Android 5.0 模拟器默认在一分钟之内没有操作,就会关闭屏幕,出现黑屏的情况,如下图所示.
注意,这不是死掉了,只是休眠了而已。解除休眠的方式是按“ESC”或者“F7”按键即可。如果需要测试休眠的话,“F7”按键是个不错的选择。
Android 5.0 模拟器默认在一分钟之内没有操作,就会关闭屏幕,出现黑屏的情况,如下图所示.
注意,这不是死掉了,只是休眠了而已。解除休眠的方式是按“ESC”或者“F7”按键即可。如果需要测试休眠的话,“F7”按键是个不错的选择。
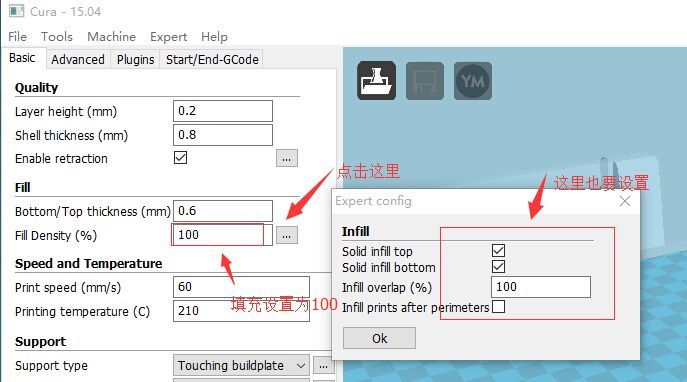
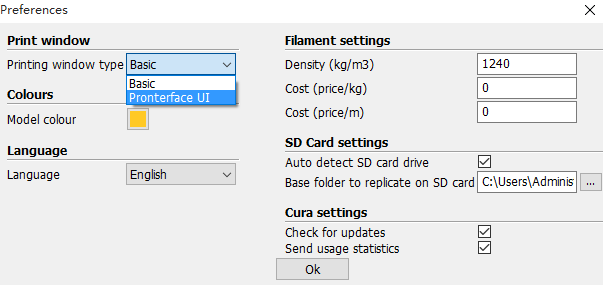
Cura 15.04 打印物体,默认是对打印对象进行部分填充,来节省打印耗材,但是打印一些中空的结构的时候,会出现边框强度不够的情况,导致边缘的强度非常差,这时候需要设置完全填充。如下设置即可。注意: 设置后,最好关闭一下软件重新打开,出现过修改无效的情况!
将NDK编译的第三方静态拷贝到JNI目录下,在Android.mk中添加如下代码
以openssl静态库(libcrypto-static.a)为例
第一种链接方法:LOCAL_LDFLAGS := libcrypto-static.a(不推荐,有编译警告)
第二种链接方法:LOCAL_LDLIBS := libcrypto-static.a(不推荐,有编译警告)
第三种链接方法:(推荐)
|
1 2 3 4 5 6 |
include $(CLEAR_VARS) LOCAL_MODULE := third_static_lib (可以随便起一个名字) LOCAL_SRC_FILES := libcrypto-static.a include $(PREBUILT_STATIC_LIBRARY) //在你要编译的模块中引用third_static_lib LOCAL_STATIC_LIBRARIES := third_static_lib |
|
1 |
$ expect backup.sh |
hostback.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
#!/bin/sh LogFile=~/backup/backup-`date +%Y%m%d`.log #指定日志的名字 BakDir=~/backup #备份文件存放的路径 MD5File=~/backup/md5-`date +%Y%m%d`.txt Sha1File=~/backup/sha1-`date +%Y%m%d`.txt #create backup directory if [ -d $BakDir ] then cd $BakDir touch $LogFile else mkdir -p $BakDir cd $BakDir touch $LogFile fi #backup wordpress datadump=`which mysqldump` wordpressdb="wordpress" #wordpress数据库的名字 wordpresspath=/var/www #wordpress程序文件的位置 mysqluser="root" #数据库的用户名 userpass="password" #用户密码 backupwordpress_tar_gz=$wordpressdb.`date +%Y%m%d`.tar.gz backupwordpress_sql=$wordpressdb.`date +%Y%m%d`.sql if $datadump -u $mysqluser --password=$userpass -h localhost --opt $wordpressdb > $backupwordpress_sql 2>&1 then echo " backup $wordpressdb success" >> $LogFile else echo " backup $wordpressdb error" >> $LogFile exit 1 fi #检验文件尾部是否存在 “-- Dump completed on”,如果存在不存在,则说明备份出错了。 if [ 0 -eq "$(sed '/^$/!h;$!d;g' $backupwordpress_sql | grep -c "Dump completed on")" ]; then echo " backup $wordpressdb error" >> $LogFile exit 1 fi #使用h参数的目的在于把软连接指向的实际内容打包进入,而不是仅仅打包一个软连接 if tar czpfh $backupwordpress_tar_gz $wordpresspath $backupwordpress_sql >/dev/null 2>&1 then echo " backup wordpress success" >> $LogFile rm -f $wordpressdb.`date +%Y%m%d`.sql else echo " backup wordperss error" >> $LogFile exit 1 fi md5sum $backupwordpress_tar_gz >> $MD5File sha1sum $backupwordpress_tar_gz >> $Sha1File |
backup.sh
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 |
#!/usr/bin/expect -f #开启内部动作调试输出,观察是否正确执行 1 代表打开调试,0代表关闭调试 exp_internal 0 set HostAddr "www.mobibrw.com" set HostPort 22 set UserName "user" set BackupShell "hostback.sh" set Password "password" set BakDir "backup" set timeout -1 #由于通过FTP传输的文件格式可能\n被替换为\r\n 的情况,因此需要执行一下 dos2unix 转化到 \n spawn dos2unix $BackupShell expect eof spawn ssh $HostAddr -p $HostPort -l $UserName rm -rf ~/$BackupShell expect -re ".*assword:" send "$Password\r" expect eof spawn scp $BackupShell $UserName@$HostAddr:~/$BackupShell expect -re ".*assword:" send "$Password\r" expect eof spawn ssh $HostAddr -p $HostPort -l $UserName chmod +x ~/$BackupShell expect -re ".*assword:" send "$Password\r" expect eof #解决在群晖NAS系统上TCP超时问题,增加心跳保持参数 #同时注意,远端语言有可能不是英文,因此需要增加LC_ALL=C强制切换到英文,否则后续匹配可能无法完成 spawn ssh $HostAddr -o TCPKeepAlive=yes -o ServerAliveInterval=30 -p $HostPort -l $UserName "LC_ALL=C sudo -E bash ~/$BackupShell" expect -re ".*assword:" send "$Password\r" expect eof spawn scp -r $UserName@$HostAddr:~/$BakDir ./ expect -re ".*assword:" send "$Password\r" expect eof #backup-20151227.log\nbash: warning: setlocale: LC_ALL: cannot change locale (zh_CN.utf8) 这种情况要注意 proc getFilterFile { host port user bakdir password filter regx} { spawn ssh $host -p $port -l $user ls ~/$bakdir | grep $filter expect -re ".*assword:" send "$password\r" expect -re "$regx" expect eof return [string trimright $expect_out(0,string)] } cd ./$BakDir #校验MD5,SHA1 set MD5File [getFilterFile $HostAddr $HostPort $UserName $BakDir $Password "md5" "md5(.*).txt"] puts stdout $MD5File #修改语言环境,否则md5sum,sha1sum返回的结果中可能不会出现"OK",而是会出现“确定” #“失败” if {[info exists ::env(LANG)]==1} { set ORG_LANG "$env(LANG)" puts stdout "$env(LANG)" set env(LANG) "C" puts stdout "$env(LANG)" } if {[info exists ::env(LC_ALL)]==1} { set ORG_LC_ALL "$env(LC_ALL)" puts stdout "$env(LC_ALL)" set env(LC_ALL) "C" puts stdout "$env(LC_ALL)" } spawn md5sum -c $MD5File expect -re ".*OK" expect eof set Sha1File [getFilterFile $HostAddr $HostPort $UserName $BakDir $Password "sha1" "sha1(.*).txt"] puts stdout $Sha1File spawn sha1sum -c $Sha1File expect -re ".