物理模拟能够让应用富有真实感和更好的交互性。例如,你可能会为一个 widget 添加动画,让它看起来就像安着弹簧,或是在随重力下落。
这个指南演示了如何将 widget 从拖动的点移回到中心,并使用弹簧模拟效果。
这个演示将进行下面几步:
- 创建一个动画控制器
- 使用手势移动 widget
- 对 widget 进行动画
- 计算速度以模拟弹跳运动
物理模拟能够让应用富有真实感和更好的交互性。例如,你可能会为一个 widget 添加动画,让它看起来就像安着弹簧,或是在随重力下落。
这个指南演示了如何将 widget 从拖动的点移回到中心,并使用弹簧模拟效果。
这个演示将进行下面几步:
- 创建一个动画控制器
- 使用手势移动 widget
- 对 widget 进行动画
- 计算速度以模拟弹跳运动
设置小球坐标变量 : 其中 currentX 是距离左侧边界的距离 , currentY 是距离右侧边界的距离 ;
|
1 2 3 4 |
/// 当前小球的 x 坐标 double currentX = 0; /// 当前小球的 y 坐标 double currentY = 0; |
小球的位置 : 小球是在 Stack 帧布局中的 Positioned 组件 , 其 left 和 top 字段值设置其坐标 , 分别对应 currentX 和 currentY 值 ;
|
1 2 3 4 5 6 |
// 小球 Positioned( /// 当前位置 left: currentX, top: currentY, ) |
监听事件 : 监听 GestureDetector 组件的 onPanUpdate 事件 , 其回调方法是 void Function(DragUpdateDetails details) 类型的 方法 , 可以从 DragUpdateDetails 类型参数中获取当前 x , y 的移动距离 , 该距离需要与之前的距离累加 , 才能得到准确的坐标值 ;
在回调方法中调用 setState 方法 , 修改成员变量 currentX 和 currentY , 从而修改 Positioned 组件的位置 , 以达到小球移动的目的 ;
|
1 2 3 4 5 6 7 8 9 10 11 |
/// 手势检测组件 child: GestureDetector( /// 移动操作 onPanUpdate: (e){ setState(() { // e 中只能获取到 delta 值 , 需要逐步累加 currentX += e.delta.dx; currentY += e.delta.dy; }); }, ) |
代码示例 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
// 小球 Positioned( /// 当前位置 left: currentX, top: currentY, /// 手势检测组件 child: GestureDetector( /// 移动操作 onPanUpdate: (e){ setState(() { // e 中只能获取到 delta 值 , 需要逐步累加 currentX += e.delta.dx; currentY += e.delta.dy; }); }, // 黑色小球 child: Container( width: 40, height: 40, decoration: BoxDecoration( color: Colors.black, borderRadius: BorderRadius.circular(20), ), ), ),), |
完整代码示例 :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 |
import 'package:flutter/foundation.dart'; import 'package:flutter/material.dart'; class GesturePage extends StatefulWidget { const GesturePage({Key? key}) : super(key: key); @override _GesturePageState createState() => _GesturePageState(); } class _GesturePageState extends State<GesturePage> { /// 当前小球的 x 坐标 double currentX = 0; /// 当前小球的 y 坐标 double currentY = 0; @override Widget build(BuildContext context) { return MaterialApp( // 设置主题 theme: ThemeData( primarySwatch: Colors.amber, ), // 设置主体组件 home: Scaffold( // 设置标题栏 appBar: AppBar( title: const Text("手势检测"), // 返回按钮设置 leading: GestureDetector( // 点击事件回调函数 onTap: () { // 退出当前界面 Navigator.pop(context); }, // 回退按钮图标 child: const Icon(Icons.arrow_back), ), ), // 水平/垂直方向平铺组件 body: FractionallySizedBox( // 水平方向平铺 widthFactor: 1, // 