开启VNC功能,步骤参考下图:
月度归档: 2021 年 5 月
浮点运算潜在的结果不一致问题
昨天阿楠发现了项目中的一个 bug ,是因为浮点运算的前后不一致导致的。明明是完全相同的 C 代码,参数也严格一致,但是计算出了不相同的结果。我对这个现象非常感兴趣,仔细研究了一下成因。
原始代码比较繁杂。在弄清楚原理后,我简化了出问题的代码,重现了这个问题:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
static void foo(float x) { float xx = x * 0.01f; printf("%d\n", (int)(x * 0.01f)); printf("%d\n", (int)xx); } int main() { foo(2000.0f); return 0; } |
使用 gcc 4.9.2 ,强制使用 x87 浮点运算编译运行,你会发现令人诧异的结果。
|
1 2 3 4 |
gcc a.c -mfpmath=387 19 20 |
前一次的输出是 19 ,后一次是 20 。
这是为什么呢?让我们来看看 gcc 生成的代码,我截取了相关的段落:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
flds 16(%rbp) flds .LC0(%rip) fmulp %st, %st(1) fstps -4(%rbp) ; 1. x * 0.01f 结果保存到内存中的 float 变量中 flds 16(%rbp) flds .LC0(%rip) fmulp %st, %st(1) fisttpl -20(%rbp) ; 2. x * 0.01f 结果直接转换为整型 movl -20(%rbp), %eax movl %eax, %edx leaq .LC1(%rip), %rcx call printf flds -4(%rbp) ; 3. 读出 1. 保存的乘法结果 fisttpl -20(%rbp) movl -20(%rbp), %eax movl %eax, %edx leaq .LC1(%rip), %rcx call printf |
这里我做了三行注释。
首先,0.01 是无法精确表示成 2 进制的,所以 * 0.01 这个操作一定会存在误差。
两次运算都是 x * 0.01f ,虽然按 C 语言的转换规则,表达式中都是 float 时,按 float 精度运算。但这里 gcc 生成的代码并没有严格设置 FPU 的精度控制,在注释 2 这个地方,乘法结果是直接从浮点寄存器转换为整数的。而在注释 1 这个地方,把乘法结果通过 fstps 以低精度形式保存到内存,再在注释 3 的地方 flds 读回。
所以在注释 2 和注释 3 的地方,浮点寄存器 st 内的值其实是有差别的,这导致了 fisttpl 转换为整数后结果不同。
2018 年 6 月 14 日补充:
在 DDJ 1997 年的一篇访谈文章中,谈及了类似的问题。
引用如下:
Let me give an example, which arose yesterday. A student was doing a computation involving a simulation of a plasma. It turns out that as you go through this computation there will be certain barriers. This may be a reflecting barrier. That means if a particle moves through this barrier, it should not really go through, it should be reflected. Others may be absorbing, others may be periodic. He has a piece of code that is roughly
|
1 2 3 4 5 6 7 8 9 |
float x, y, z; int j; ... x = y + z; if (x >= j) replace (x); y = x; ... |
As far as we can tell, when he turns on optimization, the value of x is computed in a register with extra width. This happens on the Intel machine because the registers have extra width. It also happens on some others. The value of x that he computes is not, in fact, a float. It's in a register that's wider. The machine stores x somewhere, and in the course of doing that, converts it to a float. But the value used in the comparison is the value in the register. That x is wider. The condition that the register x be greater than or equal to j doesn't guarantee that x, when stored in y, will be less than j. Sometimes y=j, and that should never be. My student counted on what compiler writers call "referential transparency" and was disappointed because the compiler writer saved some time in optimization by not reloading the register from the stored value.
云风 提交于 July 25, 2017 10:31 AM | 固定链接
COMMENTS
大神,同样的问题。在C#里,如果Debug编译,选择AnyCPU,结果分别是20、19.如果Release编译,结果就是19、19
Posted by: Yao | (16) October 30, 2017 05:49 PM
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
Posted by: asd123 | (15) September 18, 2017 07:12 PM
这种浮点型数据运算结果不一致有什么办法规避或者解决呢?
Posted by: ahuang | (14) August 9, 2017 03:35 PM
https://gcc.gnu.org/bugzilla/show_bug.cgi?id=323
Posted by: Nothing | (13) July 27, 2017 11:49 PM
确实是与优化选项和编译器版本有很大的关系。弄出代码完全一致,但在不同编译器或者不同编译选项上输出不同结果的浮点运算是很容易的。
Posted by: ghosting | (12) July 27, 2017 08:48 AM
@ghosting
这个问题和 c 代码是否完全一致关系不大。构造出一个c代码完全一致,但结果有差别的例子也是可以的,就是比较繁琐,我懒得做。而且和优化选项,gcc 版本关系更大,很难重现。
Posted by: cloud | (11) July 27, 2017 12:35 AM
两次运算不是完全相同的C代码,浮点数并不是实数,这个结果也没有什么可以诧异的。
C/C++对于浮点数的定义很宽松的,标准上甚至没有定义过float必须是32位。
x87这种硬件实际上是支持Extended precision格式,但不完全支持single/double格式(只支持存储相关的操作)。
VC对这种情况加了个strictfp的扩展,使得每次操作的中间结果都会转换下,gcc没有等价的玩意。
本来写出没有问题的浮点代码就有很多点需要注意,在x87上因为硬件的关系会更加棘手一点,最简单的办法还是用strictfp模式或者直接制定fpu为sse。
Posted by: ghosting | (10) July 26, 2017 08:16 PM
@dwing
这只是一个简化的例子。和在 C 语言中是否明确将中间结果暂存在局部变量里无关。
两个完全相同的长表达式,如果有中间结果相同,编译器一样会临时放在内存中的。
实际的代码中大约是
x * 0.01f / a + b 这样的表达式被 inline 后重复了两次,而 由于连续做相同运算,以及恰巧的上下文关系, x * 0.01f 的计算结果被暂存起来了。代码生成和上下文关系很大,不方便举例罢了。
另外,四舍五入并不能解决这个问题,四舍五入只是换了一个截断点而已,把 [1,2) 取整成 1 和把 [0.5,1.5) 取整成 1 只是在数轴上偏移了 0.5 。一样可以制造出不一致。
Posted by: Cloud | (9) July 26, 2017 03:21 PM
多谢dwing,原来C89/90就已经不提升精度了。
Posted by: stirp | (8) July 26, 2017 10:54 AM
常写浮点运算程序的人对取整操作是很敏感的,一般是能不取整就不取整,实在要取整肯定要想想把连续的值离散化的意义,是否应该四舍五入.
另外追求完全一致的计算本来就不应该用浮点数.
Posted by: dwing | (7) July 26, 2017 10:01 AM
这两次运算不能叫完全相同的C代码吧.
虽然从语言上定义此表达式的精度是float,但实际上计算结果的临时数值是尽可能保留精度的.
x87寄存器是80位,从计算结果转成int实际上是从80位精度转换,而中间用float变量保存再去取整就会有细微差异,换成double也可能不一致.
Posted by: dwing | (6) July 26, 2017 09:55 AM
C 语言规范:表达式里最高精度是 float ,那么表达式的值精度就是 float 。没有相乘提升到 double 的说法。
第一个写成 (int)((float)(x * 0.01f)) 也是一样的,并不是对 double 取整的问题。
Posted by: Cloud | (5) July 25, 2017 09:07 PM
刚刚被小伙伴提示默认情况下float相乘是自动提升精度到double的,因此第一次输出就应该是对double取整的。
x87 浮点运算的效果是float相乘结果还是float么?本地不支持387,没法测试。
Posted by: stirp | (4) July 25, 2017 06:57 PM
gcc 4.8.4没有重现
Posted by: alphachen | (3) July 25, 2017 03:12 PM
这种问题不注意真是很意外呢。还和编译器版本相关,gcc 7.1.1 没有复现。
Posted by: 依云 | (2) July 25, 2017 01:47 PM
所以这种计算还是需要四舍五入,强制转换成整形,就直接截断了,估计就是19.999999跟20.000001的差别
参考链接
aapt/aapt2命令获取apk详细信息(包名、版本号、版本名称、兼容api级别、启动Activity等)
aapt命令获取apk详细信息(包名、版本号、版本名称、兼容api级别、启动Activity等)
第一步:找到aapt/AAPT2
找到sdk的根目录,然后找到build-tools文件夹,然后会看到一些build-tools的版本号,随便点开一个,就可以看到aapt了,如下图
chrome独立安装包下载
在线安装包下载地址:
独立安装包下载地址:
https://www.google.cn/chrome/?platform=win64&standalone=1
https://www.google.cn/chrome/?platform=win32&standalone=1
最新稳定版:
https://www.google.cn/intl/zh-CN/chrome/browser/?standalone=1&platform=win64
最新测试版:
https://www.google.cn/intl/zh-CN/chrome/browser/?standalone=1&extra=betachannel&platform=win64
最新开发版:
https://www.google.cn/intl/zh-CN/chrome/browser/?standalone=1&extra=devchannel&platform=win64
参考链接
系统分析师试题分析 索引式文件的索引节点
如果一个索引式文件的索引节点有10个直接块,1个一级间接块,1个二级间接块,1个三级间接块。假设每个数据块的大小是512个字节,一个索引指针占用4个字节。假设索引节点已经在内存中,那么访问该文件偏移地址在6000字节的数据需要再访问 ( ) 次磁盘。
A.1
B.2
C.3
D.4
正确答案
B
答案解析
[解析] 因为每个数据块的大小是512个字节,且前10块可以直接寻址,得出1~5120字节范围内可以直接寻址。对于间接索引块(索引块的大小也是512字节),一个索引指针占4字节,则一个索引块可以映射512/4=128个数据块,因为每个数据块的大小是512个字节,合计64KB。6000B-5120B=880B<64KB,所以只需一次映射就够了。因此,第1次,取索引指针,第2次读数据,一共需要两次访问。
霍纳法则
多项式计算
在计算机科学里,我们会经常遇到一些关于计算多项式的问题,例如计算当 ${x}=2$ 时 $2x^4 - 3x^3 + 5x^2 + x - 7$ 的值。我们首先能够想到的方法就是求出每一项的值,然后把它们全部加起来。如果多项式的阶数不高,这种方法完全可行,而且更容易理解,可是如果把这个问题推广到 $n$ 阶,即计算 $a_nx^n + a_{n-1}x^{n-1} + ··· + a_2x^2 + a_1x + a_0 $ 的值,而且当 $n$ 很大时,这种算法就显得力不从心了。
这里以 $2x^4 - 3x^3 + 5x^2 + x - 7$ 为例计算当 $x = 4$ 时的值。下面是直接求解的代码:
|
1 2 3 4 5 6 7 8 9 |
def poly_bf(coeffi_list, x): degree = len(coeffi_list) - 1 # 最高次项 result = 0 for i in range(degree+1): coeffi = coeffi_list[i]; poly = 1 for j in range(degree-i-1, -1, -1): poly *= x # 计算 x^i result += coeffi * poly return result |
直接求解的方法的复杂度等于多少呢?我们知道,计算机在计算乘法的时候的时间开销要大于加减法的时间开销,所以这里的复杂度大致看做是执行乘法运算的次数。
$T(n)=\sum_{i=1}^{n}{i+1}=2+3+\cdots+n+1=\frac{n(n+3)}{2}\in\Theta(n^2) $
最后得到时间复杂度为 $Θ(n^2)$。
霍纳法则
霍纳法则(Horner’s rule)可以将上面的多项式转化成下面的形式:
$p(x)=(\cdots(a_nx+a_{n-1})x+\cdots)x+a_0"$
假设还是计算当 $x = 4$ 时 $2x^4 - 3x^3 + 5x^2 + x - 7$ 的值,我们需要先将其转换为 $x(x(x(2x - 3) + 5) + 1) - 7$ 的形式,为了更好地呈现每一步的计算过程,我们可以构建出下面的表格:
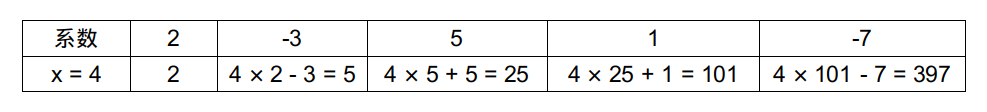
实现霍纳法则的代码非常简单,只需要用一个循环即可。
|
1 2 3 4 5 6 |
def poly_horner(coeffi_list, x): degree = len(coeffi_list) - 1 # 最高次项 result = coeffi_list[0] for i in range(1, degree+1): result = result * x + coeffi_list[i] return result |
经过霍纳法则变换的多项式只需要执行 $n$ 次乘法运算便可以得到 $n$ 阶多项式的值,所以复杂度自然就为 $Θ(n)$ 。跟直接求解相比有了明显的提升,根本原因在于我们对问题做了一个变换,使其变得更容易求解。