*OK" expect eof #还原语言设置 if {[info exists ::env(LANG)]==1} { puts stdout "$env(LANG)" set env(LANG) "$ORG_LANG" puts stdout "$env(LANG)" } if {[info exists ::env(LC_ALL)]==1} { puts stdout "$env(LC_ALL)" set env(LC_ALL) "$ORG_LC_ALL" puts stdout "$env(LC_ALL)" } #打印本次的备份日志出来 set LogFile [getFilterFile $HostAddr $HostPort $UserName $BakDir $Password "backup" "backup(.*).log"] puts stdout $LogFile set f [ open $LogFile r] while { [ gets $f line ] >= 0 } { puts stdout $line;} #删除远端的备份脚本 spawn ssh $HostAddr -p $HostPort -l $UserName sudo rm -rf ~/$BackupShell expect -re ".*assword:" send "$Password\r" expect eof #删除远端的备份目录 spawn ssh $HostAddr -p $HostPort -l $UserName sudo rm -rf ~/$BakDir expect -re ".*assword:" send "$Password\r" expect eof |
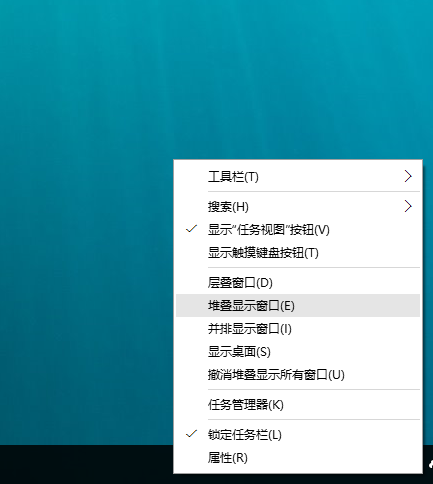
Windows 10下面Android模拟器往往会顶到桌面的最上面,也就是上面的最大最小关闭按钮那一栏超过屏幕的最上面的边缘,导致无法拖动。这个时候是非常痛苦的。简单的修正这个问题的办法如下:
在底层任务栏右击,点击“层叠显示窗口”就可以了。
Windows下面Android Studio提示
|
1 2 3 4 5 |
Errors found while svn working copies detection. Fix it. Can't use Subversion command line client: svn Probably the path to Subversion executable is wrong. Fix it. (show balloon) Can't use Subversion command line client: svn Probably the path to Subversion executable is wrong. Fix it. (show balloon) |
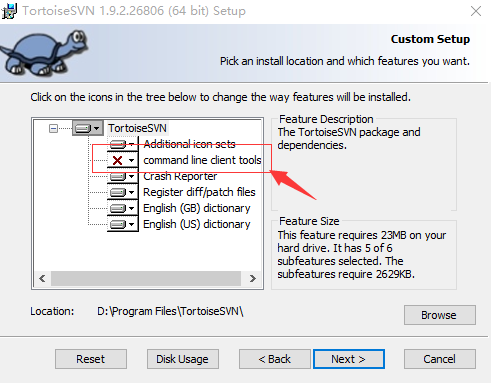
如果安装TortoiseSVN的时候没有选中Command Line Client的话,可能会导致上面的问题。
解决方法就是重新安装Tortoise SVN,在安装的时候选上“command line client tools”即可。
需要把APK Push到模拟器下面的 /system/app 目录下面,报告
|
1 2 |
$ adb push app-debug.apk /system/app failed to copy 'app-debug.apk' to '/system/app/app-debug.apk': Read-only file system |
解决方法
|
1 |
$ adb remount |
|
1 2 |
$ adb push app-debug.apk /system/app failed to copy 'app-debug.apk' to '/system/app/app-debug.apk': Out of memory |
原因众说纷纭,基本上大家都没怎么深究,有些镜像没有这个问题,有些就有问题。
解决方法:
不要使用Eclipse或者Android Studio 或者 AVD Manager的图形界面去启动模拟器,而是使用下面的命令:
|
1 |
$Android_SDK_HOME/tools/emulator -partition-size 256 -avd "模拟器的名字" |
原因,Android 设计问题,如果system/app下面的APK包含SO文件,不会自动安装,需要手工PUSH 到 "/system/lib"目录下面。
5.0之后的Android,最好推送到/system/priv-app目录。
原因,Android 5.0之后,没有实时监视/system/priv-app目录的变化,只有在系统启动的时候才会扫描一下(重启系统很慢,我们可以按照如下操作节约时间),因此需要手工通知一下(有时候需要修改一下权限才可以)。
|
1 2 3 |
$ chown 644 /system/priv-app/my-app.apk $ adb shell am restart |
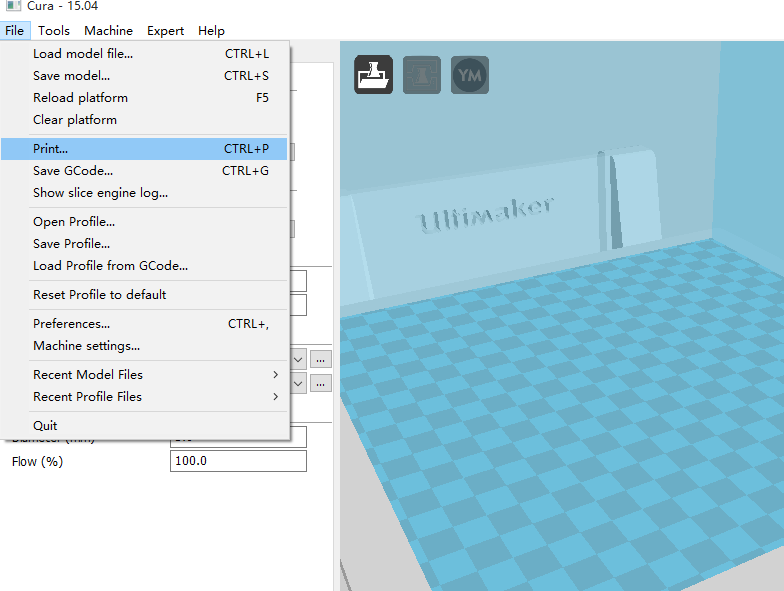
一直使用商家提供的Cura 13进行3D打印,前段日子看到软件已经升级到了15.04版本(注意:最新的Cura 15 提供了两个版本,一个是官方的配合最新的3D打印机的版本,一个是社区版本,我们只能使用社区版本,才有下面的界面),于是下载了一个版本使用,结果发现找不到在Cura 13中调试打印机的页面了。如下图所示是Cura 13的设置页面,其中Jog主要是用来调试打印机的。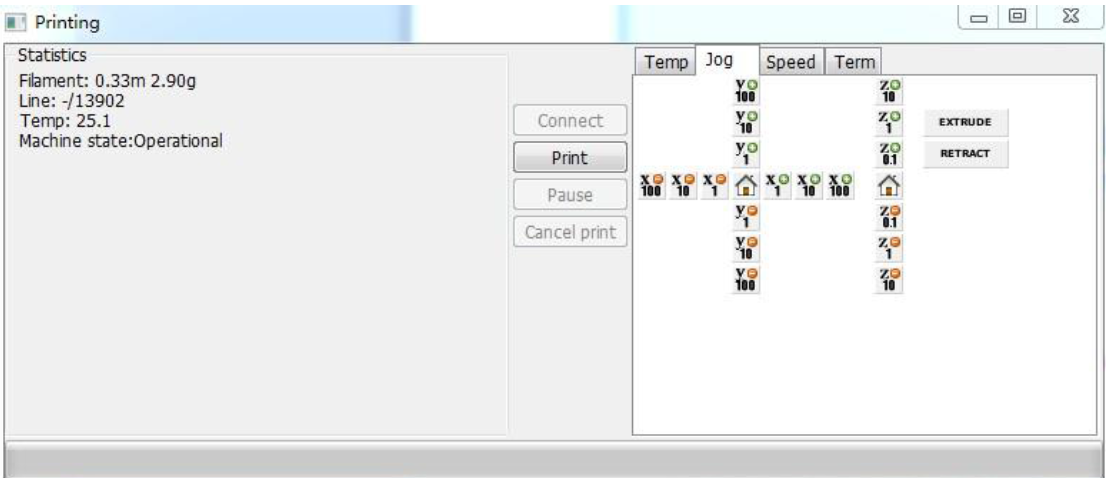
Cura 13 之后的版本精简了打印界面,变成了这个样子,找不到原来的调试页面了。
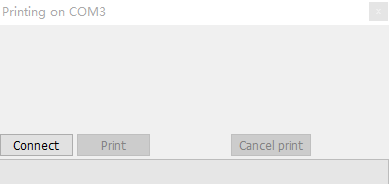
其实这个页面是存在的,只是被隐藏了而已,执行如下操作即可显示出来了。
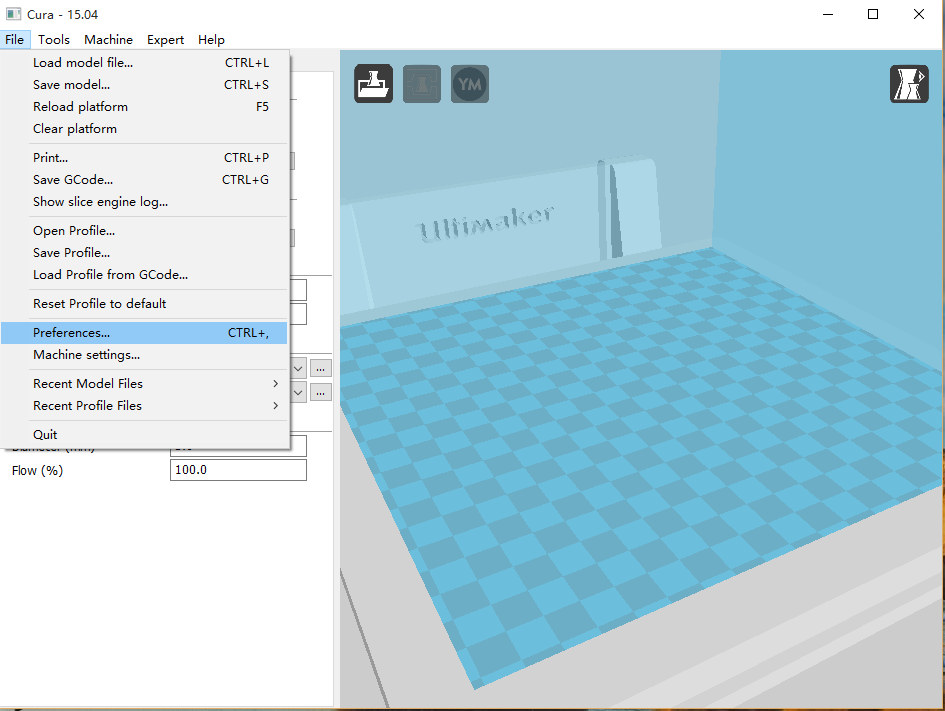
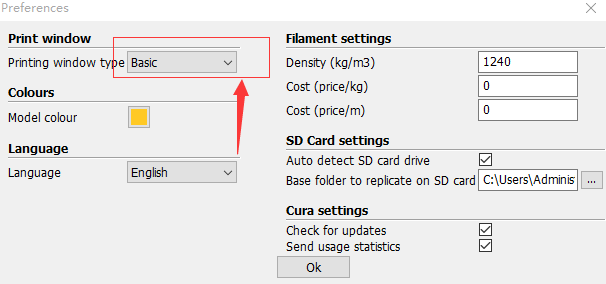
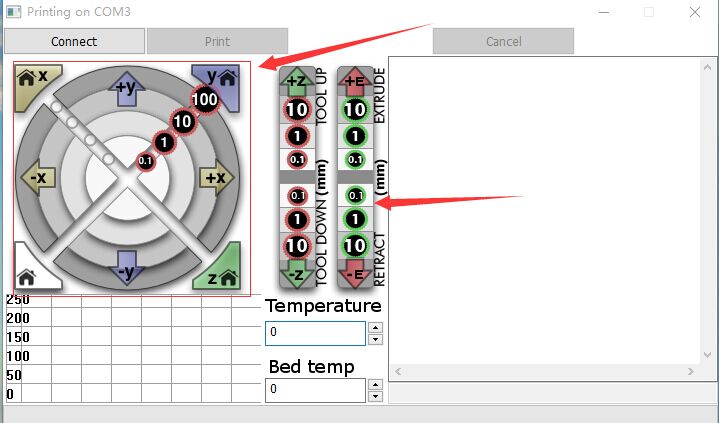
在安装Ubuntu 15.04的时候,由于机器使用的是SSD硬盘,因此在建立HOME分区的时候选择了使用Btrfs格式作为分区格式。一直都是使用正常,直到今天,在向HOME分区拷贝一个16GB的文件的时候提示 “拼接文件出错:设备上没有空间” (英文系统可能会提示 “No space left on device”)。
使用"df"命令查询分区,发现所有分区都是足够的。如下图所示,空间足够使用,尤其是HOME分区,足足有40GB的空间。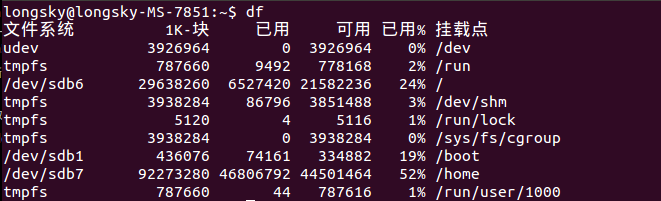
维基百科搜索“btrfs”,简介中标明,最大文件尺寸 16 EiB,显然,16GB的文件,是不会超过这个限制的。
同样是维基百科,btrfs条目,标明 最大文件数量 2^64,显然,120GB的一个硬盘,即使是全部是一个字节的小文件,也达不到这个数字的。
使用"df -i"命令查询Inode信息,发现好奇怪的现象,home所在的分区信息中Inode信息,不管是已经你使用的,还是可以使用的,还是总数,都是 0. 为什么呢?
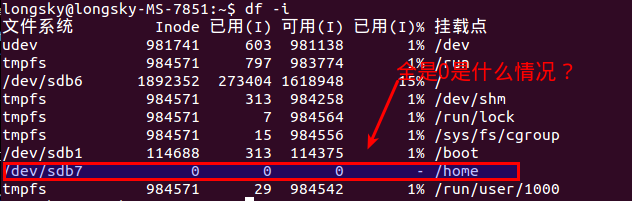 后来才知道,btrfs格式是不能使用df命令的,btrfs有自己的单独的命令查询.
后来才知道,btrfs格式是不能使用df命令的,btrfs有自己的单独的命令查询.
|
1 |
$btrfs fi df /home |

仔细观察一下输出结果,好奇怪,使用df 命令,我们查询到分区的大小在90GB左右,但是这里显示的文件的大小仅仅是43GB,而且已经使用了42.50GB,按照这个显示,自然是空间不足了,那么,我们的空间去了哪里?
这个问题的产生,本质上是btrfs设计导致的,原因归咎于btrfs所采用的COW技术,这项技术需要一个比较大的保留存储空间,但是当空间不足的时候,本应减少保留空间,而显然,默认情况下,没有正确处理这种情况。这个问题在3.18版本之后得到比较好的解决。
对于 btrfs 3.18之前的版本来说,执行如下命令即可.
|
1 |
$btrfs balance start -v -dusage=0 /home |
从3.18版本开始,这个命令是当空间不足出现的时候,默认执行的,很遗憾,15.04的btrfs版本号是3.17.
显示btfs文件系统信息
|
1 2 3 4 5 6 |
$sudo btrfs fi show Label: none uuid: 6fb44e01-f148-41c7-8448-17b58089f908 Total devices 1 FS bytes used 43.42GiB devid 1 size 88.00GiB used 46.06GiB path /dev/sdb7 Btrfs v3.17 |
btrfs磁盘文件检查(需要重启进入修复模式中执行)
|
1 |
sudo btrfs check --repair /dev/sda7 |
Btrfs Problem_FAQ
Ubuntu thinks btrfs disk is full but its not
由于国外网站经常打不开,因此内容直接复制到这里 原文链接
Btrfs is different from traditional filesystems. It is not just a layer that translates filenames into offsets on a block device, it is more of a layer that combines a traditional filesystem with LVM and RAID. And like LVM, it has the concept of allocating space on the underlying device, but not actually using it for files.
