最近网站访问异常缓慢,网站响应时间明显延迟很多,观察系统的处理器占用,一点都不高,带宽也在合理范围之内,因此分析Apache-2.4.10的错误日志
|
|
$ cat /var/log/apache2/error.log |
发现大量的出现
|
|
[Tue Feb 21 21:16:12.012511 2017] [fcgid:warn] [pid 19442:tid 140638402033408] [client 54.147.162.12:50579] mod_fcgid: can't apply process slot for /usr/bin/php5-cgi, referer: https://www.google.com/ |
如下图:
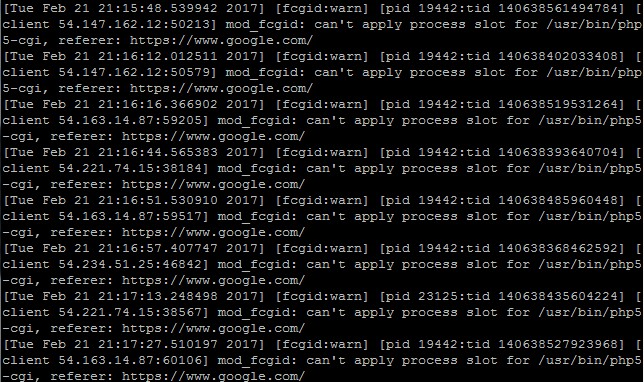
感觉很奇怪,于是看了一下php相关的进程,执行命令
执行结果如下图:
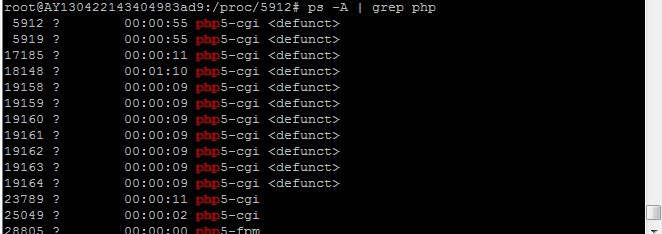
发现大量的php5-cgi进程处于defunct状态(僵尸状态),导致达到了进程数量的限制上限,无法继续提供服务。
但是上面的日志,是已经出现问题的时候的日志,既然进程不足了,自然无法提供服务了,继续向上追踪,发现大量的进程崩溃日志
|
|
[Mon Feb 20 18:07:12.857016 2017] [core:warn] [pid 15284:tid 139855916136320] AH00045: child process 15291 still did not exit, sending a SIGTERM [Mon Feb 20 18:07:12.857024 2017] [core:warn] [pid 15284:tid 139855916136320] AH00045: child process 15408 still did not exit, sending a SIGTERM [Mon Feb 20 18:07:12.857031 2017] [core:warn] [pid 15284:tid 139855916136320] AH00045: child process 17723 still did not exit, sending a SIGTERM [Mon Feb 20 18:07:14.859108 2017] [core:warn] [pid 15284:tid 139855916136320] AH00045: child process 16387 still did not exit, sending a SIGTERM [Mon Feb 20 18:07:14.859170 2017] [core:warn] [pid 15284:tid 139855916136320] AH00045: child process 15291 still did not exit, sending a SIGTERM [Mon Feb 20 18:07:14.859178 2017] [core:warn] [pid 15284:tid 139855916136320] AH00045: child process 15408 still did not exit, sending a SIGTERM [Mon Feb 20 18:07:14.859185 2017] [core:warn] [pid 15284:tid 139855916136320] AH00045: child process 17723 still did not exit, sending a SIGTERM |
感觉很奇怪,最初以为是由于调整Apache-2.4.10服务器,多次在正常运行中重启服务器,导致正在服务的php5-cgi进程变成了僵尸进程。但是重启服务器之后,过了几天后,问题依旧发生了。
于是网上搜索了一下,感觉应该更像是PHP-CGI进程本身存在内存泄漏问题,导致进程长时间执行之后,由于资源开销问题导致进程崩溃。
目前我的服务器上启用的是Apache2的Event MPM模块,查看其中的配置文件:
|
|
$ cat /etc/apache2/mods-enabled/mpm_event.conf |
可以看到里面的内容如下:
|
|
# event MPM # StartServers: initial number of server processes to start # MinSpareThreads: minimum number of worker threads which are kept spare # MaxSpareThreads: maximum number of worker threads which are kept spare # ThreadsPerChild: constant number of worker threads in each server process # MaxRequestWorkers: maximum number of worker threads # MaxConnectionsPerChild: maximum number of requests a server process serves <IfModule mpm_event_module> StartServers 2 MinSpareThreads 25 MaxSpareThreads 75 ThreadLimit 64 ThreadsPerChild 25 MaxRequestWorkers 150 MaxConnectionsPerChild 0 </IfModule> |
发现,设置MaxConnectionsPerChild参数为0,根据 Apache MPM Common Directives 里面的介绍,这个参数的作用就是一个进程处理多少个请求后就退出。而如果设置了 0 则代表,除非出现了异常,否则进程会一直存在。这样的话,一旦资源泄漏,进程就会各种异常了。因此需要设置一下这个参数,一般这个参数设置为1000-5000左右,根据实际情况自己调整一下参数。注意:这个参数的设置是会影响到网站的访问速度的,尤其是当服务器的连接次数到达限制的时候,此时大量的服务器进程都在重启,导致此时的访问要么被重置要么耗时变的非常长。因此,如果没有资源泄漏的话,可以不设置这个限制。
注意一下这个介绍的最后一句话,讲的就是这个参数可以修正资源泄漏问题,如下:
|
|
Setting MaxConnectionsPerChild to a non-zero value limits the amount of memory that process can consume by (accidental) memory leakage. |
修改参数后,需要重启服务生效。
按照上面的方法实现后,过了一个礼拜后,这个现象再次发生了。
观察了一下Apache2当前已经启用的模块
|
|
$ ls /etc/apache2/mods-enabled/ |
发现,由于是从Apache2.2升级到的Apache2.4,或许是某次的配置,导致fastcgi与fcgi两个模块同时被启用了。
是不是两个相同功能的模块同时启用导致功能冲突了呢?
先尝试禁用fastcgi(这个模块已经被fcgi替换了).
|
|
$ a2dismod fastcgi $ service apache2 restart |
目前看来,问题依旧发生了!!!
查看Apache2中的FastCGI的配置信息
|
|
$ vim /etc/apache2/mods-enabled/fcgid.conf |
可以看到如下内容
|
|
<IfModule mod_fcgid.c> AddHandler fcgid-script .fcgi .php FcgidConnectTimeout 120 DefaultMaxClassProcessCount 10 MaxRequestLen 157286400 IPCCommTimeout 300 </IfModule> |
其中的AddHandler中的.php引起了注意,因为在日志中出现问题之前一直会出现如下的错误日志:
|
|
[Tue Feb 21 01:56:12.876460 2017] [fcgid:warn] [pid 21582:tid 140134271887104] [client 114.82.132.78:2410] mod_fcgid: can't apply process slot for /usr/bin/php5-cgi, referer: http://www.mobibrw.com/plus/90sec.php [Tue Feb 21 01:56:16.727715 2017] [fcgid:warn] [pid 20546:tid 140134255101696] [client 114.82.132.78:2647] mod_fcgid: can't apply process slot for /usr/bin/php5-cgi, referer: http://www.mobibrw.com/plus/spider.php [Tue Feb 21 01:56:20.434429 2017] [fcgid:warn] [pid 21582:tid 140134263494400] [client 114.82.132.78:3049] mod_fcgid: can't apply process slot for /usr/bin/php5-cgi, referer: http://www.mobibrw.com/plus/e7xue.php [Tue Feb 21 01:56:35.130495 2017] [fcgid:warn] [pid 20546:tid 140134297065216] [client 114.82.132.78:3446] mod_fcgid: can't apply process slot for /usr/bin/php5-cgi, referer: http://www.mobibrw.com/plus/x.php [Tue Feb 21 01:56:38.668792 2017] [fcgid:warn] [pid 20546:tid 140134238316288] [client 114.82.132.78:3985] mod_fcgid: can't apply process slot for /usr/bin/php5-cgi, referer: http://www.mobibrw.com/plus/service.php [Tue Feb 21 01:56:42.247574 2017] [fcgid:warn] [pid 22275:tid 140134263494400] [client 114.82.132.78:4368] mod_fcgid: can't apply process slot for /usr/bin/php5-cgi, referer: http://www.mobibrw.com/plus/av.php |
而这个配置项是从Ubuntu 12.04中手工引入的,我们尝试去掉这个。另外,可以看到
|
|
DefaultMaxClassProcessCount 10 |
也就是FastCGI的最大进程数是被设置成了10,但是,我这边限制PHP-FPM的最大进程数为5,是不是FastCGI的进程数如果大于PHP-FPM能够提供服务的数量的时候,会导致FastCGI进程出现僵尸状态呢? 是不是这个原因导致的呢? 于是修改后的结果如下:
|
|
<IfModule mod_fcgid.c> AddHandler fcgid-script .fcgi FcgidConnectTimeout 120 DefaultMaxClassProcessCount 5 MaxRequestLen 157286400 IPCCommTimeout 300 </IfModule> |
经过这几天的观察,貌似现象不再出现了,这个应该是Apache 2.4版本引入的BUG,以前的配置的Apache 2.2版本上是没有任何问题的,究竟原因是mod_fcgid无法处理.php格式的脚本导致,还是由于mod_fcgid进程数高于php-fpm的进程数导致mod_fcgid进程长时间无法获取到可用的php-fpm连接,导致进程被饿死,这个暂时不详细追究了。
今天在修改配置的时候,由于配置错误,导致PHP-FPM服务无法正常启动,但是整个服务器竟然一直可以正常访问,那么结论就是Apache 2.4在当前的配置下,根本就没有使用PHP-FPM模式进行通信,而是使用标准的FastCGI的方式调度的。
于是网上搜索半天,结合自己的尝试,找到了根本原因:
|
|
<Directory /var/www/wordpress> #Options Indexes FollowSymLinks MultiViews Options FollowSymLinks MultiViews AllowOverride All FCGIWrapper /usr/bin/php5-cgi .php AddHandler fcgid-script .php Options ExecCGI SymLinksIfOwnerMatch Order allow,deny allow from all </Directory> |
上面的配置在Apache 2.2版本上是不影响后面启用的PHP-FPM配置的,对于PHP的请求,最终都是定向到PHP-FPM的。但是相同的配置在Apache 2.4上面,则被定向到了FastCGI上面。因此修改方式如下(至少要高于2.4.10,否则配置无效):
|
|
<Directory /var/www/wordpress> #Options Indexes FollowSymLinks MultiViews Options FollowSymLinks MultiViews AllowOverride All # Apache 2.2/2.4.9 # FCGIWrapper /usr/bin/php5-cgi .php # AddHandler fcgid-script .php # Options ExecCGI SymLinksIfOwnerMatch # Apache 2.4.10 <FilesMatch \.php$> SetHandler "proxy:unix:/var/run/php5-fpm.sock|fcgi://localhost" </FilesMatch> Order allow,deny allow from all </Directory> |
至此,应该才是从根本上解决了服务器上的问题。
开始的时候忽略了一个基础的问题,那就是php5-cgi跟php5-fpm进程本身就不应该同时存在,如果服务器使用php5-fpm,那么php5-cgi的进程就不应该被调用,这个问题没有重视,导致了整个问题分析时间冗长,反复。
本质上是服务器的配置错误导致问题。