由于国外网站经常打不开,因此内容直接复制到这里 原文链接
Btrfs is different from traditional filesystems. It is not just a layer that translates filenames into offsets on a block device, it is more of a layer that combines a traditional filesystem with LVM and RAID. And like LVM, it has the concept of allocating space on the underlying device, but not actually using it for files.
A traditional filesystem is divided into files and free space. It is easy to calculate how much space is used or free:
|
|
|--------files--------| | |------------------------drive partition-------------------------------| |
Btrfs combines LVM, RAID and a filesystem. The drive is divided into subvolumes, each dynamically sized and replicated:
|
|
|--files--| |--files--| |files| | | |----@raid1----|------@raid1-------|-----@home-----|metadata| | |------------------------drive partition-------------------------------| |
The diagram shows the partition being divided into two subvolumes and metadata. One of the subvolumes is duplicated (RAID1), so there are two copies of every file on the device. Now we not only have the concept of how much space is free at the filesystem layer, but also how much space is free at the block layer (drive partition) below it. Space is also taken up by metadata.
When considering free space in Btrfs, we have to clarify which free space we are talking about - the block layer, or the file layer? At the block layer, data is allocated in 1GB chunks, so the values are quite coarse, and might not bear any relation to the amount of space that the user can actually use. At the file layer, it is impossible to report the amount of free space because the amount of space depends on how it is used. In the above example, a file stored on the replicated subvolume @raid1 will take up twice as much space as the same file stored on the @homesubvolume. Snapshots only store copies of files that have been subsequently modified. There is no longer a 1-1 mapping between a file as the user sees it, and a file as stored on the drive.
You can check the free space at the block layer with btrfs filesystem show / and the free space at the subvolume layer with btrfs filesystem df /
|
|
# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/sda4_crypt 38G 12G 13M 100% / |
For this mounted subvolume, df reports a drive of total size 38G, with 12G used, and 13M free. 100% of the available space has been used. Remember that the total size 38G is divided between different subvolumes and metadata - it is not exclusive to this subvolume.
|
|
# btrfs filesystem df / Data, single: total=9.47GiB, used=9.46GiB System, DUP: total=8.00MiB, used=16.00KiB System, single: total=4.00MiB, used=0.00 Metadata, DUP: total=13.88GiB, used=1.13GiB Metadata, single: total=8.00MiB, used=0.00 |
Each line shows the total space and the used space for a different data type and replication type. The values shown are data stored rather than raw bytes on the drive, so if you're using RAID-1 or RAID-10 subvolumes, the amount of raw storage used is double the values you can see here.
The first column shows the type of item being stored (Data, System, Metadata). The second column shows whether a single copy of each item is stored (single), or whether two copies of each item are stored (DUP). Two copies are used for sensitive data, so there is a backup if one copy is corrupted. For DUP lines, the used value has to be doubled to get the amount of space used on the actual drive (because btrfs fs df reports data stored, not drive space used). The third and fourth columns show the total and used space. There is no free column, since the amount of "free space" is dependent on how it is used.
The thing that stands out about this drive is that you have 9.47GiB of space allocated for ordinary files of which you have used 9.46GiB - this is why you are getting No space left on device errors. You have 13.88GiB of space allocated for duplicated metadata, of which you have used 1.13GiB. Since this metadata is DUP duplicated, it means that 27.76GiB of space has been allocated on the actual drive, of which you have used 2.26GiB. Hence 25.5GiB of the drive is not being used, but at the same time is not available for files to be stored in. This is the "Btrfs huge metadata allocated"problem. To try and correct this, run btrfs balance start -m /. The -m parameter tells btrfs to only re-balance metadata.
A similar problem is running out of metadata space. If the output had shown that the metadata were actually full (used value close to total), then the solution would be to try and free up almost empty (<5% used) data blocks using the command btrfs balance start -dusage=5 /. These free blocks could then be reused to store metadata.
For more details see the Btrfs FAQs:
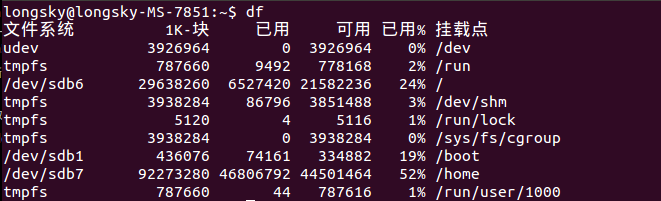
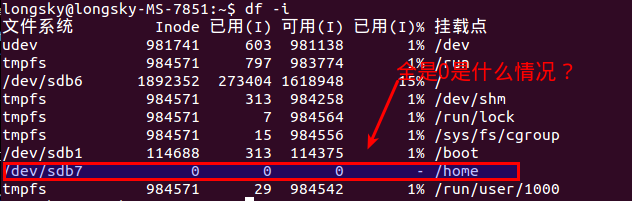 后来才知道,btrfs格式是不能使用df命令的,btrfs有自己的单独的命令查询.
后来才知道,btrfs格式是不能使用df命令的,btrfs有自己的单独的命令查询.