[This post is by Elliott Hughes, a Software Engineer on the Dalvik team. — Tim Bray]
If you don’t write native code that uses JNI, you can stop reading now. If you do write native code that uses JNI, you really need to read this.
What’s changing, and why?
Every developer wants a good garbage collector. The best garbage collectors move objects around. This lets them offer very cheap allocation and bulk deallocation, avoids heap fragmentation, and may improve locality. Moving objects around is a problem if you’ve handed out pointers to them to native code. JNI uses types such as jobject to solve this problem: rather than handing out direct pointers, you’re given an opaque handle that can be traded in for a pointer when necessary. By using handles, when the garbage collector moves an object, it just has to update the handle table to point to the object’s new location. This means that native code won’t be left holding dangling pointers every time the garbage collector runs.
In previous releases of Android, we didn’t use indirect handles; we used direct pointers. This didn’t seem like a problem as long as we didn’t have a garbage collector that moves objects, but it let you write buggy code that still seemed to work. In Ice Cream Sandwich, even though we haven't yet implemented such a garbage collector, we've moved to indirect references so you can start detecting bugs in your native code.
Ice Cream Sandwich features a JNI bug compatibility mode so that as long as your AndroidManifest.xml’s targetSdkVersion is less than Ice Cream Sandwich, your code is exempt. But as soon as you update your targetSdkVersion, your code needs to be correct.
CheckJNI has been updated to detect and report these errors, and in Ice Cream Sandwich, CheckJNI is on by default if debuggable="true" in your manifest.
A quick primer on JNI references
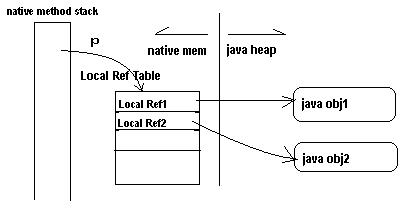
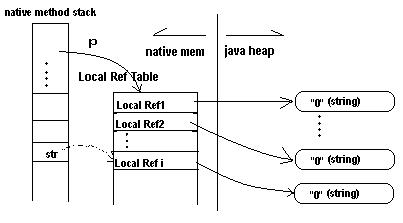
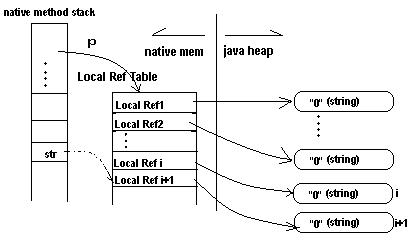
In JNI, there are several kinds of reference. The two most important kinds are local references and global references. Any given jobject can be either local or global. (There are weak globals too, but they have a separate type, jweak, and aren’t interesting here.)
The global/local distinction affects both lifetime and scope. A global is usable from any thread, using that thread’s JNIEnv*, and is valid until an explicit call to DeleteGlobalRef(). A local is only usable from the thread it was originally handed to, and is valid until either an explicit call to DeleteLocalRef() or, more commonly, until you return from your native method. When a native method returns, all local references are automatically deleted.
In the old system, where local references were direct pointers, local references were never really invalidated. That meant you could use a local reference indefinitely, even if you’d explicitly called DeleteLocalRef() on it, or implicitly deleted it with PopLocalFrame()!
Although any given JNIEnv* is only valid for use on one thread, because Android never had any per-thread state in a JNIEnv*, it used to be possible to get away with using a JNIEnv* on the wrong thread. Now there’s a per-thread local reference table, it’s vital that you only use a JNIEnv* on the right thread.
Those are the bugs that ICS will detect. I’ll go through a few common cases to illustrate these problems, how to spot them, and how to fix them. It’s important that you do fix them, because it’s likely that future Android releases will utilize moving collectors. It will not be possible to offer a bug-compatibility mode indefinitely.
Common JNI reference bugs
Bug: Forgetting to call NewGlobalRef() when stashing a jobject in a native peer
If you have a native peer (a long-lived native object corresponding to a Java object, usually created when the Java object is created and destroyed when the Java object’s finalizer runs), you must not stash a jobject in that native object, because it won’t be valid next time you try to use it. (Similar is true of JNIEnv*s. They might be valid if the next native call happens on the same thread, but they won’t be valid otherwise.)
class MyPeer {
public:
MyPeer(jstring s) {
str_ = s; // Error: stashing a reference without ensuring it’s global.
}
jstring str_;
};
static jlong MyClass_newPeer(JNIEnv* env, jclass) {
jstring local_ref = env->NewStringUTF("hello, world!");
MyPeer* peer = new MyPeer(local_ref);
return static_cast<jlong>(reinterpret_cast<uintptr_t>(peer));
// Error: local_ref is no longer valid when we return, but we've stored it in 'peer'.
}
static void MyClass_printString(JNIEnv* env, jclass, jlong peerAddress) {
MyPeer* peer = reinterpret_cast<MyPeer*>(static_cast<uintptr_t>(peerAddress));
// Error: peer->str_ is invalid!
ScopedUtfChars s(env, peer->str_);
std::cout << s.c_str() << std::endl;
}
The fix for this is to only store JNI global references. Because there’s never any automatic cleanup of JNI global references, it’s critically important that you clean them up yourself. This is made slightly awkward by the fact that your destructor won’t have a JNIEnv*. The easiest fix is usually to have an explicit ‘destroy‘ function for your native peer, called from the Java peer’s finalizer:
class MyPeer {
public:
MyPeer(JNIEnv* env, jstring s) {
this->s = env->NewGlobalRef(s);
}
~MyPeer() {
assert(s == NULL);
}
void destroy(JNIEnv* env) {
env->DeleteGlobalRef(s);
s = NULL;
}
jstring s;
};
You should always have matching calls to NewGlobalRef()/DeleteGlobalRef(). CheckJNI will catch global reference leaks, but the limit is quite high (2000 by default), so watch out.
If you do have this class of error in your code, the crash will look something like this:
JNI ERROR (app bug): accessed stale local reference 0x5900021 (index 8 in a table of size 8)
JNI WARNING: jstring is an invalid local reference (0x5900021)
in LMyClass;.printString:(J)V (GetStringUTFChars)
"main" prio=5 tid=1 RUNNABLE
| group="main" sCount=0 dsCount=0 obj=0xf5e96410 self=0x8215888
| sysTid=11044 nice=0 sched=0/0 cgrp=[n/a] handle=-152574256
| schedstat=( 156038824 600810 47 ) utm=14 stm=2 core=0
at MyClass.printString(Native Method)
at MyClass.main(MyClass.java:13)
If you’re using another thread’s JNIEnv*, the crash will look something like this:
JNI WARNING: threadid=8 using env from threadid=1
in LMyClass;.printString:(J)V (GetStringUTFChars)
"Thread-10" prio=5 tid=8 NATIVE
| group="main" sCount=0 dsCount=0 obj=0xf5f77d60 self=0x9f8f248
| sysTid=22299 nice=0 sched=0/0 cgrp=[n/a] handle=-256476304
| schedstat=( 153358572 709218 48 ) utm=12 stm=4 core=8
at MyClass.printString(Native Method)
at MyClass$1.run(MyClass.java:15)
Bug: Mistakenly assuming FindClass() returns global references
FindClass() returns local references. Many people assume otherwise. In a system without class unloading (like Android), you can treat jfieldID and jmethodID as if they were global. (They’re not actually references, but in a system with class unloading there are similar lifetime issues.) But jclass is a reference, and FindClass() returns local references. A common bug pattern is “static jclass”. Unless you’re manually turning your local references into global references, your code is broken. Here’s what correct code should look like:
static jclass gMyClass;
static jclass gSomeClass;
static void MyClass_nativeInit(JNIEnv* env, jclass myClass) {
// ‘myClass’ (and any other non-primitive arguments) are only local references.
gMyClass = env->NewGlobalRef(myClass);
// FindClass only returns local references.
jclass someClass = env->FindClass("SomeClass");
if (someClass == NULL) {
return; // FindClass already threw an exception such as NoClassDefFoundError.
}
gSomeClass = env->NewGlobalRef(someClass);
}
If you do have this class of error in your code, the crash will look something like this:
JNI ERROR (app bug): attempt to use stale local reference 0x4200001d (should be 0x4210001d)
JNI WARNING: 0x4200001d is not a valid JNI reference
in LMyClass;.useStashedClass:()V (IsSameObject)
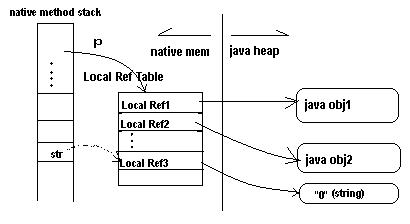
Bug: Calling DeleteLocalRef() and continuing to use the deleted reference
It shouldn’t need to be said that it’s illegal to continue to use a reference after calling DeleteLocalRef() on it, but because it used to work, so you may have made this mistake and not realized. The usual pattern seems to be where native code has a long-running loop, and developers try to clean up every single local reference as they go to avoid hitting the local reference limit, but they accidentally also delete the reference they want to use as a return value!
The fix is trivial: don’t call DeleteLocalRef() on a reference you’re going to use (where “use” includes “return”).
Bug: Calling PopLocalFrame() and continuing to use a popped reference
This is a more subtle variant of the previous bug. The PushLocalFrame() and PopLocalFrame() calls let you bulk-delete local references. When you call PopLocalFrame(), you pass in the one reference from the frame that you’d like to keep (typically for use as a return value), or NULL. In the past, you’d get away with incorrect code like the following:
static jobjectArray MyClass_returnArray(JNIEnv* env, jclass) {
env->PushLocalFrame(256);
jobjectArray array = env->NewObjectArray(128, gMyClass, NULL);
for (int i = 0; i < 128; ++i) {
env->SetObjectArrayElement(array, i, newMyClass(i));
}
env->PopLocalFrame(NULL); // Error: should pass 'array'.
return array; // Error: array is no longer valid.
}
The fix is generally to pass the reference to PopLocalFrame(). Note in the above example that you don’t need to keep references to the individual array elements; as long as the GC knows about the array itself, it’ll take care of the elements (and any objects they point to in turn) itself.
If you do have this class of error in your code, the crash will look something like this:
JNI ERROR (app bug): accessed stale local reference 0x2d00025 (index 9 in a table of size 8)
JNI WARNING: invalid reference returned from native code
in LMyClass;.returnArray:()[Ljava/lang/Object;
Wrapping up
Yes, we asking for a bit more attention to detail in your JNI coding, which is extra work. But we think that you’ll come out ahead on the deal as we roll in better and more sophisticated memory management code.
原文链接
JNI Local Reference Changes in ICS
Android冰淇淋三明治ICS(4.0+)JNI局部引用的变化