fi uuid=`dwarfdump -u --arch=arm64 "${app_framewok_path}/App" | awk -F ' ' '{print $2}'` echo ${uuid}>"$thin_uuid_txt" local temp_resource_zip="$build_product_path/flutter_resource.zip" RunCommand cd ${build_product_path} && zip -r flutter_resource.zip ./Resource RunCommand cp -f $temp_resource_zip $app_framewok_path RunCommand rm -rf $tmep_assets_path RunCommand rm -rf $temp_resource_zip RunCommand rm -rf "$thin_resource" RunCommand rm -rf "$flutter_framewok_path/icudtl.dat" else if [ -f ${thin_resource_zip} ];then RunCommand rm -rf $thin_resource_zip fi if [ -f ${thin_uuid_txt} ];then RunCommand rm -rf $thin_uuid_txt fi fi fi } |
编译之后产物被压缩成 flutter_resource.zip,同时为了标识产物的唯一性,将可执行文件的 uuid 作为唯一标识,每次下载完成之后需要先对比 uuid 是否一致。若不一致则更新产物。
第二部分:上传产物平台或内置压缩
到这一步我们准备了两种方案:
内置压缩方案:
也就是将数据段和资源包统一压缩内置在 App.framework 内,应用安装启动后自动解压放在指定位置。
动态下发方案:
对于其他小体量 App,可以采取远程下发的方案,也就是将 flutter_resource.zip 和 uuid_app.txt 上传到 s3 平台(资源服务器),同时在阿波罗平台(配置平台)增加新版本配置。应用启动后下载的方案。
方案对比:
两种方案对比之下,动态下发的瘦身效果最好,但成功率没有内置压缩高,内置压缩方案由于只增加了一个解压环节,因此成功率较高。不同的 APP 可以根据自己的需求采用不同的方案。
第三部分:产物管理
若使用远端下载方案,App 启动会首先拉取远端产物,并将版本信息生成缓存,校验 md5 通过后即可加载,当发现有新版本产物则拉取新版本产物并替换。至于内置压缩方案,则根据 App.framework 的 UUID 来判断是否是正确的产物。
内置压缩方案成功率达到了 99.99%,极小部分失败原因在于内存空间不足。
对于远程下发方案,App 启动后下载相关资源并解压,成功率会受到网络因素影响,增加了重试逻辑之后成功率如下:
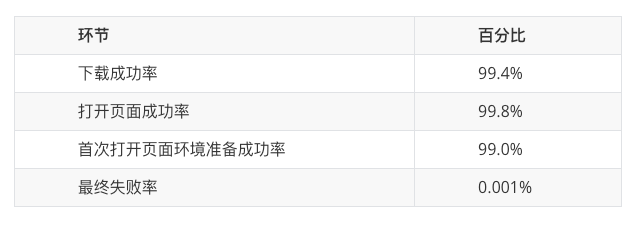
尽管下载成功率达到了 99.4%但对于 C 端这种大体量的 app 来说,仍然会影响大量的用户,因此在 C 端使用的是成功率更高的内置压缩方案。
收益
通过动态下发这种方式,虽然可以显著的减小 Flutter 包体积,但是也会带来其他问题,比如由于网络原因导致产物下载失败。因此我们提供了更加安全可靠的方式,将这些文件压缩然后内置在 app 包内。
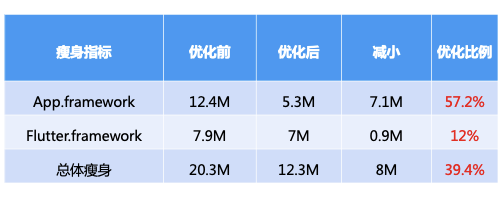
动态下发方案:
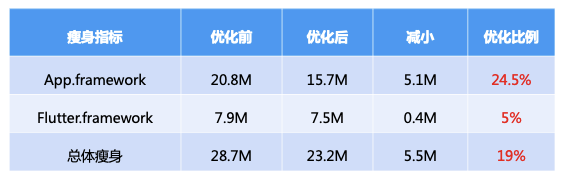
压缩内置方案:
优势:
1.通用的解决方案,任何接入 Flutter 的 APP 都可以用
2.只需集成一次,无需定时优化
3.随着 Flutter 业务的增多,瘦身效果也会更明显
劣势:
剥离出的产物需要通过网络下发,下载成功率取决于网络状况、内存空间等等因素制约。所以后续规划中,会结合 Flutter2web 来缓解由于下载失败,导致 Flutter 页面无法打开的情况。
符号化剥离及混淆:
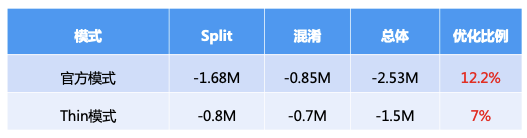
注:Thin 模式就是数据段及资源动态下发或内置压缩的模式
总体瘦身:
经过上述方案的优化,Flutter 侧瘦身总大小达到了 7M 左右。
而经过各个业务方共同的努力,贝壳找房 app 包大小终于达标。以当时的 V2.47 版本为例:
“iPhone6-iPhoneX 系列”机型安装大小 149.2-149.8M,下载大小 110.5M
“iPhone11-12”机型安装大小 139.4M,下载大小仅 53M
Flutter engine 的改造源码目前已经开源,如果想尝试贝壳方案的同学可以按照开源文档接入。
开源地址:GitHub - LianjiaTech/flutter_beike_engine
后续规划
基于以上的优势劣势,贝壳致力于更加高标准的目标, 那么有没有其他办法在不影响成功率的情况下最大程度的增加瘦身比例呢?答案是有的,那就是结合 Flutter for web 来做兜底方案。具体方案如下:
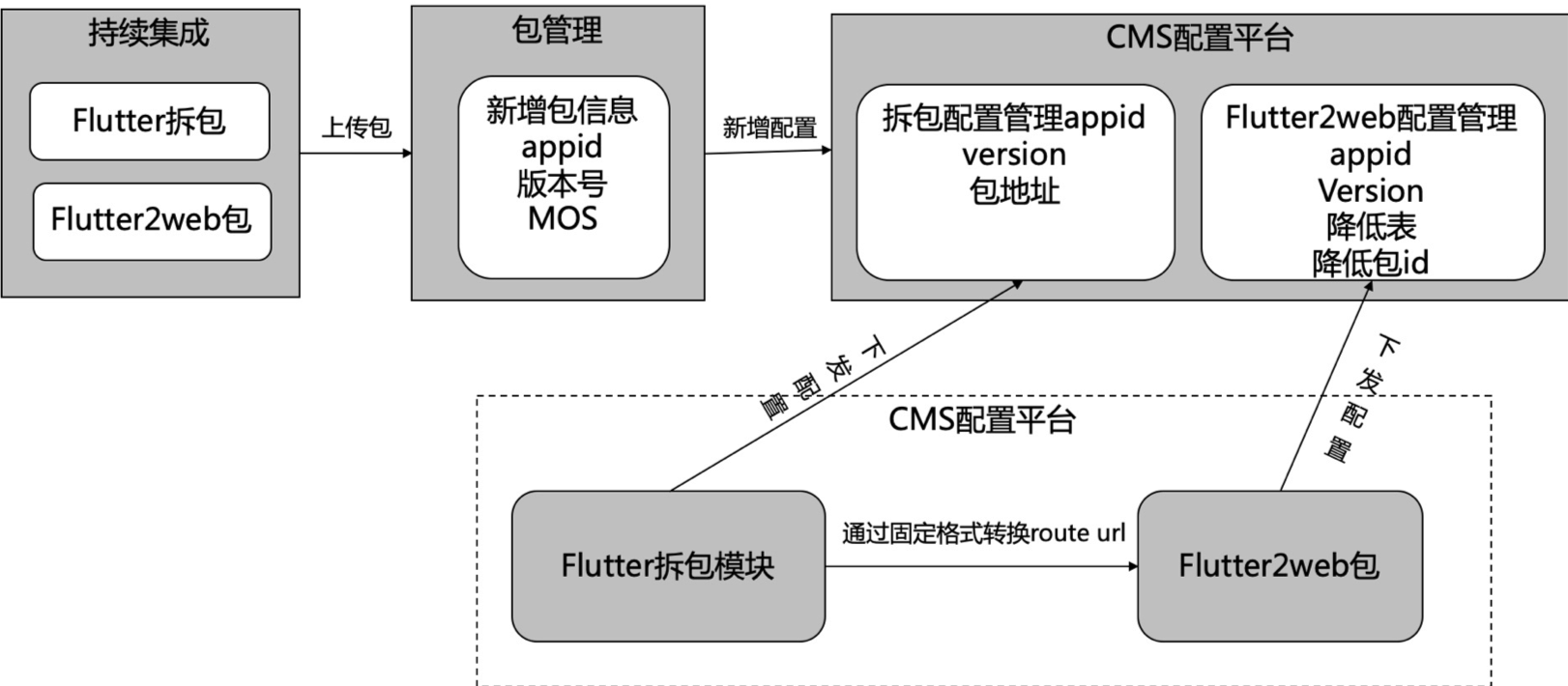
我们知道,Flutter 在三端一体化做了大量的工作,Flutter 页面可以很好的被转换为 web 页面,我们可以借助这个特性,在编译发版包的时候,同时将 Flutter 工程编译为 Web 产物并部署在远端,当 App 启动后 Flutter 产物由于种种原因最终都无法下载成功的时候,自动打开对应的 web 页面。
关于 Fluttter for web 容灾降级更详细内容可参考:
https://mp.weixin.qq.com/s/zIeU0z-4P5Pd9THVybnDFQ
参考链接