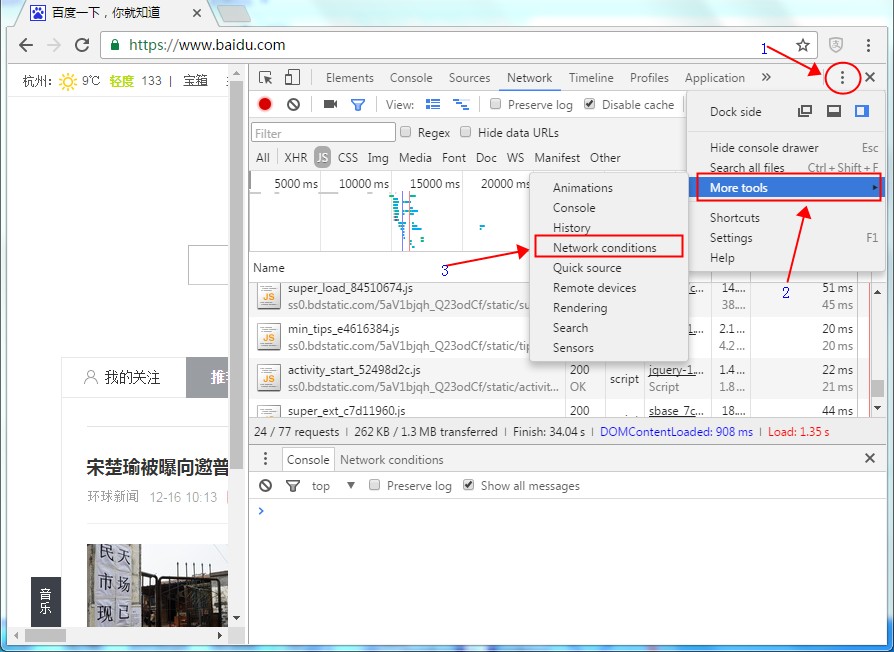
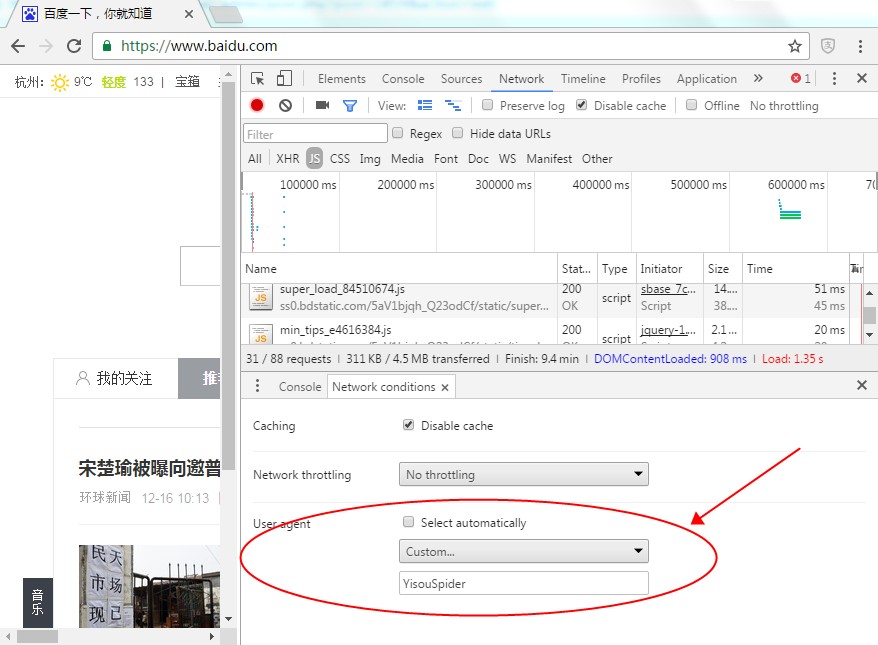
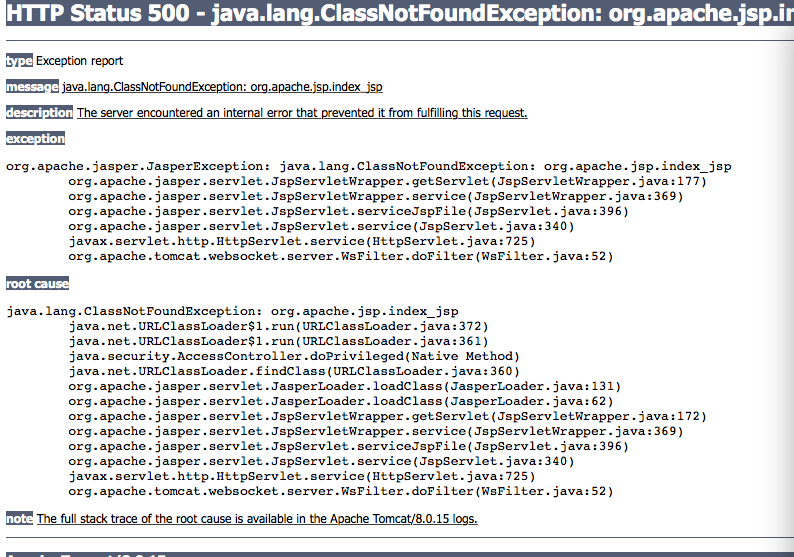
严重: Exception starting filter struts2
java.lang.ClassNotFoundException: org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1892)
at org.apache.catalina.loader.WebappClassLoaderBase.loadClass(WebappClassLoaderBase.java:1735)
at org.apache.catalina.core.DefaultInstanceManager.loadClass(DefaultInstanceManager.java:504)
at org.apache.catalina.core.DefaultInstanceManager.loadClassMaybePrivileged(DefaultInstanceManager.java:486)
at org.apache.catalina.core.DefaultInstanceManager.newInstance(DefaultInstanceManager.java:113)
at org.apache.catalina.core.ApplicationFilterConfig.getFilter(ApplicationFilterConfig.java:258)
at org.apache.catalina.core.ApplicationFilterConfig.<init>(ApplicationFilterConfig.java:105)
at org.apache.catalina.core.StandardContext.filterStart(StandardContext.java:4958)
at org.apache.catalina.core.StandardContext.startInternal(StandardContext.java:5652)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:145)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:899)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:875)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:652)
at org.apache.catalina.startup.HostConfig.manageApp(HostConfig.java:1863)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.tomcat.util.modeler.BaseModelMBean.invoke(BaseModelMBean.java:301)
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.invoke(DefaultMBeanServerInterceptor.java:819)
at com.sun.jmx.mbeanserver.JmxMBeanServer.invoke(JmxMBeanServer.java:801)
at org.apache.catalina.mbeans.MBeanFactory.createStandardContext(MBeanFactory.java:618)
at org.apache.catalina.mbeans.MBeanFactory.createStandardContext(MBeanFactory.java:565)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.tomcat.util.modeler.BaseModelMBean.invoke(BaseModelMBean.java:301)
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.invoke(DefaultMBeanServerInterceptor.java:819)
at com.sun.jmx.mbeanserver.JmxMBeanServer.invoke(JmxMBeanServer.java:801)
at javax.management.remote.rmi.RMIConnectionImpl.doOperation(RMIConnectionImpl.java:1487)
at javax.management.remote.rmi.RMIConnectionImpl.access$300(RMIConnectionImpl.java:97)
at javax.management.remote.rmi.RMIConnectionImpl$PrivilegedOperation.run(RMIConnectionImpl.java:1328)
at javax.management.remote.rmi.RMIConnectionImpl.doPrivilegedOperation(RMIConnectionImpl.java:1420)
at javax.management.remote.rmi.RMIConnectionImpl.invoke(RMIConnectionImpl.java:848)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at sun.rmi.server.UnicastServerRef.dispatch(UnicastServerRef.java:322)
at sun.rmi.transport.Transport$2.run(Transport.java:202)
at sun.rmi.transport.Transport$2.run(Transport.java:199)
at java.security.AccessController.doPrivileged(Native Method)
at sun.rmi.transport.Transport.serviceCall(Transport.java:198)
at sun.rmi.transport.tcp.TCPTransport.handleMessages(TCPTransport.java:567)
at sun.rmi.transport.tcp.TCPTransport$ConnectionHandler.run0(TCPTransport.java:828)
at sun.rmi.transport.tcp.TCPTransport$ConnectionHandler.access$400(TCPTransport.java:619)
at sun.rmi.transport.tcp.TCPTransport$ConnectionHandler$1.run(TCPTransport.java:684)
at sun.rmi.transport.tcp.TCPTransport$ConnectionHandler$1.run(TCPTransport.java:681)
at java.security.AccessController.doPrivileged(Native Method)
at sun.rmi.transport.tcp.TCPTransport$ConnectionHandler.run(TCPTransport.java:681)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)