A traditional filesystem is divided into files and free space. It is easy to calculate how much space is used or free:
|
1 2 |
|--------files--------| | |------------------------drive partition-------------------------------| |
Btrfs combines LVM, RAID and a filesystem. The drive is divided into subvolumes, each dynamically sized and replicated:
|
1 2 3 |
|--files--| |--files--| |files| | | |----@raid1----|------@raid1-------|-----@home-----|metadata| | |------------------------drive partition-------------------------------| |
The diagram shows the partition being divided into two subvolumes and metadata. One of the subvolumes is duplicated (RAID1), so there are two copies of every file on the device. Now we not only have the concept of how much space is free at the filesystem layer, but also how much space is free at the block layer (drive partition) below it. Space is also taken up by metadata.
When considering free space in Btrfs, we have to clarify which free space we are talking about - the block layer, or the file layer? At the block layer, data is allocated in 1GB chunks, so the values are quite coarse, and might not bear any relation to the amount of space that the user can actually use. At the file layer, it is impossible to report the amount of free space because the amount of space depends on how it is used. In the above example, a file stored on the replicated subvolume @raid1 will take up twice as much space as the same file stored on the @homesubvolume. Snapshots only store copies of files that have been subsequently modified. There is no longer a 1-1 mapping between a file as the user sees it, and a file as stored on the drive.
You can check the free space at the block layer with btrfs filesystem show / and the free space at the subvolume layer with btrfs filesystem df /
|
1 2 3 |
# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/sda4_crypt 38G 12G 13M 100% / |
For this mounted subvolume, df reports a drive of total size 38G, with 12G used, and 13M free. 100% of the available space has been used. Remember that the total size 38G is divided between different subvolumes and metadata - it is not exclusive to this subvolume.
|
1 2 3 4 5 6 |
# btrfs filesystem df / Data, single: total=9.47GiB, used=9.46GiB System, DUP: total=8.00MiB, used=16.00KiB System, single: total=4.00MiB, used=0.00 Metadata, DUP: total=13.88GiB, used=1.13GiB Metadata, single: total=8.00MiB, used=0.00 |
Each line shows the total space and the used space for a different data type and replication type. The values shown are data stored rather than raw bytes on the drive, so if you're using RAID-1 or RAID-10 subvolumes, the amount of raw storage used is double the values you can see here.
The first column shows the type of item being stored (Data, System, Metadata). The second column shows whether a single copy of each item is stored (single), or whether two copies of each item are stored (DUP). Two copies are used for sensitive data, so there is a backup if one copy is corrupted. For DUP lines, the used value has to be doubled to get the amount of space used on the actual drive (because btrfs fs df reports data stored, not drive space used). The third and fourth columns show the total and used space. There is no free column, since the amount of "free space" is dependent on how it is used.
The thing that stands out about this drive is that you have 9.47GiB of space allocated for ordinary files of which you have used 9.46GiB - this is why you are getting No space left on device errors. You have 13.88GiB of space allocated for duplicated metadata, of which you have used 1.13GiB. Since this metadata is DUP duplicated, it means that 27.76GiB of space has been allocated on the actual drive, of which you have used 2.26GiB. Hence 25.5GiB of the drive is not being used, but at the same time is not available for files to be stored in. This is the "Btrfs huge metadata allocated"problem. To try and correct this, run btrfs balance start -m /. The -m parameter tells btrfs to only re-balance metadata.
A similar problem is running out of metadata space. If the output had shown that the metadata were actually full (used value close to total), then the solution would be to try and free up almost empty (<5% used) data blocks using the command btrfs balance start -dusage=5 /. These free blocks could then be reused to store metadata.
For more details see the Btrfs FAQs: