I'm trying to create an application that contains a web browser within it, but when I add the web browser my menu bar visually disappears but functionally remains in place. The following are two images, one showing the "self.centralWidget(self.web_widget)" commented out, and the other allows that line to run. If you run the example code, you will also see that while visually the entire web page appears as if the menu bar wasn't present, you have to click slightly below each entry field and button in order to activate it, behaving as if the menu bar was in fact present.
macOS Catalina(10.15.4)下PyQt5图标Icon无法显示的问题
在macOS下,刚学习PyQt5遇到图标无法显示问题. 先上代码,看下代码就明白了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import sys from PyQt5.QtWidgets import QApplication, QWidget from PyQt5.QtGui import QIcon, QPixmap from PyQt5.QtCore import QFile # 面向对象编程 class main_widget(QWidget): # 继承自 QWidget类 def __init__(self): super().__init__() self.initUI() # 创建窗口 def initUI(self): # 在此处添加 窗口控件 self.setGeometry(300, 200, 600, 500) # 屏幕上坐标(x, y), 和 窗口大小(宽,高) self.setWindowTitle("第一个qt5窗口") # self.setWindowIcon(QIcon("logo/m4.png")) # 设置窗口图标 self.show() if __name__ == "__main__": app = QApplication(sys.argv) path = 'logo/m4.png' print(QFile.exists(path)) app.setWindowIcon(QIcon(path)) # MAC 下 程序图标是显示在程序坞中的, 切记; window = main_widget() sys.exit(app.exec()) # 退出主循环 |
setWindowIcon是QApplication的方法,而不是QWidget的,所以使用app.setWindowIcon设置是对的。
注意:在macOS下,图标是显示在程序坞中的!!!
参考链接
Python+WebKit+HTML开发桌面应用程序
前言
几天前写了一个备份的小工具,用Python写个脚本,也就花个一天的时间搞定,给客户用了一下,对功能很满意,但对界面不满足,想要一个图形界面来管理;
一个备份脚本,有必要整成这样子吗?没办法,谁让是上帝的要求呢,就研究一下;先后找了python的tkinter、pyqt,尝试着画一些界面,虽然功能可以实现,但界面很难看;恰好,在查看pyqt的API文档的时候 ,发现了QWebView组件,据介绍可以实现一个浏览器,并且浏览器中的JS可以与Python代码进行交互。忽然眼前一亮,我不正是我想要的吗!
抽几天时间把工具写完了,目前运行良好;想写篇博客做个记录,也想给需要进行此类开发的朋友做个示例,就把这个工具最核心的内容做了一个DEMO。现在,就把这个小DEMO的开发过程做个说明;
功能简介
这个小DEMO用于显示计算机上的一些信息,显示内容不是主要的,主要为了体现如何用python+HTML开发桌面应用程序。
|
1 2 3 |
1.使用HTML开发一个界面; 2.在页面上显示主机信息; 3.实现功能时,体现JS调用Python和Python调用JS; |
最终实现的主界面如下:
准备材料
开发工具:Visual Studio Code
开发语言:python 2.7/python 3.7
界面工具包:PyQT4/PyQT5
目录结构
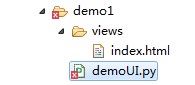
说明:
demoUI.py : python主体程序 ,主要实现窗口创建,加载index.html页面,python与JS的交互;
views/index.html : 主要进行数据展示,及与python交互的js程序
demoUI.py开发
引入的包
|
1 2 3 4 5 6 7 8 9 10 |
from PyQt4 import QtCore from PyQt4 import QtGui from PyQt4 import QtWebKit from PyQt4 import QtNetwork #处理中文问题 import sys,json from PyQt4.Qt import QObject reload(sys) sys.setdefaultencoding('utf8') |
前四行代码,主要是引入Qt相关的包,这里使用的PyQt4;
后三行代码,主要是为了处理中文问题,可以忽略,但遇到中文乱码的时候,想起来这句话,把它加上就行了
DemoWin类
|
1 2 3 4 5 6 7 8 9 10 |
class DemoWin(QtWebKit.QWebView): def __init__(self): QtWebKit.QWebView.__init__(self) self.resize(800, 600) self.setUrl(QtCore.QUrl('views/index.html')) self.show() mainFrame = self.page().mainFrame() winobj = WinObj(mainFrame) mainFrame.javaScriptWindowObjectCleared.connect(lambda: mainFrame.addToJavaScriptWindowObject(QtCore.QString('WinObj'), winobj)) |
DemoWin是整个应用的核心类,主要实现窗体创建,关联与JS交互的槽函数等;
|
1 |
class DemoWin(QtWebKit.QWebView): |
像标题所说,我们将使用WebKit作为页面展示,所以这里的主页面是以QtWebKit.QWebView作为基类
|
1 2 3 4 |
QtWebKit.QWebView.init(self) self.resize(800, 600) self.setUrl(QtCore.QUrl(‘views/index.html’)) self.show() |
设置窗口大小为800*600,并且加载index.html进行显示
|
1 |
mainFrame = self.page().mainFrame() |
获取网页主框架,按照QT官方文档解释:QWebFrame代表一个网页框架,每一个QWebFrame至少包含一个主框架,使用QWebFrame.mainFrame()获取。
这是进行后续各类操作的基础,类似于JS中只有获取到网页的dom对象,才可以对其中的元素操作一样;
|
1 2 |
winobj = WinObj(mainFrame) mainFrame.javaScriptWindowObjectCleared.connect(lambda: mainFrame.addToJavaScriptWindowObject(QtCore.QString(‘WinObj’), winobj)) ##js调用python |
这段代码是关键中的关键!
WinObj类:是封装后用于js调用的槽函数类,后续再详细介绍
addToJavaScriptWindowObject类:第一个参数是对象在javascript里的名字, 可以自由命名, 第二个参数是对应的QObject实例指针。 这样在javascript里就可以直接访问WinObj对象拉, 是不是看上去超级简单?但是这个函数的调用时机是有讲究的,按照官方文档的推荐,是需要在javaScriptWindowObjectCleared信号的槽里调用,才有了以上的代码;里面用了lambda表达式,纯粹是为了减少一个槽函数的定义,你如果觉得不好看或不喜欢,完全可以定义一个槽函数;
WinObj类
下面来重点介绍WinObj类,类型定义如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
class WinObj(QtCore.QObject): def __init__(self,mainFrame): super(WinObj,self).__init__() self.mainFrame = mainFrame @QtCore.pyqtSlot(result="QString") def getInfo(self): import socket,platform hostname = socket.gethostname() try: ip = socket.gethostbyname(hostname) except: ip = '' list_info = platform.uname() sys_name = list_info[0] + list_info[2] cpu_name = list_info[5] dic_info = {"hostname":hostname,"ip":ip,"sys_name":sys_name, \ "cpu_name":cpu_name} #调用js函数,实现回调 self.mainFrame.evaluateJavaScript('%s(%s)' % ('onGetInfo',json.dumps(dic_info))) return json.dumps(dic_info) |
该类封装了JS可直接调用的方法,有一些区别于普通类的地方要注意;
|
1 |
class WinObj(QtCore.QObject): |
该类必须继承自QObject,而不能是object。
|
1 2 3 |
def __init__(self,mainFrame): super(WinObj,self).__init__() self.mainFrame = mainFrame |
构造函数将mainFrame传进来,主要用于调用js函数(后面将有示例介绍)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
@QtCore.pyqtSlot(result="QString") def getInfo(self): import socket,platform hostname = socket.gethostname() ip = socket.gethostbyname(hostname) list_info = platform.uname() sys_name = list_info[0] + list_info[2] cpu_name = list_info[5] dic_info = {"hostname":hostname,"ip":ip,"sys_name":sys_name, \ "cpu_name":cpu_name} #调用js函数,实现回调 self.mainFrame.evaluateJavaScript('%s(%s)' % ('onGetInfo',json.dumps(dic_info))) return json.dumps(dic_info) |
getInfo()实现了一个供JS调用的方法,有几下几点要注意:
(1)@QtCore.pyqtSlot(result=”QString”) 用于将python方法转换为供js用的函数,括号里写明数据类型及返回类型;如果没有声明result,则不能返回数据;
(2)self.mainFrame.evaluateJavaScript(‘%s(%s)’ % (‘onGetInfo’,json.dumps(dic_info)))
调用页面中用JS声明的onGetInfo函数(这里仅作一个示例,将查询到的数据进行回调返回)
demoUI.py完整代码下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
#coding=utf-8 ''' Created on 2017年11月3日 @author: Administrator ''' from PyQt4 import QtCore from PyQt4 import QtGui from PyQt4 import QtWebKit from PyQt4 import QtNetwork #处理中文问题 import sys,json from PyQt4.Qt import QObject reload(sys) sys.setdefaultencoding('utf8') class DemoWin(QtWebKit.QWebView): def __init__(self): QtWebKit.QWebView.__init__(self) self.resize(800, 600) self.setUrl(QtCore.QUrl('views/index.html')) self.show() mainFrame = self.page().mainFrame() winobj = WinObj(mainFrame) mainFrame.javaScriptWindowObjectCleared.connect(lambda: mainFrame.addToJavaScriptWindowObject(QtCore.QString('WinObj'), winobj)) ##js调用python class WinObj(QtCore.QObject): def __init__(self,mainFrame): super(WinObj,self).__init__() self.mainFrame = mainFrame @QtCore.pyqtSlot(result="QString") def getInfo(self): import socket,platform hostname = socket.gethostname() try: ip = socket.gethostbyname(hostname) except: ip = '' list_info = platform.uname() sys_name = list_info[0] + list_info[2] cpu_name = list_info[5] dic_info = {"hostname":hostname,"ip":ip,"sys_name":sys_name, \ "cpu_name":cpu_name} #调用js函数,实现回调 self.mainFrame.evaluateJavaScript('%s(%s)' % ('onGetInfo',json.dumps(dic_info))) return json.dumps(dic_info) if __name__ == '__main__': app = QtGui.QApplication(sys.argv) demoWin = DemoWin() sys.exit(app.exec_()) |
index.html
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
<!DOCTYPE script PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <script type="text/javascript" src='https://www.mobibrw.com/wp-content/uploads/2020/05/vue.min_.1.0.11.js'></script> </head> <body> <div id='app'> <input type='button' onclick='getInfo()' value="获取机器信息"> <H3 >主机名:{{config.hostname}} </H3> <H3 >IP:{{config.ip}} </H3> <H3 >操作系统:{{config.sys_name}} </H3> <H3 >CPU:{{config.cpu_name}} </H3> <H3>以下为python回调信息:</H3> <label id='info'></label> </div> </body> </html> <script type="text/javascript"> var vm = new Vue({ el: '#app', data:{ config:{} }, created:function(){ this.config = JSON.parse(window.WinObj.getInfo()) } }); function getInfo() { info = JSON.parse(window.WinObj.getInfo()) alert(info) } //python回调的js函数 function onGetInfo(info) { document.getElementById('info').innerText=JSON.stringify(info) } </script> |
Python 3.7/PyQT5下需要安装 pyQt5
|
1 2 3 4 5 6 7 8 9 |
$ python3 -m pip install --upgrade pip $ pip3 install SIP $ pip3 install pyQt5 $ pip3 install --upgrade PyQt5 $ pip3 install PyQtWebEngine |
Python 3.7/PyQT5下的代码(注意,Python 2.7/PyQT4是的交互是同步调用的,但是Python 3.7/PyQT5通过QtWebChannel交互是异步的)如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 |
#coding=utf-8 from PyQt5 import QtCore from PyQt5 import QtGui from PyQt5 import QtWidgets from PyQt5 import QtWebEngineWidgets from PyQt5 import QtNetwork from PyQt5 import QtWebChannel #处理中文问题 import sys,json from PyQt5.Qt import QObject #reload(sys) #sys.setdefaultencoding('utf8') # 调试窗口配置 # 如果不想自己创建调试窗口,可以使用Chrome连接这个地址进行调试 import os DEBUG_PORT = '5588' DEBUG_URL = 'http://127.0.0.1:%s' % DEBUG_PORT os.environ['QTWEBENGINE_REMOTE_DEBUGGING'] = DEBUG_PORT def qt_message_handler(mode, context, message): if mode == QtCore.QtInfoMsg: mode = 'INFO' elif mode == QtCore.QtWarningMsg: mode = 'WARNING' elif mode == QtCore.QtCriticalMsg: mode = 'CRITICAL' elif mode == QtCore.QtFatalMsg: mode = 'FATAL' else: mode = 'DEBUG' print('qt_message_handler: line: %d, func: %s(), file: %s' % ( context.line, context.function, context.file)) print(' %s: %s\n' % (mode, message)) QtCore.qInstallMessageHandler(qt_message_handler) class DemoWin(QtWebEngineWidgets.QWebEngineView): def __init__(self): QtWebEngineWidgets.QWebEngineView.__init__(self) self.setWindowTitle('Web页面中的JavaScript与 QWebEngineView交互例子') self.resize(800, 600) self.settings().setAttribute(QtWebEngineWidgets.QWebEngineSettings.PluginsEnabled, True) self.settings().setAttribute(QtWebEngineWidgets.QWebEngineSettings.JavascriptEnabled, True) url = QtCore.QUrl('file:///' + QtCore.QFileInfo('views/index.html').absoluteFilePath()) #url = QtCore.QUrl("https://www.baidu.com") self.setUrl(url) self.show() self.winobj = WinObj(self.page()) self.channel = QtWebChannel.QWebChannel() self.channel.registerObject("con", self.winobj) self.page().setWebChannel(self.channel) #网页调试窗口 self.inspector = QtWebEngineWidgets.QWebEngineView() self.inspector.setWindowTitle('Web Inspector') self.inspector.load(QtCore.QUrl(DEBUG_URL)) self.loadFinished.connect(self.handleHtmlLoaded) def handleHtmlLoaded(self, ok): if ok: self.page().setDevToolsPage(self.inspector.page()) self.inspector.show() class WinObj(QtCore.QObject): def __init__(self, page): super(WinObj,self).__init__() self.page = page @QtCore.pyqtSlot(result="QString") def getInfo(self): import socket,platform hostname = socket.gethostname() try: ip = socket.gethostbyname(hostname) except: ip = '' list_info = platform.uname() sys_name = list_info[0] + list_info[2] cpu_name = list_info[5] dic_info = {"hostname":hostname,"ip":ip,"sys_name":sys_name, \ "cpu_name":cpu_name} #调用js函数,实现回调 self.page.runJavaScript('%s(%s)' % ('onGetInfo',json.dumps(dic_info))) js = json.dumps(dic_info) return js if __name__ == '__main__': app = QtWidgets.QApplication(sys.argv) demoWin = DemoWin() sys.exit(app.exec()) |
index.html
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
<!DOCTYPE script PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <script type="text/javascript" src="qwebchannel.js"></script> <script type="text/javascript" src='https://www.mobibrw.com/wp-content/uploads/2020/05/vue.min_.1.0.11.js'></script> </head> <body> <div id='app'> <input type='button' onclick='getInfo()' value="获取机器信息"> <H3 >主机名:{{config.hostname}} </H3> <H3 >IP:{{config.ip}} </H3> <H3 >操作系统:{{config.sys_name}} </H3> <H3 >CPU:{{config.cpu_name}} </H3> <H3>以下为python回调信息:</H3> <label id='info'></label> </div> </body> </html> <script type="text/javascript"> new QWebChannel( qt.webChannelTransport, function(channel) { window.con = channel.objects.con; window.vm = new Vue({ el: '#app', data: { config:{} }, created:function() { window.con.getInfo(function(info) { window.vm.config = JSON.parse(info); }); } }); }); function getInfo() { window.con.getInfo(); } //python回调的js函数 function onGetInfo(info) { document.getElementById('info').innerText=JSON.stringify(info) } </script> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 |
/**************************************************************************** ** ** Copyright (C) 2016 The Qt Company Ltd. ** Copyright (C) 2014 Klarälvdalens Datakonsult AB, a KDAB Group company, info@kdab.com, author Milian Wolff <milian.wolff@kdab.com> ** Contact: https://www.qt.io/licensing/ ** ** This file is part of the QtWebChannel module of the Qt Toolkit. ** ** $QT_BEGIN_LICENSE:BSD$ ** Commercial License Usage ** Licensees holding valid commercial Qt licenses may use this file in ** accordance with the commercial license agreement provided with the ** Software or, alternatively, in accordance with the terms contained in ** a written agreement between you and The Qt Company. For licensing terms ** and conditions see https://www.qt.io/terms-conditions. For further ** information use the contact form at https://www.qt.io/contact-us. ** ** BSD License Usage ** Alternatively, you may use this file under the terms of the BSD license ** as follows: ** ** "Redistribution and use in source and binary forms, with or without ** modification, are permitted provided that the following conditions are ** met: ** * Redistributions of source code must retain the above copyright ** notice, this list of conditions and the following disclaimer. ** * Redistributions in binary form must reproduce the above copyright ** notice, this list of conditions and the following disclaimer in ** the documentation and/or other materials provided with the ** distribution. ** * Neither the name of The Qt Company Ltd nor the names of its ** contributors may be used to endorse or promote products derived ** from this software without specific prior written permission. ** ** ** THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS ** "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT ** LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR ** A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT ** OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, ** SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT ** LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, ** DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY ** THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT ** (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE ** OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE." ** ** $QT_END_LICENSE$ ** ****************************************************************************/ "use strict"; var QWebChannelMessageTypes = { signal: 1, propertyUpdate: 2, init: 3, idle: 4, debug: 5, invokeMethod: 6, connectToSignal: 7, disconnectFromSignal: 8, setProperty: 9, response: 10, }; var QWebChannel = function(transport, initCallback) { if (typeof transport !== "object" || typeof transport.send !== "function") { console.error("The QWebChannel expects a transport object with a send function and onmessage callback property." + " Given is: transport: " + typeof(transport) + ", transport.send: " + typeof(transport.send)); return; } var channel = this; this.transport = transport; this.send = function(data) { if (typeof(data) !== "string") { data = JSON.stringify(data); } channel.transport.send(data); } this.transport.onmessage = function(message) { var data = message.data; if (typeof data === "string") { data = JSON.parse(data); } switch (data.type) { case QWebChannelMessageTypes.signal: channel.handleSignal(data); break; case QWebChannelMessageTypes.response: channel.handleResponse(data); break; case QWebChannelMessageTypes.propertyUpdate: channel.handlePropertyUpdate(data); break; default: console.error("invalid message received:", message.data); break; } } this.execCallbacks = {}; this.execId = 0; this.exec = function(data, callback) { if (!callback) { // if no callback is given, send directly channel.send(data); return; } if (channel.execId === Number.MAX_VALUE) { // wrap channel.execId = Number.MIN_VALUE; } if (data.hasOwnProperty("id")) { console.error("Cannot exec message with property id: " + JSON.stringify(data)); return; } data.id = channel.execId++; channel.execCallbacks[data.id] = callback; channel.send(data); }; this.objects = {}; this.handleSignal = function(message) { var object = channel.objects[message.object]; if (object) { object.signalEmitted(message.signal, message.args); } else { console.warn("Unhandled signal: " + message.object + "::" + message.signal); } } this.handleResponse = function(message) { if (!message.hasOwnProperty("id")) { console.error("Invalid response message received: ", JSON.stringify(message)); return; } channel.execCallbacks[message.id](message.data); delete channel.execCallbacks[message.id]; } this.handlePropertyUpdate = function(message) { for (var i in message.data) { var data = message.data[i]; var object = channel.objects[data.object]; if (object) { object.propertyUpdate(data.signals, data.properties); } else { console.warn("Unhandled property update: " + data.object + "::" + data.signal); } } channel.exec({type: QWebChannelMessageTypes.idle}); } this.debug = function(message) { channel.send({type: QWebChannelMessageTypes.debug, data: message}); }; channel.exec({type: QWebChannelMessageTypes.init}, function(data) { for (var objectName in data) { var object = new QObject(objectName, data[objectName], channel); } // now unwrap properties, which might reference other registered objects for (var objectName in channel.objects) { channel.objects[objectName].unwrapProperties(); } if (initCallback) { initCallback(channel); } channel.exec({type: QWebChannelMessageTypes.idle}); }); }; function QObject(name, data, webChannel) { this.__id__ = name; webChannel.objects[name] = this; // List of callbacks that get invoked upon signal emission this.__objectSignals__ = {}; // Cache of all properties, updated when a notify signal is emitted this.__propertyCache__ = {}; var object = this; // ---------------------------------------------------------------------- this.unwrapQObject = function(response) { if (response instanceof Array) { // support list of objects var ret = new Array(response.length); for (var i = 0; i < response.length; ++i) { ret[i] = object.unwrapQObject(response[i]); } return ret; } if (!response || !response["__QObject*__"] || response.id === undefined) { return response; } var objectId = response.id; if (webChannel.objects[objectId]) return webChannel.objects[objectId]; if (!response.data) { console.error("Cannot unwrap unknown QObject " + objectId + " without data."); return; } var qObject = new QObject( objectId, response.data, webChannel ); qObject.destroyed.connect(function() { if (webChannel.objects[objectId] === qObject) { delete webChannel.objects[objectId]; // reset the now deleted QObject to an empty {} object // just assigning {} though would not have the desired effect, but the // below also ensures all external references will see the empty map // NOTE: this detour is necessary to workaround QTBUG-40021 var propertyNames = []; for (var propertyName in qObject) { propertyNames.push(propertyName); } for (var idx in propertyNames) { delete qObject[propertyNames[idx]]; } } }); // here we are already initialized, and thus must directly unwrap the properties qObject.unwrapProperties(); return qObject; } this.unwrapProperties = function() { for (var propertyIdx in object.__propertyCache__) { object.__propertyCache__[propertyIdx] = object.unwrapQObject(object.__propertyCache__[propertyIdx]); } } function addSignal(signalData, isPropertyNotifySignal) { var signalName = signalData[0]; var signalIndex = signalData[1]; object[signalName] = { connect: function(callback) { if (typeof(callback) !== "function") { console.error("Bad callback given to connect to signal " + signalName); return; } object.__objectSignals__[signalIndex] = object.__objectSignals__[signalIndex] || []; object.__objectSignals__[signalIndex].push(callback); if (!isPropertyNotifySignal && signalName !== "destroyed") { // only required for "pure" signals, handled separately for properties in propertyUpdate // also note that we always get notified about the destroyed signal webChannel.exec({ type: QWebChannelMessageTypes.connectToSignal, object: object.__id__, signal: signalIndex }); } }, disconnect: function(callback) { if (typeof(callback) !== "function") { console.error("Bad callback given to disconnect from signal " + signalName); return; } object.__objectSignals__[signalIndex] = object.__objectSignals__[signalIndex] || []; var idx = object.__objectSignals__[signalIndex].indexOf(callback); if (idx === -1) { console.error("Cannot find connection of signal " + signalName + " to " + callback.name); return; } object.__objectSignals__[signalIndex].splice(idx, 1); if (!isPropertyNotifySignal && object.__objectSignals__[signalIndex].length === 0) { // only required for "pure" signals, handled separately for properties in propertyUpdate webChannel.exec({ type: QWebChannelMessageTypes.disconnectFromSignal, object: object.__id__, signal: signalIndex }); } } }; } /** * Invokes all callbacks for the given signalname. Also works for property notify callbacks. */ function invokeSignalCallbacks(signalName, signalArgs) { var connections = object.__objectSignals__[signalName]; if (connections) { connections.forEach(function(callback) { callback.apply(callback, signalArgs); }); } } this.propertyUpdate = function(signals, propertyMap) { // update property cache for (var propertyIndex in propertyMap) { var propertyValue = propertyMap[propertyIndex]; object.__propertyCache__[propertyIndex] = propertyValue; } for (var signalName in signals) { // Invoke all callbacks, as signalEmitted() does not. This ensures the // property cache is updated before the callbacks are invoked. invokeSignalCallbacks(signalName, signals[signalName]); } } this.signalEmitted = function(signalName, signalArgs) { invokeSignalCallbacks(signalName, signalArgs); } function addMethod(methodData) { var methodName = methodData[0]; var methodIdx = methodData[1]; object[methodName] = function() { var args = []; var callback; for (var i = 0; i < arguments.length; ++i) { if (typeof arguments[i] === "function") callback = arguments[i]; else args.push(arguments[i]); } webChannel.exec({ "type": QWebChannelMessageTypes.invokeMethod, "object": object.__id__, "method": methodIdx, "args": args }, function(response) { if (response !== undefined) { var result = object.unwrapQObject(response); if (callback) { (callback)(result); } } }); }; } function bindGetterSetter(propertyInfo) { var propertyIndex = propertyInfo[0]; var propertyName = propertyInfo[1]; var notifySignalData = propertyInfo[2]; // initialize property cache with current value // NOTE: if this is an object, it is not directly unwrapped as it might // reference other QObject that we do not know yet object.__propertyCache__[propertyIndex] = propertyInfo[3]; if (notifySignalData) { if (notifySignalData[0] === 1) { // signal name is optimized away, reconstruct the actual name notifySignalData[0] = propertyName + "Changed"; } addSignal(notifySignalData, true); } Object.defineProperty(object, propertyName, { configurable: true, get: function () { var propertyValue = object.__propertyCache__[propertyIndex]; if (propertyValue === undefined) { // This shouldn't happen console.warn("Undefined value in property cache for property \"" + propertyName + "\" in object " + object.__id__); } return propertyValue; }, set: function(value) { if (value === undefined) { console.warn("Property setter for " + propertyName + " called with undefined value!"); return; } object.__propertyCache__[propertyIndex] = value; webChannel.exec({ "type": QWebChannelMessageTypes.setProperty, "object": object.__id__, "property": propertyIndex, "value": value }); } }); } // ---------------------------------------------------------------------- data.methods.forEach(addMethod); data.properties.forEach(bindGetterSetter); data.signals.forEach(function(signal) { addSignal(signal, false); }); for (var name in data.enums) { object[name] = data.enums[name]; } } //required for use with nodejs if (typeof module === 'object') { module.exports = { QWebChannel: QWebChannel }; } |
参考链接
- Python+WebKit+HTML开发桌面应用程序
- pyqt5加载网页的简单使用
- Porting from Qt WebKit to Qt WebEngine
- PyQt5 QWebChannel实现python与Javascript双向通信
- Qt的QWebChannel和JS、HTML通信/交互驱动百度地图
- qwebchannel.js Example File
- PyQt5高级界面控件之QWebEngineView(十三)
- QWebEngineView加载本地html三种方法
- Redirect qDebug output to file with PyQt5
- 基于 QWebChannel 的前端通信方案
- qwebengineview与js相互调用(js调用c++部分)
- PyQt - JavaScript 交互
- Qt WebChannel Examples
- What is the alternative to QWebInspector in Qt WebEngine?
PyQt5出现ImportError cannot import name 'QtWebEngineWidgets' from 'PyQt5' 问题解决
今天想在macOS Catalina(10.15.4)系统上,测试一下Python下的QT界面操作,结果在执行
|
1 |
from PyQt5 import QtWebEngineWidgets |
的时候,报告如下错误:
|
1 2 3 4 |
Exception has occurred: ImportError cannot import name 'QtWebEngineWidgets' from 'PyQt5' (/usr/local/lib/python3.7/site-packages/PyQt5/__init__.py) File "demoUI.py", line 10, in <module> from PyQt5 import QtWebEngineWidgets |
也有可能报告:
|
1 |
No module named PyQt5.QtWebEngineWidgets |
查了好久才在Stack Overflow上找到一个回答,说是这个模块被PyQt5移除了,需要单独安装。
安装命令为:
|
1 |
$ pip install PyQtWebEngine |
参考链接
Python-PyQt5-PyQtWebEngine采坑记录-- No module named PyQt5.QtWebEngineWidgets
PyQt5出现No module named 'PyQt5.sip'问题解决
今天想在macOS Catalina(10.15.4)系统上,测试一下Python下的QT界面操作,结果在执行
|
1 |
from PyQt5 import QtCore |
的时候报告错误:
|
1 |
No module named 'PyQt5.sip' |
解决方法如下:
|
1 2 3 4 5 6 7 8 9 |
$ python3 -m pip install --upgrade pip $ pip3 install SIP $ pip3 install pyQt5 $ pip3 install --upgrade PyQt5 $ pip3 install PyQtWebEngine |
参考链接
No module named 'pip._internal.cli.main'
今天,在macOS Catalina (10.15.4)系统上执行升级pip的命令
|
1 |
$ pip3 install --upgrade pip |
之后,执行更新命令,报告错误。如下:
|
1 2 3 4 5 |
$ pip3 install --upgrade PyQt5 Traceback (most recent call last): File "/usr/local/bin/pip3", line 5, in <module> from pip._internal.cli.main import main ModuleNotFoundError: No module named 'pip._internal.cli.main' |
解决方法为重新升级安装一次 pip,如下:
|
1 |
$ python3 -m pip install --upgrade pip |
参考链接
pip批量更新过期的python库
今天看了下系统环境,不少python库都有了更新,再用旧版本库可能已经不适合了,就想把所有的库都更新到最新版本。
查看系统里过期的python库,可以用pip命令
|
1 |
$ pip list #列出所有安装的库 |
|
1 |
$ pip list --outdated #列出所有过期的库 |
对于列出的过期库,pip也提供了更新的命令
|
1 |
$ pip install --upgrade 库名 |
但此命令不支持全局全部库升级。
在stackoverflow上有人提供了批量更新的办法,一个循环就搞定(注意--upgrade后面的空格)
|
1 2 3 4 5 |
import pip from subprocess import call for dist in pip.get_installed_distributions(): call("pip install --upgrade " + dist.project_name, shell=True) |
另外的也有人提到用 pip-review ,不想安装就没用
|
1 2 3 |
$ pip install pip-review $ pip-review --local --interactive --auto |
参考链接
openpyxl - A Python library to read/write Excel 2010 xlsx/xlsm files
|
1 |
$ pip install openpyxl |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from openpyxl import Workbook wb = Workbook() # grab the active worksheet ws = wb.active # Data can be assigned directly to cells ws['A1'] = 42 # Rows can also be appended ws.append([1, 2, 3]) # Python types will automatically be converted import datetime ws['A2'] = datetime.datetime.now() # Save the file wb.save("sample.xlsx") |
openpyxl特点
openpyxl(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易 注意:如果文字编码是“gb2312” 读取后就会显示乱码,请先转成Unicode
继续阅读openpyxl - A Python library to read/write Excel 2010 xlsx/xlsm files
华为手机配置显示返回键
使用华为Honor V8习惯了Android屏幕最下方的三个操作按键(返回/Home/列表),三个按键所在的位置被称之为"导航栏"。
最近换了华为Honor 30,想要点返回键时,却发现手机屏幕上没有返回键。手势操作非常不方便,经常误操作。而且有些界面适配的很不好,界面上没有设置回退功能。当缺少系统层面的返回按键的时候,只能强制退出应用。
其实这个返回键是在导航键里,需要设置才会显示。下面几个步骤就教你如何设置返回键:
Gradle: 一个诡异的问题(ERROR: Failed to parse XML AndroidManifest.xml ParseError at [row,col]:[5,5] Message: expected start or end tag)
今天同事说他下了一个老版本的Android Studio项目死活编不过,我心想不就是一个项目么,编不过要么就是代码有问题,要么就是依赖库不完整这能有什么问题,于是自己在自己电脑试了下,结果自己也中招了: