“omv-firstaid”是系统内置的修复工具,虽然修复功能有限但是向导式修复过程还是很简单,紧急情况下在终端输入“omv-firstaid”通常可以修复以下几项故障:
- IP配置重设,有时网络配置设置失误不能联机后可以用此工具修复;
- WEBGUI端口重设;
- WEBGUI管理员密码重置;
- OMV配置恢复,可以恢复最近一次配置文件备份;
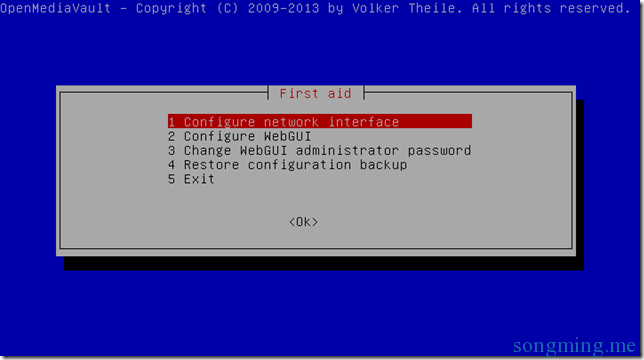
“omv-firstaid”是系统内置的修复工具,虽然修复功能有限但是向导式修复过程还是很简单,紧急情况下在终端输入“omv-firstaid”通常可以修复以下几项故障:
最近在使用VS2013进行静态库链接的时候,发现在最后链接的时候,编译器报告如下警告
|
1 2 3 4 |
4>LINK : warning C4743: “const std::system_error::`vftable'”在“aaa.cc”和“bbb.cpp”中具有不同的大小: 16 和 12 字节 4>LINK : warning C4743: “const std::_System_error::`vftable'”在“ccc.cc”和“ddd.cpp”中具有不同的大小: 16 和 12 字节 4>LINK : warning C4743: “const std::ios_base::failure::`vftable'”在“eee.cc”和“fff.cpp”中具有不同的大小: 16 和 12 字节 4>LINK : warning C4743: “const std::runtime_error::`vftable'”在“xxx.cc”和“yyy.cpp”中具有不同的大小: 16 和 12 字节 |
尽管这个是个警告,但是由于涉及到vftable 的问题,这个问题会导致对象指针之间相互赋值的时候导致内存布局混乱,非常可能导致严重的问题。因此这个警告的危险级别甚至比错误的还要严重,绝不能简单的忽略这个问题。
研究了很久,发现,在Debug版本上面是没有问题的,但是Release版本上面必然出现该问题。并且当设置VC++ 的 “工程属性->配置属性->C/C++->优化->全程序优化”为 “否”的时候,也是可以无警告链接通过的。但是却会导致我们的工程损失更多的优化,降低运行效率。
这个问题产生的原因是一个宏引起的,这个宏就是 “_HAS_EXCEPTIONS=0” 。这个宏控制了STL对于异常的处理流程,影响着typeinfo,system_error 等几个文件中对于VC 运行时库的链接选择,要么链接libcmt.lib,要么链接msvcrt.lib。比较不凑巧的是,微软在实现这两个库的时候,其中一个比另外一个多了一个虚函数。(这种情况不应该发生,但是确实发生了!)
因此,如果我们的LIB工程定义了“_HAS_EXCEPTIONS=0” ,那么所有使用我们这个LIB的项目,都要定义这个宏。
对于简单的项目,只要都定义“_HAS_EXCEPTIONS=0” 就可以解决问题。但是对于复杂的工程,尤其是依赖了大量的第三方的已经编译过的,没有源代码的LIB项目来说,只能是采用妥协的办法,所有的工程都取消这个宏的定义,使得两者的内存布局相同。毕竟,稳定性是第一需求。
最近使用 WordPress 自动升级的时候,只要更新包稍微大一点就会报告500错误。观察Apache2的日志,提示如下信息:
|
1 2 3 4 5 6 |
$tail -f /var/log/apache2/error.log ................................... [Thu Aug 06 10:51:54 2015] [warn] [client 42.120.74.98] (110)Connection timed out: mod_fcgid: ap_pass_brigade failed in handle_request_ipc function, referer: http://www.mobibrw.com/wp-admin/update-core.php?action=do-core-upgrade [Thu Aug 06 10:52:02 2015] [warn] mod_fcgid: process 11192 graceful kill fail, sending SIGKILL [Thu Aug 06 10:53:06 2015] [warn] [client 42.120.74.98] mod_fcgid: read data timeout in 40 seconds, referer: http://www.mobibrw.com/wp-admin/update-core.php?action=do-core-upgrade ................................... |
网站配置的PHP是通过FastCGI模块来加载,也就是mod_fcgid。
这个说明fcgid模块在读取数据的时候超时了。经过多次测试,证明500错误的时候会产生这条记录,看来罪魁祸首就是这个模块了。立马输入命令:
|
1 2 3 4 5 6 7 8 |
$vim /etc/apache2/mods-available/fcgid.conf <IfModule mod_fcgid.c> AddHandler fcgid-script .fcgi .php FcgidConnectTimeout 120 DefaultMaxClassProcessCount 10 MaxRequestLen 15728640 </IfModule> |
上网仔细一查,这个模块下可用的参数还真不少。 另外一个叫做“IPCCommTimeout”的参数吸引了我的注意力,这是FastCGI模块在与程序通讯的时候的超时时间。不管三七二十一,死马当活 马医,将这个参数添加后,也设置为300,这样一来文件的内容就如下了:
|
1 2 3 4 5 6 7 |
<IfModule mod_fcgid.c> AddHandler fcgid-script .fcgi .php FcgidConnectTimeout 120 DefaultMaxClassProcessCount 10 MaxRequestLen 15728640 IPCCommTimeout 300 </IfModule> |
再次重启apache,运行出错的php脚本测试,成功得到结果,没有再出现500错误,问题解决。
在Windows 中使用Git的时候,习惯使用TortoiseGit来进行Git的管理。
TortoiseGit在提交代码的时候,使用Putty来实现SSH通信,Putty的Key文件为.ppk格式的文件,现在切换到Ubuntu之后,使用SmartGit来进行管理,而SmartGit 只支持OpenSSH 格式的Key文件,因此需要把Windows下面的.ppk文件转换为OpenSSH格式的文件。
具体操作如下所示:
|
1 2 |
$sudo apt-get install putty-tools $puttygen id_dsa.ppk -O private-openssh -o id_dsa |
然后指定生成的文件为Key文件,就可以正常使用了。
注意,命令中的转换参数全部为字母“O”,不是数字零“0”,只是前面是大写字符后面是小写字符。
SmartGit/HG 是一款开放源代码的、跨平台的、支持 Git 和 Mercurial 的 SVN 图形客户端,可运行在Windows、Linux 和 MAC OS X 系统上。可用的最新版本 SmartGit/HG 6.0.0,最近已发布。
Ubuntu及衍生系统用户安装,打开终端,使用以下命令:
|
1 2 3 4 5 |
$ sudo add-apt-repository ppa:eugenesan/ppa $ sudo apt-get update $ sudo apt-get install smartgit |
Debian 用户安装命令:
|
1 2 3 4 5 |
$ sudo apt-get install gdebi $ wget https://www.syntevo.com/downloads/smartgit/smartgit-18_2_7.deb $ sudo gdebi smartgit-18_2_7.deb |
卸载命令:
|
1 |
$ sudo apt-get remove smartgit |
WordPress支持通过SFTP来更新自身的组件,但是在服务器上设置支持SFTP之后,一直更新失败,如图所示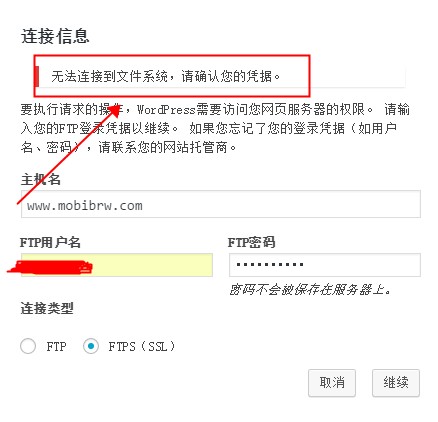
网上查询了一下,是缺少了PHP的SSH支持库导致的,解决方法如下(安装libssh2-php)
|
1 2 |
sudo apt-get install libssh2-php sudo service apache2 restart |
刷新页面后,得到的结果如下图所示,则表示已经成功。
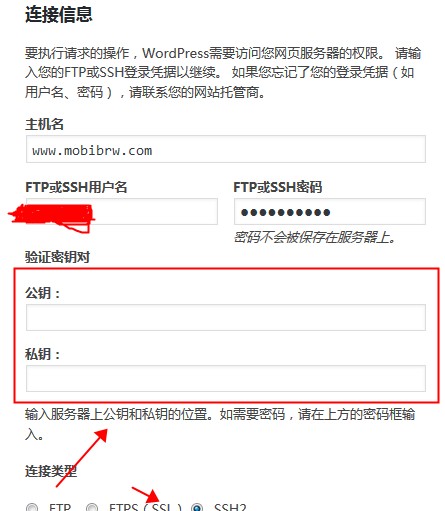
对于使用常规的,使用密码登录的情况,可以无视“验证密钥对”部分的设置即可。
硬盘是一个损耗设备,当使用一段时间后可能会出现坏道等物理故障。电脑硬盘出现坏道后,如果不及时更换或进行技术处理,坏道就会越来越多,并会造成频繁死机和数据丢失。最好的处理方式是更换磁盘,但在临时的情况下,应及时屏蔽坏道部分的扇区,不要触动它们。badblocks就是一个检查坏道位置的工具。
一、命令参数
badblocks使用格式为:
|
1 |
badblocks [ -svwnf ] [ -b block-size ] [ -c blocks_at_once ] [ -i input_file ] [ -o output_file ] [ -p num_passes ] [ -t test_pattern ] device [ last-block ] [ start-block ] |
参数含义是:
-b blocksize
指定磁盘的区块大小,单位为字节,默认值为“block 4K ”(4K/block)
-c blocksize
每个区块检查的次数,默认是16次
-f
强制在一个已经挂载的设备上执行读写或非破坏性的写测试操作
(我们建议先umount设备,然后再进行坏道检测。仅当/etc/mtab出现误报设备挂载错误的时候可以使用该选项)
-i file
跳过已经显示在file文件中的坏道,而不进行检测(可以避免重复检测)
-o file
把检测结果输出到file文件
-p number
重复搜寻设备,直到在指定通过次数内都没有找到新的坏块位置,默认次数为0
-s
在检查时显示进度
-t pattern
通过按指定的模式读写来检测区块。你可以指定一个0到ULONG_MAX-1的十进制正值,或使用random(随机)。
如果你指定多个模式,badblocks将使用第一个模式检测所有的区块,然后再使用下一个模式检测所有的区块。
Read-only方式仅接受一个模式,它不能接受random模式的。
-v
执行时显示详细的信息
-w
对每个区块都先写入,然后再从它读取信息
[device]
指定要检查的磁盘装置。
[last-block]
指定磁盘装置的区块总数。
[start-block]
指定要从哪个区块开始检查
二、示例
badblocks以4096的一个block,每一个block检查16次,将结果输出到“hda-badblocks-list”文件里
|
1 |
# badblocks -b 4096 -c 16 /dev/hda1 -o hda-badblocks-list |
"hda-badblocks-list”是个文本文件,内容如下:
引用
|
1 2 3 4 5 6 7 8 9 |
# cat hda-badblocks-list 51249 51250 51251 51253 51254 …… 61245 …… |
可以针对可疑的区块多做几次操作。下面,badblocks以4096字节为一个“block”,每一个“block”检查1次, 将结果输出到“hda-badblocks-list.1”文件中,由第51000 block开始,到63000 block结束
|
1 |
# badblocks -b 4096 -c 1 /dev/hda1 -o hda-badblocks-list.1 63000 51000 |
这次花费的时间比较短,硬盘在指定的情况下在很短的时间就产生“嘎嘎嘎嘎”的响声。由于检查条件的不同,其输出的结果也不完全是相同的。重复几次同样的操作,因条件多少都有些不同,所以结果也有所不同。进行多次操作后,直到产生最后的hda-badblock-list.final文件。
三、其他
1、fsck使用badblocks的信息
badblocks只会在日志文件中标记出坏道的信息,但若希望在检测磁盘时也能跳过这些坏块不检测,可以使用fsck的-l参数:
|
1 |
# fsck.ext3 -l /tmp/hda-badblock-list.final /dev/hda1 |
2、在创建文件系统前检测坏道
badblocks可以随e2fsck和mke2fs的-c删除一起运行(对ext3文件系统也一样),在创建文件系统前就先检测坏道信息:
|
1 |
# mkfs.ext3 -c /dev/hda1 |
代码表示使用-c在创建文件系统前检查坏道的硬盘。
这个操作已经很清楚地告知我们可以采用“mkfs.ext3 -c”选项用“read-only”方式检查硬盘。这个命令会在格式化硬盘时检查硬盘,并标出错误的硬盘“block”。用这个方法格式化硬盘,需要有相当大的耐心,因为命令运行后,会一个个用读的方式检查硬盘。
FreeNAS 9.3 通过SSH 登陆之后中文显示为问号,网上查询了一下,找到解决方法。
在~/.cshrc下面增加
|
1 2 3 |
setenv LANG zh_CN.UTF-8 setenv LC_CTYPE zh_CN.UTF-8 setenv LC_ALL zh_CN.UTF-8 |
添加完后退出当前会话,重新进入即可正确显示中文。