![]() 重要事项
重要事项
-
设备通过无线路由器连接到互联网时,如果将其连接到处于直接连接模式的打印机,设备和无线路由器之间的现有连接将被禁用。 在这种情况下,根据设备的不同,设备连接可能会自动切换至移动数据连接。 当使用移动数据连接连接到互联网时,根据合同,可能会产生费用。
(出现在一个新窗口中)
-
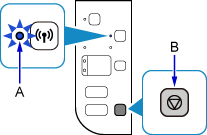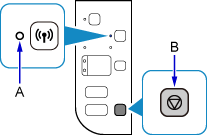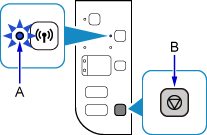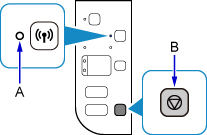
如果打印机上的Wi-Fi指示灯(A)闪烁,按停止按钮(B)。
-
按住打印机上的Wi-Fi按钮(C)直至电源指示灯(D)闪烁。
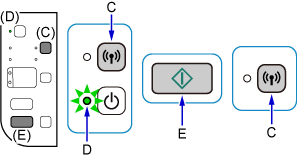
-
按彩色按钮(E),然后按Wi-Fi按钮(C)。
-
确保Wi-Fi指示灯快速闪烁且电源指示灯亮起。

-
请返回应用程序屏幕继续进行设置。
-
手机上安装 “佳能打印”软件,然后搜索经过上述操作后,新出现的Wi-Fi热点,然后根据说明操作。
- 如果配置打印机连接的路由器,启用了 “Wi-Fi多频合一”(比如:TP-Link ) 则会出现无法在 “佳能打印”软件上输入 SSID 的密码的情况。这种情况下,需要在配置的时候,暂时关闭 “Wi-Fi多频合一”。在配置完成后,可以打开 “Wi-Fi多频合一” 。
