Android Studio提供了比较方便的单元测试,但是由于Android系统的限制(Classloader是Google自己实现的,Powermock无法修改底层的bytecode),目前Powermock还没办法直接在设备上执行测试,但是我们代码中难免存在一些静态对象,需要测试的时候,只能求助于Powermock与Robolectric的组合。
具体的配置如下:
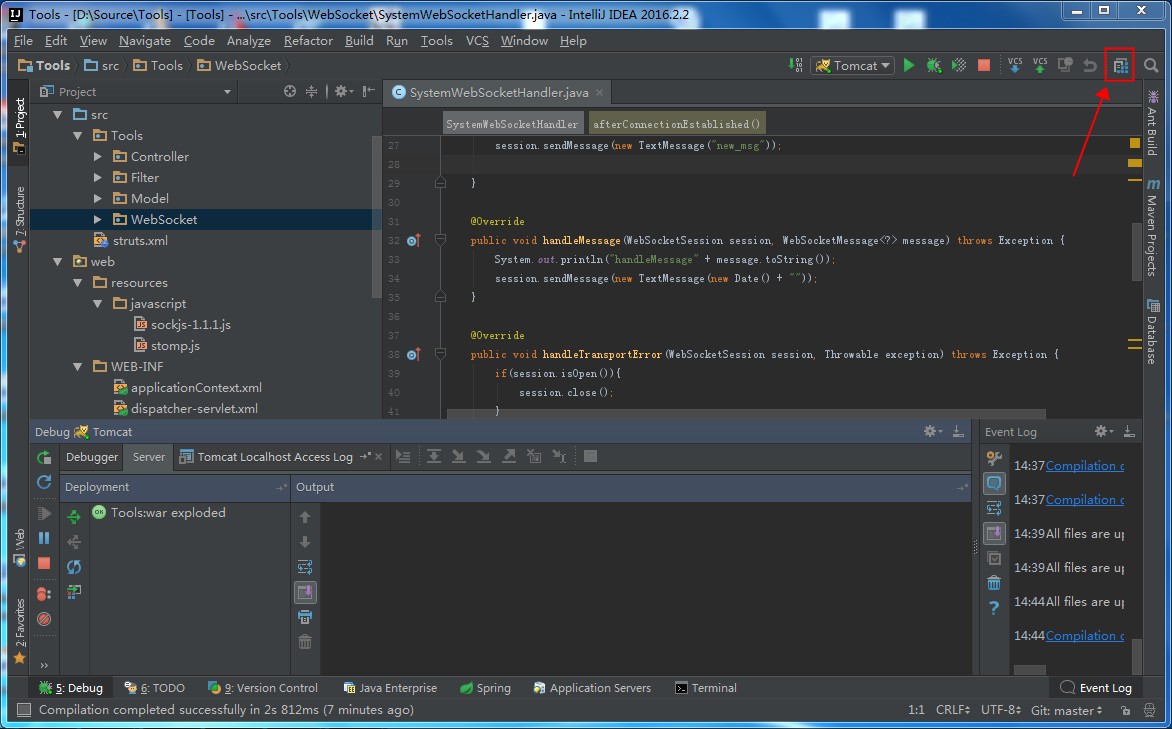
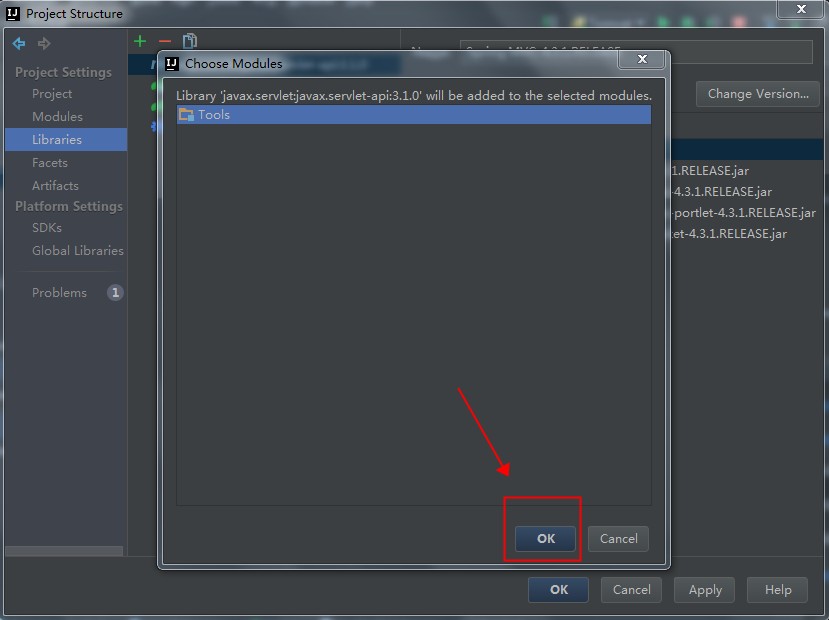
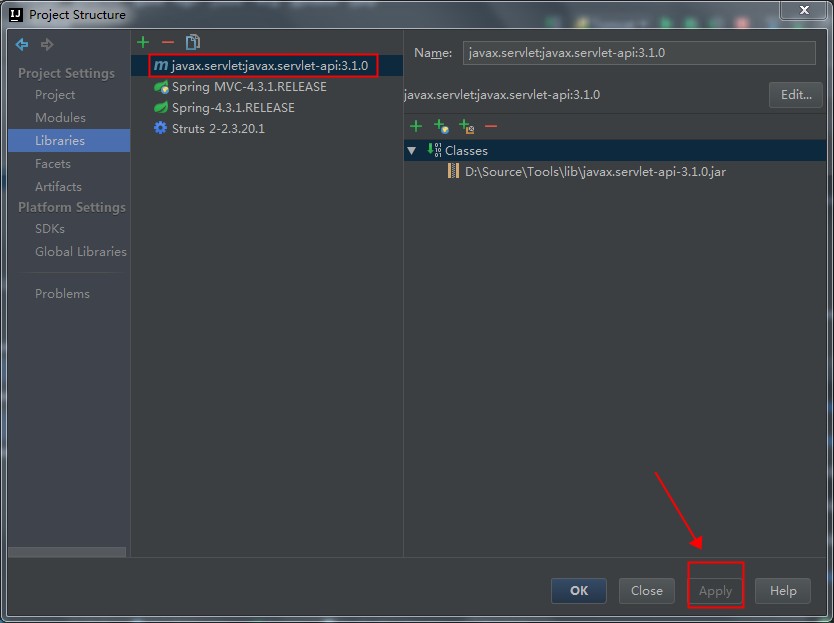
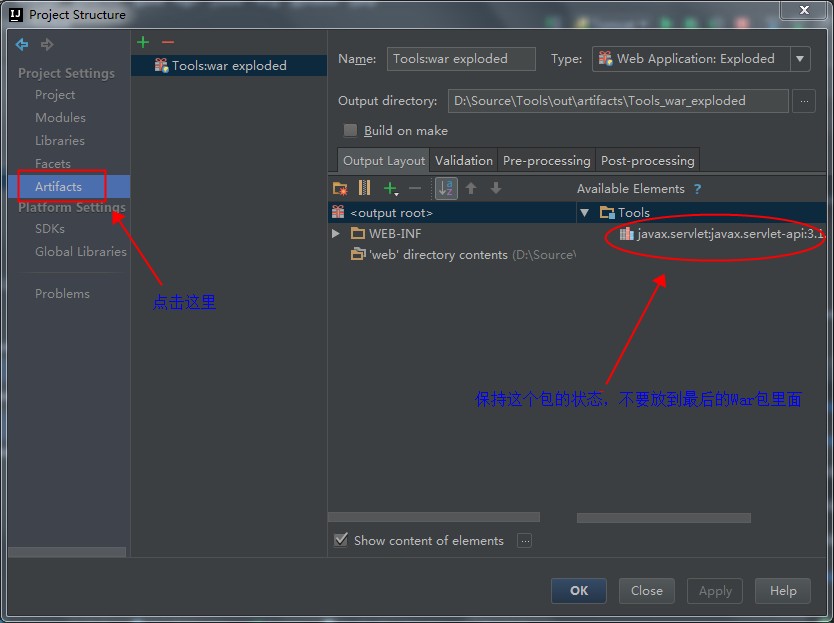
1.首先在需要测试的项目的build.gradle中声明需要使用Powermock与Robolectric。
|
1 2 3 4 5 6 7 |
testCompile 'junit:junit:4.12' testCompile 'org.powermock:powermock-api-mockito:1.6.5' testCompile 'org.powermock:powermock-module-junit4-rule:1.6.5' testCompile 'org.powermock:powermock-module-junit4:1.6.5' testCompile "org.powermock:powermock-classloading-xstream:1.6.5" /*不可使用3.1.x版本,3.1.x版本无法与PowerMock配合测试,运行时候直接报错*/ testCompile 'org.robolectric:robolectric:3.0' |
2.定义测试基类,在基类中声明一些必备的设置
AbsRobolectricPowerMockTest.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import android.os.Build; import org.junit.Rule; import org.junit.runner.RunWith; import org.powermock.core.classloader.annotations.PowerMockIgnore; import org.powermock.modules.junit4.PowerMockRunner; import org.powermock.modules.junit4.PowerMockRunnerDelegate; import org.powermock.modules.junit4.rule.PowerMockRule; import org.robolectric.RobolectricGradleTestRunner; import org.robolectric.annotation.Config; /** * Created by longsky.wq on 2016/8/22. */ @PowerMockRunnerDelegate(RobolectricGradleTestRunner.class) @RunWith(PowerMockRunner.class) @Config(constants = BuildConfig.class, sdk = Build.VERSION_CODES.JELLY_BEAN_MR1) @PowerMockIgnore({"org.mockito.*", "org.robolectric.*", "android.*","javax.crypto.","java.security.*"}) abstract public class AbsRobolectricPowerMockTest { @Rule public PowerMockRule rule = new PowerMockRule(); } |
3.定义真正的测试子类
DeckardActivityTest.java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import org.junit.Test; import org.junit.Assert; import org.mockito.Mockito; import org.powermock.api.mockito.PowerMockito; import org.powermock.core.classloader.annotations.PrepareForTest; import static junit.framework.Assert.assertTrue; @PrepareForTest(Static.class) public class DeckardActivityTest extends AbsRobolectricPowerMockTest { @Test public void testStaticMocking() { /*如果如下断言失败,说明Robolectric环境没有初始化成功,说明配置存在问题*/ Assert.assertNotNull(RuntimeEnvironment.application); PowerMockito.mockStatic(Static.class); Mockito.when(Static.staticMethod()).thenReturn("hello mock"); assertTrue(Static.staticMethod().equals("hello mock")); } } |
注意,参考链接中的内容不可完全相信,按照参考链接中的配置(Robolectric-3.1.2+PowerMock-1.6.5),一般会遇到如下问题(看上去很怪异,其实是由于不同的classloader同时加载了相同的类,导致尽管类名是相同的,但是依旧无法进行类型转换):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 |
com.thoughtworks.xstream.converters.ConversionException: Could not call org.apache.tools.ant.Project$AntRefTable.readObject() : Cannot convert type org.apache.tools.ant.Project to type org.apache.tools.ant.Project ---- Debugging information ---- class : org.apache.tools.ant.types.FileSet required-type : org.apache.tools.ant.types.FileSet converter-type : com.thoughtworks.xstream.converters.reflection.ReflectionConverter path : /org.powermock.modules.junit4.rule.PowerMockStatement$1/outer-class/fNext/this$1/outer-class/dependencyResolver/dependencyResolver/project/references/hashtable/org.apache.tools.ant.types.FileSet/project line number : 167 ------------------------------- message : Could not call org.apache.tools.ant.Project$AntRefTable.readObject() cause-exception : com.thoughtworks.xstream.converters.ConversionException cause-message : Cannot convert type org.apache.tools.ant.Project to type org.apache.tools.ant.Project class : org.apache.tools.ant.Project$AntRefTable required-type : org.apache.tools.ant.types.FileSet converter-type : com.thoughtworks.xstream.converters.reflection.SerializableConverter path : /org.powermock.modules.junit4.rule.PowerMockStatement$1/outer-class/fNext/this$1/outer-class/dependencyResolver/dependencyResolver/project/references/hashtable/org.apache.tools.ant.types.FileSet/project line number : 167 class[1] : org.apache.tools.ant.Project converter-type[1] : com.thoughtworks.xstream.converters.reflection.ReflectionConverter class[2] : org.robolectric.internal.dependency.MavenDependencyResolver class[3] : org.robolectric.internal.dependency.CachedDependencyResolver class[4] : org.robolectric.RobolectricGradleTestRunner class[5] : org.robolectric.RobolectricTestRunner$HelperTestRunner class[6] : org.robolectric.RobolectricTestRunner$HelperTestRunner$1 class[7] : org.powermock.modules.junit4.rule.PowerMockStatement class[8] : org.powermock.modules.junit4.rule.PowerMockStatement$1 version : not available ------------------------------- at com.thoughtworks.xstream.core.util.SerializationMembers.callReadObject(SerializationMembers.java:133) at com.thoughtworks.xstream.converters.reflection.SerializableConverter.doUnmarshal(SerializableConverter.java:455) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshallField(AbstractReflectionConverter.java:480) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:412) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshallField(AbstractReflectionConverter.java:480) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:412) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshallField(AbstractReflectionConverter.java:480) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:412) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshallField(AbstractReflectionConverter.java:480) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:412) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshallField(AbstractReflectionConverter.java:480) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:412) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshallField(AbstractReflectionConverter.java:480) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:412) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshallField(AbstractReflectionConverter.java:480) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:412) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshallField(AbstractReflectionConverter.java:480) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:412) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:50) at com.thoughtworks.xstream.core.TreeUnmarshaller.start(TreeUnmarshaller.java:134) at com.thoughtworks.xstream.core.AbstractTreeMarshallingStrategy.unmarshal(AbstractTreeMarshallingStrategy.java:32) at com.thoughtworks.xstream.XStream.unmarshal(XStream.java:1206) at com.thoughtworks.xstream.XStream.unmarshal(XStream.java:1190) at com.thoughtworks.xstream.XStream.fromXML(XStream.java:1061) at com.thoughtworks.xstream.XStream.fromXML(XStream.java:1052) at org.powermock.classloading.DeepCloner.clone(DeepCloner.java:54) at org.powermock.classloading.AbstractClassloaderExecutor.executeWithClassLoader(AbstractClassloaderExecutor.java:56) at org.powermock.classloading.SingleClassloaderExecutor.execute(SingleClassloaderExecutor.java:67) at org.powermock.classloading.AbstractClassloaderExecutor.execute(AbstractClassloaderExecutor.java:43) at org.powermock.modules.junit4.rule.PowerMockStatement.evaluate(PowerMockRule.java:75) at org.robolectric.RobolectricTestRunner$2.evaluate(RobolectricTestRunner.java:250) at org.robolectric.RobolectricTestRunner.runChild(RobolectricTestRunner.java:176) at org.robolectric.RobolectricTestRunner.runChild(RobolectricTestRunner.java:49) at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290) at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71) at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288) at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58) at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268) at org.robolectric.RobolectricTestRunner$1.evaluate(RobolectricTestRunner.java:142) at org.junit.runners.ParentRunner.run(ParentRunner.java:363) at org.powermock.modules.junit4.internal.impl.DelegatingPowerMockRunner$2.call(DelegatingPowerMockRunner.java:148) at org.powermock.modules.junit4.internal.impl.DelegatingPowerMockRunner$2.call(DelegatingPowerMockRunner.java:140) at org.powermock.modules.junit4.internal.impl.DelegatingPowerMockRunner.withContextClassLoader(DelegatingPowerMockRunner.java:131) at org.powermock.modules.junit4.internal.impl.DelegatingPowerMockRunner.run(DelegatingPowerMockRunner.java:140) at org.powermock.modules.junit4.common.internal.impl.JUnit4TestSuiteChunkerImpl.run(JUnit4TestSuiteChunkerImpl.java:121) at org.powermock.modules.junit4.common.internal.impl.AbstractCommonPowerMockRunner.run(AbstractCommonPowerMockRunner.java:53) at org.powermock.modules.junit4.PowerMockRunner.run(PowerMockRunner.java:59) at org.junit.runner.JUnitCore.run(JUnitCore.java:137) at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:69) at com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:234) at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:74) Caused by: com.thoughtworks.xstream.converters.ConversionException: Cannot convert type org.apache.tools.ant.Project to type org.apache.tools.ant.Project ---- Debugging information ---- class : org.apache.tools.ant.types.FileSet required-type : org.apache.tools.ant.types.FileSet converter-type : com.thoughtworks.xstream.converters.reflection.ReflectionConverter path : /org.powermock.modules.junit4.rule.PowerMockStatement$1/outer-class/fNext/this$1/outer-class/dependencyResolver/dependencyResolver/project/references/hashtable/org.apache.tools.ant.types.FileSet/project line number : 167 ------------------------------- at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.doUnmarshal(AbstractReflectionConverter.java:439) at com.thoughtworks.xstream.converters.reflection.AbstractReflectionConverter.unmarshal(AbstractReflectionConverter.java:263) at com.thoughtworks.xstream.core.TreeUnmarshaller.convert(TreeUnmarshaller.java:72) at com.thoughtworks.xstream.core.AbstractReferenceUnmarshaller.convert(AbstractReferenceUnmarshaller.java:65) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:66) at com.thoughtworks.xstream.core.TreeUnmarshaller.convertAnother(TreeUnmarshaller.java:50) at com.thoughtworks.xstream.converters.reflection.SerializableConverter$2.readFromStream(SerializableConverter.java:337) at com.thoughtworks.xstream.core.util.CustomObjectInputStream.readObjectOverride(CustomObjectInputStream.java:120) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:364) at java.util.Hashtable.readObject(Hashtable.java:996) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:606) at com.thoughtworks.xstream.core.util.SerializationMembers.callReadObject(SerializationMembers.java:125) ... 86 more |