在 Flutter 里 TextField 是一个比较复杂的控件,而在整个 TextField 里嵌套了许多不同实现的控件,它们组成了我们常用的输入框效果,如下图所示是关于 TextField 的主要构成部分,也是本篇主要讲解的内容。
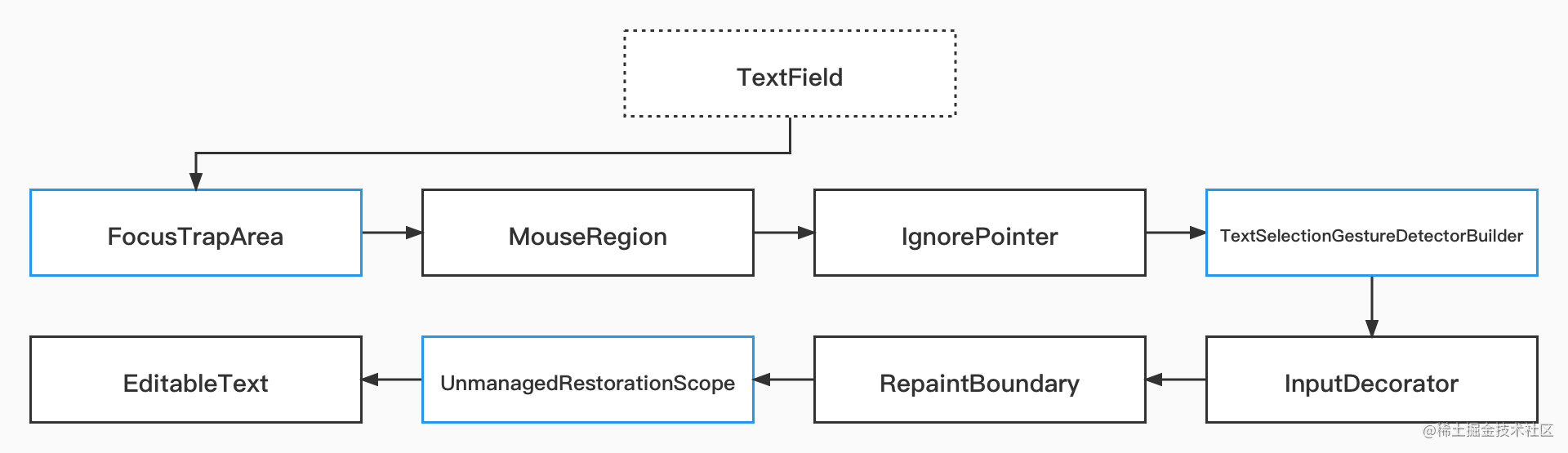
在 Flutter 里 TextField 是一个比较复杂的控件,而在整个 TextField 里嵌套了许多不同实现的控件,它们组成了我们常用的输入框效果,如下图所示是关于 TextField 的主要构成部分,也是本篇主要讲解的内容。
在 Android Studio Electric Eel | 2022.1.1 Patch 2 中构建项目的时候,出现了
|
1 |
removeContentEntry: removed content entry url 'file://*****' still exists after removing |
这样的报错。
经过多次尝试,发现直接删除 .idea目录是有效的。
关于该问题详细的讨论可以参考 https://stackoverflow.com/questions/66214555/gradle-sync-failed-removecontententry-removed-content-entry-url-still-ex
解决idea下removeContentEntry: removed content entry url ‘file://*****‘ still exists after removing的问题
以前在 Windows系统上的 Android Studio 上编辑 gradle.properties 的时候增加了不少的中文注释,现在升级到 Android Studio Electric Eel | 2022.1.1 Patch 2 结果发现中文都变成乱码了。
原因是升级到 Android Studio Electric Eel | 2022.1.1 Patch 2 之后,Windows系统上 gradle.properties 的默认编码格式被设置成了 ISO-8859-1 ,导致文件显示乱码。
现在调整回 UTF-8 格式即可解决问题。如下图:
继续阅读解决Android Studio Electric Eel | 2022.1.1 Patch 2系统下gradle.properties中文注释乱码
构建时间太长会拖慢您的开发过程。本页将介绍一些有助于解决构建速度瓶颈的技巧。
提高应用构建速度的一般过程如下:
开发应用时,您应尽可能将其部署到搭载 Android 7.0(API 级别 24)或更高版本的设备中。较新版本的 Android 平台有更出色的机制来向您的应用推送更新,例如 Android 运行时 (ART) 以及对多个 DEX 文件的原生支持。
注意:您完成首次干净构建后,可能会注意到后续构建(干净和增量)的执行速度明显加快了(即使您没有使用本页面介绍的任何优化措施)。这是因为 Gradle 守护程序有一个性能提升“预热”期,类似于其他 JVM 进程。
按照下面的提示操作,以提高 Android Studio 项目的构建速度。
几乎每次更新时,Android 工具都会获得构建方面的优化和新功能,本页介绍的一些提示假设您使用的是最新版本。为了充分利用最新的优化措施,请确保以下工具始终是最新版本:
避免编译和打包不测试的资源(例如,其他语言本地化和屏幕密度资源)。您可以仅为“dev”变种的版本指定一个语言资源和屏幕密度,如下面的示例中所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
android { ... productFlavors { dev { ... // The following configuration limits the "dev" flavor to using // English stringresources and xxhdpi screen-density resources. resourceConfigurations "en", "xxhdpi" } ... } } |
在 Android 中,所有插件都位于 google() 和 mavenCentral() 代码库中。不过,build 可能需要使用 gradlePluginPortal() 服务解析的第三方插件。
Gradle 会按照声明的顺序搜索代码库,因此,如果先列出的代码库包含大多数插件,build 性能就会得到提升。因此,您可以尝试将 gradlePluginPortal() 条目放置在 settings.gradle 文件的代码库中最靠后的位置。在大多数情况下,这样可以最大限度地减少冗余插件搜索次数,并提高构建速度。
如需详细了解 Gradle 如何导航多个代码库,请参阅 Gradle 文档中的声明多个代码库。
始终为会进入调试 build 类型的清单文件或资源文件的属性使用静态值。
您每次想运行更改时,都需要完整的应用 build 才能使用动态版本代码、版本名称、资源或可更改清单文件的任何其他构建逻辑,即使实际更改可能仅需要 1 次热交换也是如此。如果您的 build 配置需要此类动态属性,请将这些属性隔离到您的发布 build 变体中,并使相应值对您的调试 build 保持静态,如下例所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
... // Use a filter to apply onVariants() to a subset of the variants. onVariants(selector().withBuildType("release")) { variant -> // Because an app module can have multiple outputs when using multi-APK, versionCode // is only available on the variant output. // Gather the output when we are in single mode and there is no multi-APK. val mainOutput = variant.outputs.single { it.outputType == OutputType.SINGLE } // Create the version code generating task. val versionCodeTask = project.tasks.register("computeVersionCodeFor${variant.name}", VersionCodeTask::class.java) { it.outputFile.set(project.layout.buildDirectory.file("versionCode${variant.name}.txt")) } // Wire the version code from the task output. // map will create a lazy Provider that: // 1. Runs just before the consumer(s), ensuring that the producer (VersionCodeTask) has run // and therefore the file is created. // 2. Contains task dependency information so that the consumer(s) run after the producer. mainOutput.versionCode.set(versionCodeTask.flatMap { it.outputFile.map { it.asFile.readText().toInt() } }) } ... abstract class VersionCodeTask : DefaultTask() { @get:OutputFile abstract val outputFile: RegularFileProperty @TaskAction fun action() { outputFile.get().asFile.writeText("1.1.1") } } |
如需了解如何在项目中设置动态版本代码,请参阅 GitHub 上的 setVersionsFromTask 配方。
在 build.gradle 文件中声明依赖项时,请避免使用动态版本号(以加号结尾的版本号,例如 'com.android.tools.build:gradle:2.+')。使用动态版本号可能会导致意外的版本更新和难以解析版本差异,并会因 Gradle 检查有无更新而减慢构建速度。 请改用静态版本号。
在应用中查找可以转换成 Android 库模块的代码。以这种方式将您的代码模块化,可以让构建系统仅编译您修改的模块,并缓存输出以用于未来的构建。此外,这种方式也会让并行项目执行更有效(当您启用该优化时)。
创建构建性能剖析报告后,如果性能剖析报告显示相当长的一部分构建时间用在了“配置项目”阶段,请检查 build.gradle 脚本并查找您可以添加到自定义 Gradle 任务中的代码。将某些构建逻辑移到任务中后,您可以确保它仅在需要时运行,可以缓存结果以用于后续构建,并且该构建逻辑将可以并行运行(如果您已启用并行项目执行)。如需详细了解自定义构建逻辑的任务,请参阅官方 Gradle 文档。
提示:如果您的构建包含大量自定义任务,您可能需要通过创建自定义任务类来整理 build.gradle 文件。将您的类添加到 project-root/buildSrc/src/main/groovy/ 目录中;Gradle 会自动将这些类添加到项目中所有 build.gradle 文件的类路径中。
WebP 是一种既可以提供有损压缩(像 JPEG 一样)也可以提供透明度(像 PNG 一样)的图片文件格式,不过与 JPEG 或 PNG 相比,WebP 格式可以提供更好的压缩。
减小图片文件大小可以加快构建速度(无需在构建时进行压缩),尤其是当应用使用大量图片资源时。不过,在解压缩 WebP 图片时,您可能会注意到设备的 CPU 使用率有小幅上升。通过使用 Android Studio,您可以轻松地将图片转换为 WebP 格式。
即使您不将 PNG 图片转换为 WebP 格式,仍然可以在每次构建应用时停用自动图片压缩,以加快构建速度。
如果您使用的是 Android Gradle 插件 3.0.0 或更高版本,则系统会在默认情况下针对“调试”编译类型停用 PNG 处理。如需针对其他 build 类型停用此优化,请将以下代码添加到 build.gradle 文件中:
|
1 2 3 4 5 6 7 8 |
android { buildTypes { release { // Disables PNG crunching for the "release" build type. crunchPngs false } } } |
由于 build 类型或产品变种不定义此属性,因此在构建应用的发布版本时,您需要手动将此属性设置为 true。
通过配置 Gradle 所用的最佳 JVM 垃圾回收器,可以提升构建性能。虽然 JDK 8 默认配置为使用并行垃圾回收器,JDK 9 及更高版本已配置为使用 G1 垃圾回收器。
为提高构建性能,我们建议您使用并行垃圾回收器测试 Gradle 构建。在 gradle.properties 中设置以下内容:
|
1 |
org.gradle.jvmargs=-XX:+UseParallelGC |
如果此字段中已设置了其他选项,请添加一个新选项:
|
1 |
org.gradle.jvmargs=-Xmx1536m -XX:+UseParallelGC |
如需衡量采用不同配置时的构建速度,请参阅对构建进行性能剖析。
如果您发现构建速度较慢(尤其是在 Build Analyzer 结果中发现构建时间超时 15% 的情况),则应增加 Java 虚拟化机器 (JVM) 堆大小。 在 gradle.properties 文件中,将限制设置为 4 GB、6 GB 或 8 GB,如以下示例所示:
|
1 |
org.gradle.jvmargs=-Xmx6g |
然后测试构建速度是否有提升。确定最佳堆大小最简单的方法是增加限额,然后测试是否有足够的构建速度提升效果。
如果您还使用 JVM 并行垃圾回收器,则整行命令应如下所示:
|
1 |
org.gradle.jvmargs=-Xmx6g -XX:+HeapDumpOnOutOfMemoryError -Dfile.encoding=UTF-8 -XX:+UseParallelGC -XX:MaxMetaspaceSize=1g |
您可以通过开启 HeapDumpOnOutOfMemoryError 标记分析 JVM 内存错误。这样,JVM 会在内存耗尽时生成堆转储。
使用非传递 R 类可为具有多个模块的应用构建更快的 build。这样做有助于确保每个模块的 R 类仅包含对其自身资源的引用,而不会从其依赖项中提取引用,从而帮助防止资源重复。这样可以获得更快的 build,以及避免编译的相应优势。这是 Android Gradle 插件 8.0.0 及更高版本中的默认行为。
从 Android Studio Bumblebee 开始,新项目的非传递 R 类默认处于开启状态。 对于使用早期版本的 Android Studio 创建的项目,请依次前往 Refactor > Migrate to Non-transitive R Classes,将项目更新为使用非传递 R 类。
如需详细了解应用资源和 R 类,请参阅应用资源概览。
您可在应用和测试中使用非常量 R 类字段,以提高 Java 编译的增量并允许进行更精准的资源缩减。 对库而言,R 类字段始终不是常量,因为在为依赖于相应库的应用或测试打包 APK 时,资源会进行编号。 这是 Android Gradle 插件 8.0.0 及更高版本中的默认行为。
由于大多数项目都直接使用 AndroidX 库,因此您可以移除 Jetifier 标志,以便获得更好的构建性能。如需移除 Jetifier 标志,请在 gradle.properties 文件中设置 android.enableJetifier=false。
Build Analyzer 可以执行一项检查,确认是否可以安全移除该标记,使您的项目能够具有更好的构建性能,并不再使用未加维护的 Android 支持库。如需详细了解 Build Analyzer,请参阅排查构建性能问题。
配置缓存是一项实验性功能,可让 Gradle 记录有关构建任务图的信息,并在后续 build 中重复使用该任务图,而不必再次重新配置整个 build。
如需启用配置缓存,请按以下步骤操作:
使用 Build Analyzer 检查项目是否与配置缓存兼容。Build Analyzer 会运行一系列测试 build,以确定是否可以为项目启用该功能。请参阅问题 13490,查看受支持的插件列表。
将以下代码添加到 gradle.properties 文件:
|
1 2 3 4 |
org.gradle.unsafe.configuration-cache=true # Use this flag carefully, in case some of the plugins are not fully compatible. org.gradle.unsafe.configuration-cache-problems=warn |
启用配置缓存后,当您首次运行项目时,build 输出应该会显示 Calculating task graph as no configuration cache is available for tasks。 在后续运行期间,构建输出应该会显示 Reusing configuration cache。
如需详细了解配置缓存,请参阅配置缓存深度解析这篇博文和有关配置缓存的 Gradle 文档。
首先 串口 的流控大家应该都有所了解,通常是硬件 CTS/RTS 或软件 XON/XOFF 这两种流控方式,然而因为 RS485 是总线形式,所以传统的方法都不再适用。
有人会觉得奇怪,貌似从来没有考虑过 RS485 流控的问题,没错,传统 RS485 都是一收一发,用不着考虑流控,然而这种一收一发的效率比较低,譬如在 IoT 火热的今天,如果用 RS485 来传输网络数据,那么传统的做法就很低效了。
然后,针对数据完整性确保的问题,很多同行都没有留意到一个细节问题,他们通常判断是否收到回复 OK 的数据包,如果没收到数据包就超时重发一次。 这种做法大多情况都没有问题,但是某些场景,譬如发送一个命令让滑轨左移 10mm, 滑轨成功接收命令并返回 OK, 然而主机因为干扰等各种问题没有收到滑轨的回复,那么重发命令就会导致滑轨错误左移 20mm. 当然你可以说目前用到的设备都是绝对位置控制,不会有影响,但万一哪天新做一个设备,到那时再改协议,难道就不考虑兼容自己以往的产品了吗?
当然还是有很多朋友有注意到这个问题,本文使用的解决方法原理上跟这些朋友也是相同的。
我接下来提出的方案最大的亮点是共用同一套机制,同时解决了流控、数据完整性确保、大数据分包等功能,而且比较高效和简单。
同样,最底层的协议我们依然使用 CDBUS, 因为它比较简单,又支持硬件增强(可以主动避让冲突,实现多主机、对等通讯、主动上报数据等功能),能最大程度体现出本文方法的性能优势。
你可能没有听过 CDBUS 这个名字,但你可能曾经或正在使用相似的协议,它的组成包含 3 个部分: - 3 个字节的头:「源地址,目标地址,用户数据长度」 - 0~255 字节的用户数据(因为数据长度用 1 个字节表示) - 2 个字节的 CRC 校验,涵盖整个数据包,校验算法同 ModBus.
数据包与数据包之间要有一定的空闲时间,来隔开不同的数据包,详细请参见 CDBUS 的协议定义: https://github.com/dukelec/cdbus_ip
譬如地址 0x00 为主机,0x01 为 1 号从机,那么主机发送两个字节数据 0x10 0x11 给 1 号从机的完整数据为:
|
1 |
[00 01 02 10 11 49 f0] |
然后 1 号从机回覆单个 0x10 给主机:
|
1 |
[01 00 01 10 04 b8] |
然而 CDBUS 只是最底层的协议,接下来我们要定义上述用户数据的格式,最简单常用的方式就是首字节为命令号,然后后面跟可选命令参数; 回覆数据第一个字节通常为状态,然后是返回的数据。
这种方式完善之后也有一个名字,叫 CDNET, 它的定义在:https://github.com/dukelec/cdnet
(本文的内容这个连接都有包含,但本文会更加通俗的讲解一下关键细节。)
CDNET 协议有 3 个级别,由首字节的高两位决定:
|
1 2 3 4 |
Bit7 Bit6 描述 0 x Level 0: 上述最简单的形式 1 0 Level 1: 支持跨网、组播、流控等高阶功能 1 1 Level 2: 裸数据模式,支持大数据拆包,譬如传输 IPv4/v6 数据包 |
实际使用根据情况自由选择某一个或某几个来用就好。
Level 0 格式
请求
首字节:
|
1 2 3 4 |
位 描述 [7] 等于 0: Level 0 [6] 等于 0: 请求 [5:0] dst_port, 范围 0~63 |
CDNET 的端口号可以看做类似电脑的 UDP 端口,也可以看做是一个命令号。
第二字节及其后:命令参数
回复
首字节:
|
1 2 3 4 5 |
位 描述 [7] 等于 0: Level 0 [6] 等于 1: 回复 [5] 1: [4:0] 存放用户数据;0: 不使用 [4:0] 不使用或用户数据,数据必须 ≤ 31 |
例如: 回复 [0x40, 0x0c] 和回复 [0x6c] 是相同的意思。
|
1 2 3 4 |
0x40: 'b0100_0000 0x0c: 'b0000_1100 ---- 0x6c: 'b0110_1100 |
首字节的用户数据(如果有)、第二个字节及其后:回复的状态 和/或 数据。
Level 1 格式
首字节:
|
1 2 3 4 5 6 7 |
位 描述 [7] 等于 1 [6] 等于 0 [5] MULTI_NET (跨网) [4] MULTICAST (组播) [3] SEQUENCE (序列号) [2:0] PORT_SIZE (端口大小设置) |
MULTI_NET & MULTICAST
|
1 2 3 4 5 |
MULTI_NET MULTICAST 描述 0 0 Local net: 本地网络,不追加数据 0 1 Local net multicast: 追加 2 字节 [multicast-id] 组播号 1 0 Cross net: 追加 4 字节: [src_net, src_mac, dst_net, dst_mac] 1 1 Cross net multicast: 追加 4 字节: [src_net, src_mac, multicast-id] |
这个与本文主题无关,就不展开了。
SEQUENCE
0: 无序列号;
1: 追加 1 字节序列号 SEQ_NUM, 这个是重点,稍后会主要说明。
PORT_SIZE:
|
1 2 3 4 5 6 7 8 9 |
Bit2 Bit1 Bit0 SRC_PORT DST_PORT 0 0 0 Default port 1 byte 0 0 1 Default port 2 bytes 0 1 0 1 byte Default port 0 1 1 2 bytes Default port 1 0 0 1 byte 1 byte 1 0 1 1 byte 2 bytes 1 1 0 2 bytes 1 byte 1 1 1 2 bytes 2 bytes |
注: - 默认端口通常定为 0xcdcd, 所以不用额外追加字节. - 追加的字节按顺序,先是 src_port 再是 dst_port.
Level 2 格式
首字节:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
位 描述 [7] 等于 1 [6] 等于 1 [5:4] FRAGMENT(大数据分包) [3] SEQUENCE(序列号) [2:0] User-defined flag FRAGMENT: Bit5 Bit4 DST_PORT 0 0 Not fragment 0 1 First fragment 1 0 More fragment 1 1 Last fragment |
注: - 使用分包功能的时候必须同时选择使用 SEQUENCE. - 开始分包的时候 SEQ_NUM 不需要归零.
一般情况下,要求不高,使用最简单的 Level 0 格式就好了,如果命令比较多,那么就可以用 Level 1 格式,用不到的功能不用理会即可。
Level 1 没有大数据分包功能,因为通常 MCU 也用不到那么大的数据包,即使是烧录代码这种要传大数据的功能,也是可以在命令内部定义地址和数据长度的,譬如我的 STM32 总线代码升级的命令定义:
|
1 2 3 4 |
// flash memory manipulation, port 11: // erase: 0xff, addr_32, len_32 | return [] on success // read: 0x00, addr_32, len_8 | return [data] // write: 0x01, addr_32 + [data] | return [] on success |
而 Level 2 譬如可以用来传 IPv4/v6 数据包,那么就不得不加入拆包的功能了。因为 Level 1 和 Level 2 的序列号部分是一样的,所以接下来就混在一起讲了。
CDBUS 协议将前 0~9 保留专用,10 及其后的用户可以随便用,保留的部分目前也就用了 4 个,而且也不是强制的,用户愿意实现就实现,不用或者自己想怎么用就怎么用也没问题。 上篇文章说了端口或命令 0x01 是用来查询设备信息的,命令 0x03 是用来设置地址的,还详细说了如何使用这两个端口来实现地址自动分配,剩下两个端口其中 0x02 是用来设置波特率的, 对于本文最关键的端口 0x00 是用于流控、完整性确保、大数据拆包的了,其定义如下:
Port 0
配合 Level 1 和 2 头中的 SEQUENCE 字段使用。
命令启用 SEQUENCE 后追加的对应字节 SEQ_NUM[6:0] 的低 7 位会每次自动加 1.
而 SEQ_NUM 的第 7 位用来指示接收方是否要报告状态。
Port 0 本身的命令不可以启用 SEQUENCE.
Port 0 命令定义:
|
1 2 3 4 5 6 7 8 9 10 11 |
主动读目标的 SEQ_NUM: Write [] Return: [SEQ_NUM] (如果没有记录 bit 7 置 1) 主动设置目标的 SEQ_NUM: Write [0x00, SEQ_NUM] Return: [] 目标回复 SEQ_NUM: Write [SEQ_NUM] Return: None |
实际示例:
(-> 和 <- 是端口层的数据流, >> 和 << 是 CDNET 数据包层面的数据流,不含最低层的 CDBUS 的部分)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
设备 A 设备 B 描述 [0x00, 0x00] -> Port0 首次通讯设置对方的 SEQ_NUM Default port <- [] 设置成功返回 [0x88, 0x00, ...] >> 开始发送数据 [0x88, 0x01, ...] >> [0x88, 0x82, ...] >> 这次的数据标注了需要回复 SEQ_NUM @2 [0x88, 0x03, ...] >> [0x88, 0x04, ...] >> Port0 <- [0x03] 回复 SEQ_NUM @2 (每成功接收一个包计数加 1, 回复当前计数 0x03) [0x88, 0x85, ...] >> 标注了需要回复 SEQ_NUM @5 Port0 <- [0x06] 回复 SEQ_NUM @5 |
效率提升的重点就在这里,我们可以自行选择多久回复一次,而不是每次都要回复状态,如果最后一次数据包没有标注需要回复,那么会引发超时,然后主动读一次目标的 SEQ_NUM 以做同步。 之所以引发超时,是因为所有发出的数据包都不能立刻释放,要等确认对方收到才会释放,以防需要出错重传。 因为有 SEQ_NUM 号,所以即使同一个命令重复发送,对方也会只执行一次。
流控的功能也包含在内,譬如发送方时刻只允许最多 6 个数据包没有释放,那么等收到回复,释放掉 3 个,再发送 3 个数据包,这样可以最大化的利用总线带宽。 而且万一有多方发送数据至同一个节点,发送方也可以因频繁超时,来动态降低最大允许 pending 的数据包数量。
再来说大包拆分,也是很简单,拆分包有 3 个标记,分别是起始、继续、结束,譬如一个大包拆开了 4 个小包,且如果当前 SEQ_NUM 为 23,那么这四个小包的 SEQ_NUM 和标记对应关系就是:
|
1 2 3 4 |
23: 拆分启始标志 24: 继续 25: 继续 26: 结束 |
这样接收方也就很容易的把四个小包还原成原始的大包,万一出问题,也只是重新传输错掉或丢掉的包(及其后的包)。
为了简便,对于 CDNET 协议,并不是丢一个包就只重传一个包,其后传的包也需要重传,因为接收方只是简单判断序号,不对便拒绝接收,这么做是为了保持简单,毕竟错包、丢包的概率很低。
最后,想说的是,这篇文章的内容都是经过实践检验的,我有用来传输摄像头视频,DEMO 可以在这篇介绍文章中看到:https://github.com/dukelec/cdbus_doc/blob/master/intro_zh.md
协议的实现部分代码也是开源的,就是上面的 CDNET 连接,另外有一些使用 CDNET 的示例代码,譬如这个 STM32F103 的步进电机控制器:https://github.com/dukelec/stepper_motor_controller
当然,这些代码、库我也会进一步优化改善。
由IEEE制定的新型单对以太网(SPE)或10BASE-T1L物理层标准,为传输设备运行状况信息实施状态监测(CbM)应用提供了新的连接解决方案。SPE提供共享电源和高带宽数据架构,可通过低成本双线电缆在超过1000米的距离实现10 Mbps数据和电源的共享。
ADI公司设计了业界首款10BASE-T1L MAC-PHY(ADIN1110),这是一款集成MAC的单对以太网收发器。ADIN1110使用简单的SPI总线与嵌入式微控制器通信,从而可降低传感器的功耗并减少固件开发时间。
在本文中,您将了解如何设计一款体型小巧但功能强大的传感器,如图1所示。本文将介绍:
● 如何设计小型共享数据和电源通信接口
● 如何为传感器设计超低噪声电源
● 微控制器和软件架构选择
● 选择合适的MEMS振动传感器
● 集成数字硬件设计和机械外壳
● 电脑上的数据采集UI示例