帧布局 child: Stack( children: <Widget>[ // 垂直方向线性布局 Column( children: <Widget>[ // 手势检测组件 GestureDetector( // 点击事件 onTap: () { if (kDebugMode) { print("双击"); } }, // 双击事件 onDoubleTap: () { if (kDebugMode) { print("双击"); } }, // 长按事件 , ()=>方法名(参数列表) 即可回调一个现有方法 onLongPress: () => _longPress(), // 点击取消 onTapCancel: () { if (kDebugMode) { print("点击取消"); } }, // 点击按下 onTapDown: (e) { if (kDebugMode) { print("点击按下"); } }, // 点击抬起 onTapUp: (e) { if (kDebugMode) { print("点击抬起"); } }, // 手势检测的作用组件 , 监听该组件上的各种手势 child: Container( // 子组件居中 alignment: Alignment.center, // 内边距 padding: const EdgeInsets.all(100), // 背景装饰 decoration: const BoxDecoration( color: Colors.green, ), child: const Text( "手势检测", style: TextStyle( fontSize: 50, color: Colors.red, ), ), ), ) ], ), // 小球 Positioned( /// 当前位置 left: currentX, top: currentY, /// 手势检测组件 child: GestureDetector( /// 移动操作 onPanUpdate: (e) { setState(() { // e 中只能获取到 delta 值 , 需要逐步累加 currentX += e.delta.dx; currentY += e.delta.dy; }); }, // 黑色小球 child: Container( width: 40, height: 40, decoration: BoxDecoration( color: Colors.black, borderRadius: BorderRadius.circular(20), ), ), ), ), ], ), ), ), ); } /// 长按事件 void _longPress() { if (kDebugMode) { print("长按"); } } } |
Windows 下检出代码的时候报错:
|
1 2 3 4 5 6 7 |
$ git clone root@10.10.10.10:/nfs/MyCloud/.Git/xxxx Cloning into 'xxxx'... Unable to negotiate with 10.10.10.10 port 22: no matching host key type found. Their offer: ssh-rsa,ssh-dss fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists. |
前提: 在排除没有配置公钥的情况下。
Git > etc > ssh 文件夹下找到 ssh_config 文件|
1 2 3 |
Host xxx.com HostkeyAlgorithms +ssh-rsa PubkeyAcceptedAlgorithms +ssh-rsa |
windows git ssh 方式提示 no matching host key type found. Their offer: ssh-rsa,ssh-dss
2021年的最后一天, Dart 官方发布了 dart 2.15 版本,该版本优化了很多内容,今天我们要重点说说 isolate 工作器。官方推文链接
在探索新变化之前,我们来回忆巩固一下 isolate 的使用。
问题:Flutter 基于单线程模式使用协程进行开发,为什么还需要 isolate ?
首先我们要明确 并行(isolate) 与并发(future)的区别。下面我们通过简单的例子来进行说明 。Demo 是一个简单的页面,中间放置一个不断转圈的 progress 和一个按键,按键用来触发耗时方法。
|
1 2 3 4 5 6 7 8 9 10 11 |
///计算偶数个数(具体的耗时操作)下面示例代码中会用到 static int calculateEvenCount(int num) { int count = 0; while (num > 0) { if (num % 2 == 0) { count++; } num--; } return count; } |
|
1 2 3 4 5 |
///按键点击事件 onPressed: () { //触发耗时操作 doMockTimeConsume(); } |
future 的方式进行封装|
1 2 3 4 5 6 7 8 9 10 11 12 |
///使用future的方式封装耗时操作 static Future<int> futureCountEven(int num) async { var result = calculateEvenCount(num); return Future.value(result); } ///耗时事件 void doMockTimeConsume() async { var result = await futureCountEven(1000000000); _count = result; setState(() {}); } |
结论:使用 future 的方式来消费耗时操作,由于仍然是单线程在进行工作,异步只是在同一个线程的并发操作,仍会阻塞UI的刷新。
isolate 创建新线程,避开主线程,不干扰UI刷新|
1 2 3 4 5 6 |
//模拟耗时操作 void doMockTimeConsume() async { var result = await isolateCountEven(1000000000); _count = result; setState(() {}); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
///使用isolate的方式封装耗时操作 static Future<dynamic> isolateCountEven(int num) async { final p = ReceivePort(); ///发送参数 await Isolate.spawn(_entryPoint, [p.sendPort, num]); return (await p.first) as int; } static void _entryPoint(SendPort port) { SendPort responsePort = args[0]; int num = args[1]; ///接收参数,进行耗时操作后返回数据 responsePort.send(calculateEvenCount(num)); } |
结论:使用 isolate 实现了多线程并行,在新线程中进行耗时操作不会干扰UI线程的刷新。
iso 有两点较为重要的局限性。
Dart 2.15 更新, 给 iso 添加了组的概念,isolate 组 工作特征可简单总结为以下两点:
仍然阻止在 isolate 间共享访问可变对象,但由于 isolate 组使用共享堆实现,这也让其拥有了更多的功能。官方推文中举了一个例子:
工作器 isolate 通过网络调用获得数据,将该数据解析为大型 JSON 对象图,然后将这个 JSON 图返回到主 isolate 中。
Dart 2.15 之前:执行该操作需要深度复制,如果复制花费的时间超过帧预算时间,就会导致界面卡顿。
使用 Dart 2.15:工作器 isolate 可以调用Isolate.exit(),将其结果作为参数传递。然后,Dart 运行时将包含结果的内存数据从工作器 isolate 传递到主 isolate 中,无需复制,且主 isolate 可以在固定时间内接收结果。
重点:提供 Isolate.exit() 方法,将包含结果的内存数据从工作器 isolate 传递到主 isolate,过程无需复制。
附注: 使用 Dart 新特性,需将 flutter sdk 升级到 2.8.0 以上 链接。
Dart 更新后,我们将数据从 工作器 isolate(子线程)回传到 主 isolate(主线程)有两种方式。
send|
1 |
responsePort.send(data); |
点击进入 send 方法查看源码注释,看到这样一句话:
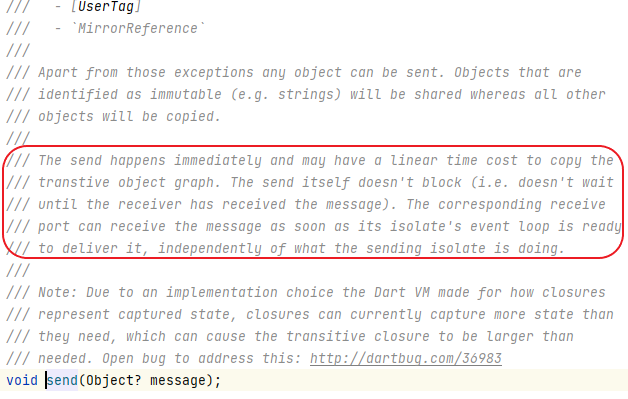
结论:send 本身不会阻塞,会立即发送,但可能需要线性时间成本用于复制数据。
exit|
1 |
Isolate.exit(responsePort, data); |
官网 给出的解释如下:

结论:隔离之间的消息传递通常涉及数据复制,因此可能会很慢,并且会随着消息大小的增加而增加。但是
exit(),则是在退出隔离中保存消息的内存,不会被复制,而是被传输到主 isolate。这种传输很快,并且在恒定的时间内完成。
我们把上面 demo 中的 _entryPoint 方法做一下优化,修改如下:
|
1 2 3 4 5 6 7 |
static void _entryPoint(SendPort port) { SendPort responsePort = args[0]; int num = args[1]; ///接收参数,进行耗时操作后返回数据 //responsePort.send(calculateEvenCount(num)); Isolate.exit(responsePort, calculateEvenCount(num)); } |
总结:使用 exit() 替代 SendPort.send,可规避数据复制,节省耗时。
如何创建一个 isolate 组?官方给出的解释如下:
When an isolate calls
Isolate.spawn(), the two isolates have the same executable code and are in the same isolate group. Isolate groups enable performance optimizations such as sharing code; a new isolate immediately runs the code owned by the isolate group. Also,Isolate.exit()works only when the isolates are in the same isolate group.
当在 isolate 中调用另一个 isolate 时,这两个 isolate 具有相同的可执行代码,并且位于同一隔离组。
PS: 小轰暂时也没有想到具体的使用场景,先暂放一边吧。
结合上面的耗时方法calculateEvenCount,isolate 处理连续数据需要结合 stream 流的设计。具体 demo 如下:
|
1 2 3 4 5 6 7 |
///测试入口 static testContinuityIso() async { final numbs = [10000, 20000, 30000, 40000]; await for (final data in _sendAndReceive(numbs)) { log(data.toString()); } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
///具体的iso实现(主线程) static Stream<Map<String, dynamic>> _sendAndReceive(List<int> numbs) async* { final p = ReceivePort(); await Isolate.spawn(_entry, p.sendPort); final events = StreamQueue<dynamic>(p); // 拿到 子isolate传递过来的 SendPort 用于发送数据 SendPort sendPort = await events.next; for (var num in numbs) { //发送一条数据,等待一条数据结果,往复循环 sendPort.send(num); Map<String, dynamic> message = await events.next; //每次的结果通过stream流外露 yield message; } //发送 null 作为结束标识符 sendPort.send(null); await events.cancel(); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
///具体的iso实现(子线程) static Future<void> _entry(SendPort p) async { final commandPort = ReceivePort(); //发送一个 sendPort 给主iso ,用于 主iso 发送参数给 子iso p.send(commandPort.sendPort); await for (final message in commandPort) { if (message is int) { final data = calculateEvenCount(message); p.send(data); } else if (message == null) { break; } } } |
系统与开发环境 Flutter (2.10.1~3.3.9)/Xcode 13.2.1(13C100)/macOS Big Sur 11.6.4/iPad Pro(Model A1673) iOS 15.3.1/iPhone SE 3 iOS 16.1.1
1. 苹果开发网站 注册或关联开发者账号,如果暂时不需要发布应用到 Mac App Store,只是在设备上调试应用,则不需要注册收费用户,只需要注册或者关联账号即可。具体可以查看官方介绍 选择会员资格 。
2. 在 iPad Pro 和 macbook Pro 登陆同一个注册的开发者的账号。
3. 通过 USB 数据线把 iPad Pro 与 macbook Pro 设备连接起来,如下图:
Flutter Engine自己不创建管理线程。Flutter Engine线程的创建和管理是由embedder负责的。Embeder指的是将引擎移植到平台的中间层代码。
Flutter Engine要求Embeder提供四个Task Runner。尽管Flutter Engine不在乎Runner具体跑在哪个线程,但是它需要线程配置在整一个生命周期里面保持稳定。也就是说一个Runner最好始终保持在同一线程运行。这四个主要的Task Runner包括:
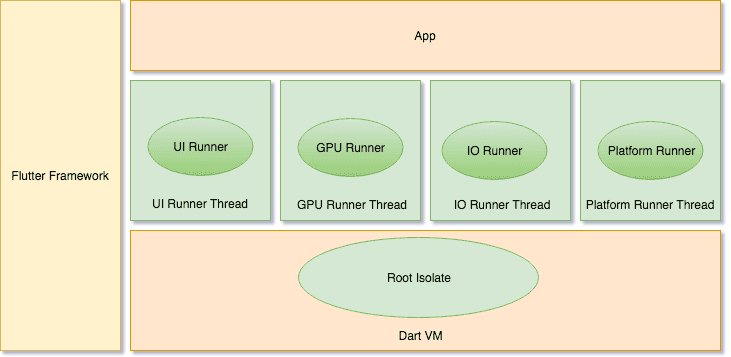
Flutter Engine的主Task Runner,运行Platform Task Runner的线程可以理解为是主线程。类似于Android Main Thread或者iOS的Main Thread。但是我们要注意Platform Task Runner和iOS之类的主线程还是有区别的。
对于Flutter Engine来说Platform Runner所在的线程跟其它线程并没有实质上的区别,只不过我们人为赋予它特定的含义便于理解区分。实际上我们可以同时启动多个Engine实例,每个Engine对应一个Platform Runner,每个Runner跑在各自的线程里。这也是Fuchsia(Google正在开发的操作系统)里Content Handler的工作原理。一般来说,一个Flutter应用启动的时候会创建一个Engine实例,Engine创建的时候会创建一个线程供Platform Runner使用。
跟Flutter Engine的所有交互(接口调用)必须发生在Platform Thread,试图在其它线程中调用Flutter Engine会导致无法预期的异常。这跟iOS UI相关的操作都必须在主线程进行相类似。需要注意的是在Flutter Engine中有很多模块都是非线程安全的。一旦引擎正常启动运行起来,所有引擎API调用都将在Platform Thread里发生。
Platform Runner所在的Thread不仅仅处理与Engine交互,它还处理来自平台的消息。这样的处理比较方便的,因为几乎所有引擎的调用都只有在Platform Thread进行才能是安全的,Native Plugins不必要做额外的线程操作就可以保证操作能够在Platform Thread进行。如果Plugin自己启动了额外的线程,那么它需要负责将返回结果派发回Platform Thread以便Dart能够安全地处理。规则很简单,对于Flutter Engine的接口调用都需保证在Platform Thread进行。
需要注意的是,阻塞Platform Thread不会直接导致Flutter应用的卡顿(跟iOS android主线程不同)。尽管如此,平台对Platform Thread还是有强制执行限制。所以建议复杂计算逻辑操作不要放在Platform Thread而是放在其它线程(不包括我们现在讨论的这个四个线程)。其他线程处理完毕后将结果转发回Platform Thread。长时间卡住Platform Thread应用有可能会被系统Watchdog强行杀死。
UI Task Runner被Flutter Engine用于执行Dart root isolate代码。Root isolate比较特殊,它绑定了不少Flutter需要的函数方法。Root isolate运行应用的main code。引擎启动的时候为其增加了必要的绑定,使其具备调度提交渲染帧的能力。对于每一帧,引擎要做的事情有:
- Root isolate通知Flutter Engine有帧需要渲染。
- Flutter Engine通知平台,需要在下一个vsync的时候得到通知。
- 平台等待下一个vsync
- 对创建的对象和Widgets进行Layout并生成一个Layer Tree,这个Tree马上被提交给Flutter Engine。当前阶段没有进行任何光栅化,这个步骤仅是生成了对需要绘制内容的描述。
- 创建或者更新Tree,这个Tree包含了用于屏幕上显示Widgets的语义信息。这个东西主要用于平台相关的辅助Accessibility元素的配置和渲染。
除了渲染相关逻辑之外Root Isolate还是处理来自Native Plugins的消息响应,Timers,Microtasks和异步IO。
我们看到Root Isolate负责创建管理的Layer Tree最终决定什么内容要绘制到屏幕上。因此这个线程的过载会直接导致卡顿掉帧。
如果确实有无法避免的繁重计算,建议将其放到独立的Isolate去执行,比如使用compute关键字或者放到非Root Isolate,这样可以避免应用UI卡顿。但是需要注意的是非Root Isolate缺少Flutter引擎需要的一些函数绑定,你无法在这个Isolate直接与Flutter Engine交互。所以只在需要大量计算的时候采用独立Isolate。
Raster(GPU) Task Runner被用于执行设备GPU的相关调用。UI Task Runner创建的Layer Tree信息是平台不相关,也就是说Layer Tree提供了绘制所需要的信息,具体如何实现绘制取决于具体平台和方式,可以是OpenGL,Vulkan,软件绘制或者其他Skia配置的绘图实现。GPU Task Runner中的模块负责将Layer Tree提供的信息转化为实际的GPU指令。Raster(GPU) Task Runner同时也负责配置管理每一帧绘制所需要的GPU资源,这包括平台Framebuffer的创建,Surface生命周期管理,保证Texture和Buffers在绘制的时候是可用的。
基于Layer Tree的处理时长和GPU帧显示到屏幕的耗时,Raster(GPU) Task Runner可能会延迟下一帧在UI Task Runner的调度。一般来说UI Runner和GPU Runner跑在不同的线程。存在这种可能,UI Runner在已经准备好了下一帧的情况下,Raster(GPU) Runner却还正在向GPU提交上一帧。这种延迟调度机制确保不让UI Runner分配过多的任务给GPU Runner。
前面我们提到Raster(GPU) Runner可以导致UI Runner的帧调度的延迟,Raster(GPU) Runner的过载会导致Flutter应用的卡顿。一般来说用户没有机会向Raster(GPU) Runner直接提交任务,因为平台和Dart代码都无法跑进Raster(GPU) Runner。但是Embeder还是可以向Raster(GPU) Runner提交任务的。因此建议为每一个Engine实例都新建一个专用的Raster(GPU) Runner线程。
前面讨论的几个Runner对于执行任务的类型都有比较强的限制。Platform Runner过载可能导致系统WatchDog强杀,UI和GPU Runner过载则可能导致Flutter应用的卡顿。但是GPU线程有一些必要操作是比较耗时间的,比如IO,而这些操作正是IO Runner需要处理的。
IO Runner的主要功能是从图片存储(比如磁盘)中读取压缩的图片格式,将图片数据进行处理为GPU Runner的渲染做好准备。在Texture的准备过程中,IO Runner首先要读取压缩的图片二进制数据(比如PNG,JPEG),将其解压转换成GPU能够处理的格式然后将数据上传到GPU。这些复杂操作如果跑在GPU线程的话会导致Flutter应用UI卡顿。但是只有GPU Runner能够访问GPU,所以IO Runner模块在引擎启动的时候配置了一个特殊的Context,这个Context跟GPU Runner使用的Context在同一个ShareGroup。事实上图片数据的读取和解压是可以放到一个线程池里面去做的,但是这个Context的访问只能在特定线程才能保证安全。这也是为什么需要有一个专门的Runner来处理IO任务的原因。获取诸如ui.Image这样的资源只有通过async call,当这个调用发生的时候Flutter Framework告诉IO Runner进行刚刚提到的那些图片异步操作。这样GPU Runner可以使用IO Runner准备好的图片数据而不用进行额外的操作。
用户操作,无论是Dart Code还是Native Plugins都是没有办法直接访问IO Runner。尽管Embeder可以将一些一般复杂任务调度到IO Runner,这不会直接导致Flutter应用卡顿,但是可能会导致图片和其它一些资源加载的延迟间接影响性能。所以建议为IO Runner创建一个专用的线程。
前面我们提到Engine Runner的线程可以按照实际情况进行配置,各个平台目前有自己的实现策略。
Mobile平台上面每一个Engine实例启动的时候会为UI,GPU,IO Runner各自创建一个新的线程。
所有Engine实例共享同一个Platform Task Runner和Platform Thread。
从 Flutter 2.10 开始,可以使用任何一个有 Task Queue 的线程作为 Platform Task Runner,默认情况下还是使用应用的主线程作为 Platform Task Runner。
Platform Task Runner为什么一定要使用平台的主线程? 因为Platform Task Runner的功能是要处理平台的消息,但是平台的API 绝大多数 都只能在主线程调用(尤其是UI相关的API以及触摸事件),所以Platform Task Runner运行所在的平台的线程必须是主线程。这也就是为什么全部实例共享同一个Platform Task Runner的根本原因。
每一个Engine实例都为UI,GPU,IO,Platform Runner创建各自新的线程。
上面的线程模型介绍是为了我们后续实现整个应用的单例对象进行知识储备。
接下来,我们需要知道我们的代码默认运行在哪个线程上面。答案就是 UI Task Runner Thread(Dart Runner),运行 Dart Main Isolate 和应用主要的 Dart 代码。
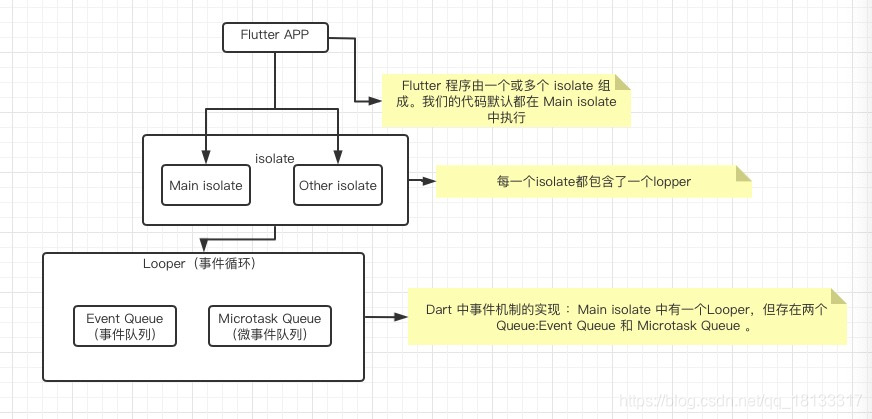
那么为什么不直接复用 Platform Task Runner 呢?其实单独出现 Platform Task Runner 更多的是一种妥协的表现,这个线程不能长时间阻塞,否则会被系统杀死。如果直接复用这个线程,而不是使用其他线程非常容易导致 Platform Task Runner 过载,导致卡顿,另外很多系统API只能通过系统的主线程调用,因此这个 Platform Task Runner 主要用于虚拟机的初始化,虚拟机与系统通信等任务。
对于原生的 Flutter 应用(完全新建的纯 Flutter 工程)来说,整个应用只有一个 Flutter Engine,那么实现全局单例对象就比较简单,只要在代码中声明单例对象,当其他的Isolate需要访问单例对象的时候,与 Dart Main Isolate 通信即可实现对单例对象的访问。
对于通过 集成到现有应用(Add-to-app) 的方式,集成到已经存在的应用的情况来说,则需要分两种情况考虑,如果使用全局共享同一个 Flutter Engine 的方式来说,与原生Flutter 应用的区别不大。
但是当使用多 Flutter Engine 的方式来说,则比较复杂。
首先我们知道在 iOS和Android 平台上,所有Engine实例共享同一个Platform Task Runner和Platform Thread。也就是说在 iOS和Android 平台上,不管初始化多少个引擎实例,都有且只有一个相同的 Platform Task Runner 。因此,原理上只要是 Platform Task Runner 线程中实现一个全局或静态对象,然后通过 Platform Task Runner 创建其他线程(isolate), 需要操作单例对象的时候,通过 Platform Task Runner ,就可以在 iOS和Android 平台上实现整个应用全局单例的效果。
但是很遗憾的是,我们没办法直接指定某段代码必须执行在 Platform Task Runner 上。因此,对于多线程安全的全局单例可以使用 平台相关代码,在平台侧实现,然后使用平台相关API进行通信的方式来实现,这样有点类似于服务器上使用 Redis 进行数据存储的逻辑。
漏洞编号: CVE-2021-4034
漏洞产品: PolKit (pkexec)
影响版本: 影响2009年 - 今的版本(当前0.105)
源码获取:
|
1 |
$ apt source policykit-1 |
或 https://launchpad.net/ubuntu/bionic/+package/policykit-1
Windows 10系统想要下载应用和游戏都需要在应用商店Microsoft Store中下载,但是很多用户反馈应用商店打不开,无法加载页面,请稍后重试的错误,下面通常还有一些代码什么的,不过参考意义不大,下面就教大家如何解决这个问题。
在利用 Photoshop 等得到的 PNG 透明图中,一般都是包含 alpha channel 的.
但是IOS图标不允许图标中包含 Alpha通道。
下面的代码实现的功能:Remove PNG Transparency
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#!/usr/bin/python3 #!--*-- coding:utf-8 --*-- def remove_transparency(img_pil, bg_colour=(255, 255, 255)): # Only process if image has transparency if img_pil.mode in ('RGBA', 'LA') or \ (img_pil.mode == 'P' and 'transparency' in img_pil.info): # Need to convert to RGBA if LA format due to a bug in PIL (http://stackoverflow.com/a/1963146) alpha = img_pil.convert('RGBA').split()[-1] # Create a new background image of our matt color. # Must be RGBA because paste requires both images have the same format # (http://stackoverflow.com/a/8720632 and http://stackoverflow.com/a/9459208) bg = Image.new("RGBA", img_pil.size, bg_colour + (255,)) bg.paste(img_pil, mask=alpha) return bg else: return img_pil |
From: Remove transparency/alpha from any image using PIL - stackoverflow
Flutter 多国语言支持,参考 Flutter 2.8.1/Android Studio Bumblebee 2021.1.1多国语支持配置和使用
系统与开发环境 macOS Big Sur 11.6.3/Android Studio Bumblebee 2021.1.1
Android下本地化应用程序名比较简单,只需要修改 AndroidManifest.xml 里的 application 标签下的 android:label 即可,如下图: