HTTP从上世纪90年代诞生起,就被约定为跑在TCP协议之上的应用层协议。而后虽然HTTP协议版本从0.9到2.0,上层协议不断优化,在享受TCP带来的有序可靠的数据服务同时,却也始终绕不开TCP协议的一些弊端。此时一种基于UDP的“快”协议,不但能可靠的向上层提供数据,还能更快的把这些数据交付上去,其更革命性的给出了提升互联网交互速度的新思路。
使用word2vec训练中文维基百科
word2vec是Google于2013年开源推出的一个用于获取词向量的工具包,关于它的介绍,可以先看词向量工具word2vec的学习。
获取和处理中文语料
维基百科的中文语料库质量高、领域广泛而且开放,非常适合作为语料用来训练。相关链接:
- https://dumps.wikimedia.org/
- https://dumps.wikimedia.org/zhwiki/
- https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
有了语料后我们需要将其提取出来,因为wiki百科中的数据是以XML格式组织起来的,所以我们需要寻求些方法。查询之后发现有两种主要的方式:gensim的wikicorpus库,以及wikipedia Extractor。
WikiExtractor
Wikipedia Extractor是一个用Python写的维基百科抽取器,使用非常方便。下载之后直接使用这条命令即可完成抽取,运行时间很快。执行以下命令。
相关链接:
相关命令:
|
1 2 3 |
$ git clone https://github.com/attardi/wikiextractor.git $ python ./wikiextractor/WikiExtractor.py -b 2048M -o extracted zhwiki-latest-pages-articles.xml.bz2 |
相关说明:
- -b 2048M表示的是以128M为单位进行切分,默认是1M。
- extracted:需要将提取的文件存放的路径;
- zhwiki-latest-pages-articles.xml.bz2:需要进行提取的.bz2文件的路径
二次处理:
通过Wikipedia Extractor处理时会将一些特殊标记的内容去除了,但有时这些并不影响我们的使用场景,所以只要把抽取出来的标签和一些空括号、「」、『』、空书名号等去除掉即可。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
import re import sys import codecs def filte(input_file): p1 = re.compile('[(\(][,;。?!\s]*[)\)]') p2 = re.compile('《》') p3 = re.compile('「') p4 = re.compile('」') p5 = re.compile('<doc (.*)>') p6 = re.compile('</doc>') p7 = re.compile('『』') p8 = re.compile('『') p9 = re.compile('』') p10 = re.compile('-\{.*?(zh-hans|zh-cn):([^;]*?)(;.*?)?\}-') outfile = codecs.open('std_' + input_file, 'w', 'utf-8') with codecs.open(input_file, 'r', 'utf-8') as myfile: for line in myfile: line = p1.sub('', line) line = p2.sub('', line) line = p3.sub('“', line) line = p4.sub('”', line) line = p5.sub('', line) line = p6.sub('', line) line = p7.sub('', line) line = p8.sub('“', line) line = p9.sub('”', line) line = p10.sub('', line) outfile.write(line) outfile.close() if __name__ == '__main__': input_file = sys.argv[1] filte(input_file) |
保存后执行 python filte.py wiki_00 即可进行二次处理。
gensim的wikicorpus库
转化程序:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# -*- coding: utf-8 -*- from gensim.corpora import WikiCorpus import os class Config: data_path = '/home/qw/CodeHub/Word2Vec/zhwiki' zhwiki_bz2 = 'zhwiki-latest-pages-articles.xml.bz2' zhwiki_raw = 'zhwiki_raw.txt' def data_process(_config): i = 0 output = open(os.path.join(_config.data_path, _config.zhwiki_raw), 'w') wiki = WikiCorpus(os.path.join(_config.data_path, _config.zhwiki_bz2), lemmatize=False, dictionary={}) for text in wiki.get_texts(): output.write(' '.join(text) + '\n') i += 1 if i % 10000 == 0: print('Saved ' + str(i) + ' articles') output.close() print('Finished Saved ' + str(i) + ' articles') config = Config() data_process(config) |
化繁为简
维基百科的中文数据是繁简混杂的,里面包含大陆简体、台湾繁体、港澳繁体等多种不同的数据。有时候在一篇文章的不同段落间也会使用不同的繁简字。这里使用opencc来进行转换。
|
1 |
$ opencc -i zhwiki_raw.txt -o zhswiki_raw.txt -c t2s.json |
中文分词
这里直接使用jieba分词的命令行进行处理:
|
1 |
$ python -m jieba -d " " ./zhswiki_raw.txt >./zhswiki_cut.txt |
转换成 utf-8 格式
非 UTF-8 字符会被删除
|
1 |
$ iconv -c -t UTF-8 -o zhwiki.utf8.txt zhwiki.zhs.txt |
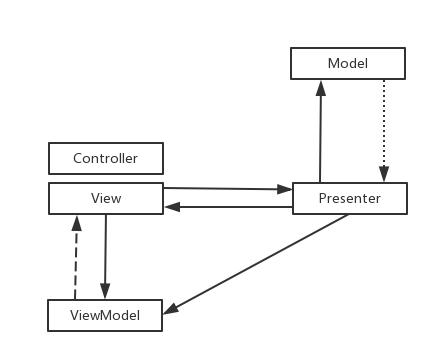
MVC/MVP/MVVM/MVPVM区别
分析主要是通过它的控制链、控制流向,View 的变化如何反馈到Model,以及Model的变化如何作用到View上。
MVC
View 持有了Controller,把事件传递给Controller,Controller 由此去触发Model层的事件,Model更新完数据(网络或者本地数据)之后触发View的更新事件
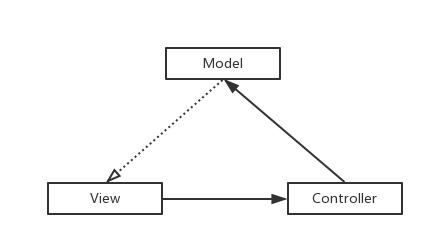
MVP
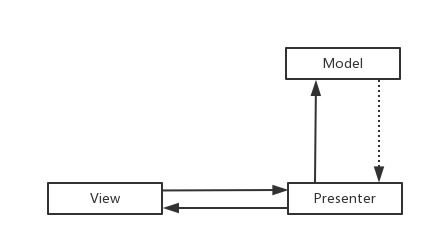
咋看一下MVP只是MVC的变更版,把C层替换成了P层,实则不是这样的,最根本的是添加了Presenter层。
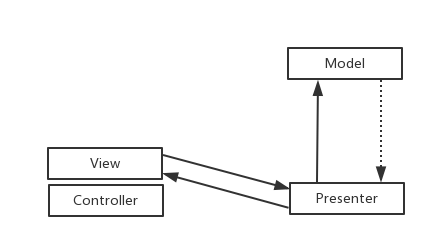
MVP其实是MVC的封装和演化,Controller被拆分,只用它处理View的点击事件,数据绑定,等处理,而View被拆分,更加专注于视图的更新,只做跟视图相关的操作,而Presenter被独立出来,用于沟通View和Model之间的联系,Model不能直接作用于View 的更新,只能通过Presenter来通知View进行视图的刷新,比如showLoading(),showEmpty(),showToast()等等,这样View就完全被独立出来了,只是被动接受Presenter的命令,这样避免了View 有过多的逻辑处理,更加简单。Presenter持有了Model。Model 只用于处理跟数据获取相关的逻辑。
MVVM
又称状态机制,View和ViewModel 是进行绑定的,改变ViewModel 就会直接作用到View视图上,而View 会把事件传递给ViewModel,ViewModel去对Model进行操作并接受更新。
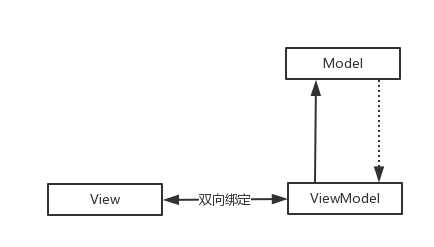
MVPVM
可以看到MVPVM 其实就是MVP的变种,加入了MVVM事件特性,增加了ViewModel,功能分类:
View:只做视图更新操作
Model: 只做数据处理,网络数据 、本地数据
Presenter: 只做业务逻辑处理,View或者Model 事件分发
ViewModel: 绑定View 和 Model,添加数据变更监视器
Android官方给出的例子参考 todo-mvvm-databinding,todo-mvp。
参考链接
macOS Catalina 10.15.2安装配置WordPress 5.3.2并建立PHP调试环境
macOS Catalina 10.15.2 自带的 Apache2,PHP 在配置的时候,非常困难,而且不管如何配置,都没办法跟 MySQL 数据库连接,总之会出现各种问题,而且各种插件安装异常麻烦。
尝试过使用 brew 安装 MySQL,XAMPP,但是也是都没办法成功配置。macOS系统更改了太多的东西,各种不方便啊。
最后还是使用 XAMPP-VM 或者干脆搭建一个 VirtualBox 虚拟机在 Linux 下进行开发吧。
下面,我们介绍一下使用 XAMPP-VM 进行开发的方法。
代码实现WordPress评论回复自动发邮件的功能
评论邮件通知的方法:
对于服务器上需要使用SMTP验证的,需要使用PHPMailer替代默认的WordPress默认的Mail发送邮件时配置SMTP相关信息,如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
function mailer_config(PHPMailer $mailer){ $mailer->IsSMTP(); $mailer->Host = "smtp.sina.com"; // your SMTP server $mailer->Port = 465; $mailer->SMTPDebug = 0; // write 0 if you don't want to see client/server communication in page $mailer->CharSet = "UTF-8"; $wp_email = get_bloginfo ('admin_email'); /////下面是一些服务器要求的配置 $mailer->SMTPAuth = true; // 允许 SMTP 认证 // 如果是用网站的管理员邮箱地址 ,可以如下代码 $mailer->Username = $wp_email; // $mailer->Username = '邮箱用户名'; // SMTP 用户名 即邮箱的用户名 // 这里强烈建议使用授权码而不是密码进行认证,授权码可以提供比较高的安全保护 $mailer->Password = '密码或者授权码'; // SMTP 密码 部分邮箱是授权码(例如163邮箱/新浪邮箱) $mailer->SMTPSecure = 'ssl'; // 允许 TLS 或者SSL协议 //Content $mailer->isHTML(true); // 是否以HTML文档格式发>送 发送后客户端可直接显示对应HTML内容 //网站发出的邮件,最好都存档一下 // $mailer->addCC($wp_email); // 添加抄送人 // $mailer->addCC($wp_email); // 添加多个抄送人 // $mailer->ConfirmReadingTo = $wp_email; // 添加发送回执邮件地址,即当收件人打开邮件后,会询问是否发生回执 $mailer->addBCC($wp_email); // 秘密抄送到指定邮箱 } add_action( 'phpmailer_init', 'mailer_config', 10, 1); |
注意,目前测试在WordPress 5.8版本,上述的代码会诱发异常
|
1 |
Got error 'PHP message: PHP Fatal error: Uncaught TypeError: Argument 1 passed to mailer_config() must be an instance of PHPMailer, instance of PHPMailer\\PHPMailer\\PHPMailer given |
解决方法为注释掉函数的类型(PHPMailer)声明,如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
function mailer_config(/*PHPMailer*/ $mailer){ $mailer->IsSMTP(); $mailer->Host = "smtp.sina.com"; // your SMTP server $mailer->Port = 465; $mailer->SMTPDebug = 0; // write 0 if you don't want to see client/server communication in page $mailer->CharSet = "UTF-8"; $wp_email = get_bloginfo ('admin_email'); /////下面是一些服务器要求的配置 $mailer->SMTPAuth = true; // 允许 SMTP 认证 // 如果是用网站的管理员邮箱地址 ,可以如下代码 $mailer->Username = $wp_email; // $mailer->Username = '邮箱用户名'; // SMTP 用户名 即邮箱的用户名 // 这里强烈建议使用授权码而不是密码进行认证,授权码可以提供比较高的安全保护 $mailer->Password = '密码或者授权码'; // SMTP 密码 部分邮箱是授权码(例如163邮箱/新浪邮箱) $mailer->SMTPSecure = 'ssl'; // 允许 TLS 或者SSL协议 //Content $mailer->isHTML(true); // 是否以HTML文档格式发>送 发送后客户端可直接显示对应HTML内容 //网站发出的邮件,最好都存档一下 // $mailer->addCC($wp_email); // 添加抄送人 // $mailer->addCC($wp_email); // 添加多个抄送人 // $mailer->ConfirmReadingTo = $wp_email; // 添加发送回执邮件地址,即当收件人打开邮件后,会询问是否发生回执 $mailer->addBCC($wp_email); // 秘密抄送到指定邮箱 } add_action( 'phpmailer_init', 'mailer_config', 10, 1); |
1.所有回复都发送邮件通知
登陆博客后台,点击“外观”选项卡下的“编辑”选项进入主题编辑界面,在functions.php文件中的<?php和?>之间添加以下函数即可:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
/* comment_mail_notify v1.0 by willin kan. (所有回复都发邮件) */ function comment_mail_notify($comment_id) { $comment = get_comment($comment_id); $parent_id = $comment->comment_parent ? $comment->comment_parent : ''; $spam_confirmed = $comment->comment_approved; if (($parent_id != '') && ($spam_confirmed != 'spam')) { /* 对于没有自己邮件服务器的个人网站来说, 如果需要使用站长自己的邮箱地址发送, 那么邮箱头必须是登陆账号的邮箱地址, 否则邮箱服务器(比如新浪)会拒绝发送邮件, 报错返回邮箱地址跟登陆地址不一致 */ $wp_email = get_bloginfo ('admin_email'); // $wp_email = 'no-reply@' . preg_replace('#^www\.#', '', strtolower($_SERVER['SERVER_NAME'])); //e-mail 发出点, no-reply 可改为可用的 e-mail. $to = trim(get_comment($parent_id)->comment_author_email); $subject = '您在 [' . get_option("blogname") . '] 的留言有了回复'; $message = ' <div style="background-color:#eef2fa; border:1px solid #d8e3e8; color:#111; padding:0 15px; -moz-border-radius:5px; -webkit-border-radius:5px; -khtml-border-radius:5px;"> <p>' . trim(get_comment($parent_id)->comment_author) . ', 您好!</p> <p>您曾在《' . get_the_title($comment->comment_post_ID) . '》的留言:<br />' . trim(get_comment($parent_id)->comment_content) . '</p> <p>' . trim($comment->comment_author) . ' 给您的回复:<br />' . trim($comment->comment_content) . '<br /></p> <p>您可以 <a href="'.get_comment_link($comment).'">点击</a> 查看完整內容</p> <p>欢迎再度光临 <a href="'.home_url().'">'.get_option('blogname').'</a></p> <p>(此邮件由系统自动发送,请勿回复.)</p> </div>'; $from = "From: \"" . get_option('blogname') . "\" <$wp_email>"; $headers = "$from\nContent-Type: text/html; charset=" . get_option('blog_charset') . "\n"; wp_mail( $to, $subject, $message, $headers ); //echo 'mail to ', $to, '<br/> ' , $subject, $message; // for testing } } add_action('comment_post', 'comment_mail_notify'); // -- END ---------------------------------------- |
2.让访客自己选择是否邮件通知
在functions.php文件中的<?php和?>之间添加以下函数,该函数将会在评论框底部生成要不要收回复通知的选项(与主题有关)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
/* 开始*/ function comment_mail_notify($comment_id) { $admin_notify = '1'; // admin 要不要收回复通知 ( '1'=要 ; '0'=不要 ) $admin_email = get_bloginfo ('admin_email'); // $admin_email 可改为你指定的 e-mail. $comment = get_comment($comment_id); $comment_author_email = trim($comment->comment_author_email); $parent_id = $comment->comment_parent ? $comment->comment_parent : ''; global $wpdb; if ($wpdb->query("Describe {$wpdb->comments} comment_mail_notify") == '') $wpdb->query("ALTER TABLE {$wpdb->comments} ADD COLUMN comment_mail_notify TINYINT NOT NULL DEFAULT 0;"); if (($comment_author_email != $admin_email && isset($_POST['comment_mail_notify'])) || ($comment_author_email == $admin_email && $admin_notify == '1')) $wpdb->query("UPDATE {$wpdb->comments} SET comment_mail_notify='1' WHERE comment_ID='$comment_id'"); $notify = $parent_id ? get_comment($parent_id)->comment_mail_notify : '0'; $spam_confirmed = $comment->comment_approved; if ($parent_id != '' && $spam_confirmed != 'spam' && $notify == '1') { /* 对于没有自己邮件服务器的个人网站来说, 如果需要使用站长自己的邮箱地址发送, 那么邮箱头必须是登陆账号的邮箱地址, 否则邮箱服务器(比如新浪)会拒绝发送邮件, 报错返回邮箱地址跟登陆地址不一致 */ $wp_email = get_bloginfo ('admin_email'); // $wp_email = 'no-reply@' . preg_replace('#^www\.#', '', strtolower($_SERVER['SERVER_NAME'])); // e-mail 发出点, no-reply 可改为可用的 e-mail. $to = trim(get_comment($parent_id)->comment_author_email); $subject = '您在 [' . get_option("blogname") . '] 的留言有了回复'; $message = ' <div style="background-color:#eef2fa; border:1px solid #d8e3e8; color:#111; padding:0 15px; -moz-border-radius:5px; -webkit-border-radius:5px; -khtml-border-radius:5px;"> <p>' . trim(get_comment($parent_id)->comment_author) . ', 您好!</p> <p>您曾在《' . get_the_title($comment->comment_post_ID) . '》的留言:<br />' . trim(get_comment($parent_id)->comment_content) . '</p> <p>' . trim($comment->comment_author) . ' 给您的回复:<br />' . trim($comment->comment_content) . '<br /></p> <p>您可以 <a href="'.get_comment_link($comment).'">点击</a> 查看完整內容</p> <p>欢迎再度光临 <a href="'.home_url().'">'.get_option('blogname').'</a></p> <p>(此邮件由系统自动发送,请勿回复.)</p> </div>'; $from = "From: \"" . get_option('blogname') . "\" <$wp_email>"; $headers = "$from\nContent-Type: text/html; charset=" . get_option('blog_charset') . "\n"; wp_mail( $to, $subject, $message, $headers ); //echo 'mail to ', $to, '<br/> ' , $subject, $message; // for testing } } add_action('comment_post', 'comment_mail_notify'); /* 自动加勾选栏 */ function add_checkbox() { echo '<input type="checkbox" name="comment_mail_notify" id="comment_mail_notify" value="comment_mail_notify" checked="checked" style="margin-left:20px;" /><label for="comment_mail_notify">有人回复时邮件通知我</label>'; } add_action('comment_form', 'add_checkbox'); |
3.让博客管理员决定什么情况下发邮件
关于WordPress中提示has_cap的问题
WordPress 中不同用户等级拥有不同的操作权限,这给我们的网站安全提供了很大的保障。在 WordPress 2.0 以前,WP 插件中使用数字(用户等级)来标识不同的权限级别。这显然让程序的可阅读性大打折扣。所以从 WordPress 2.0 开始就启用了新的权限标识符号,使用有具体含义的英文字符串,同时保留原来的那一套表示方法。很多插件作者并没有采用新的权限表示方式,因而在开启 WordPress 的调试模式后,用户会看到警告。
>英文版本的警告类似于,
|
1 |
Notice: has_cap was called with an argument that is deprecated since version 2.0! Usage of user levels by plugins and themes is deprecated. Use roles and capabilities instead. in ......\wp-includes\functions.php on line 2998 |
为了安全,上面的语句中隐去了绝对路径而代之以省略号。
中文版本的警告类似于,
|
1 |
Notice: 自 2.0 版本起,已不建议给 has_cap 传入一个参数!插件和主题中,用户等级的使用已不被支持。请换用角色和权限。 in ....../wp-includes/functions.php on line 2998 |
可以看到,只是“不建议”,并不是完全不能用了。
要解决这个问题,只需要将插件(也许还包括某些主题)中用到的权限声明的表示方式替换为新的方式就可以了。
目录 Contents
1. 定位需要改写的语句
首先要定位到需要改写的语句,这是个比较麻烦的任务。
从上面的警告信息中并不能直接知道是哪个文件调用了 functions.php 中的 has_cap 函数。所以这里只是给个思路,无法给出明确的方法。
对于插件,一般是因为插件需要在 WordPress 的管理后台创建插件的设置页面时进行权限声明的。比如在 WordPress Revision 插件中遇到的情况就是这样。出现这种情况的标志性语句是,
|
1 |
add_options_page |
只要在插件源文件中搜索 add_options_page 关键词即可定位。
如果不是这种情况,那就可以挨个儿禁用 WP 中的插件,同时刷新页面以确定是否是当前插件造成的。如果恰好发现该警告信息不再提示了,就说明是当前的插件。然后在该插件的源文件中去找相关的语句。
另外,还可以通过在 WP 后台中操作时出现错误提示的路径信息来缩小检查范围。如果有什么需要,可以留言咨询。
2. 改写表达方式
如果定位到了出问题的 PHP 语句,改写表达方式就很简单了。下面一节介绍了 WordPress 中新旧角色权限表达方式的对比。只需要将原来的表示用户级别的数字改成新的表示权限的字符串就可以了。
例如,原来的 PHP 语句为,
|
1 |
add_options_page('Delete-Revision', 'Delete-Revision',8, basename(__FILE__), 'my_options_delete_revision'); |
该语句因为要在 WordPress 后台添加一个插件的“选项”页面,因而需要用到 WordPress 中的第 8 级权限。查到对应的新的权限字符串为 'manage_options'。对应修改为,
|
1 |
add_options_page('Delete-Revision', 'Delete-Revision', 'manage_options', basename(__FILE__), 'my_options_delete_revision'); |
只需要改其中那个数字 8,别的不需要动。
应该注意的是,根据 PHP 的规则,传递的参数如果是整型数字,可以不用加单引号,但是改成字符串之后,我们需要用英文半角的单引号将该字符串包起来。
3. 新旧权限表示方式对照
WordPress Codex 中有关于旧版本数字式用户级别和新的字符串式权限声明的详细说明可供参考。
在数字式用户级别页面的 3.12 User Level Capability Table 表格中列出了 11 个用户级别对应的权限。而在字符串式权限声明页面中 3.8 Capability vs. Role Table 一节里列举了所有权限字符串所代表的权限级别(对应于超级管理员、管理员等)。
原先的数字式级别与新的字符串式权限之间并不是一一对应的。具体应该将数字换成哪个字符串需要仔细斟酌。可能还需要根据在本文第 1 小节中定位出的 PHP 语句来辅助判断。原则上,权限在够用的前提下越小越好。
例如,前面的例子中需要增加 options 页面,那肯定是管理员级别的权限。增加 options 页面的目的就是保存该插件的设置信息,这些信息是需要写入到 WordPress 数据库的 options 表中的。所以,可以确定为 manage_options 这个字符串。
在 Capabilities 一节中详细解释了各个字符串所代表的操作权限的范围。而在 User Levels 一节中则给出了旧式数字用户等级所对应的权限范围,方便缩小查找权限字符串的范围。8-10 级对应于管理员,3-7 级对应于编辑,2 级是作者,1 级是贡献者,0 级是权限最低的订阅者。
参考链接
WordPress插件的语言国际化
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
$ brew install wp-cli # Create a POT file for the WordPress plugin/theme in the current directory # wp i18n make-pot . languages/my-plugin.pot # Create a POT file for the continents and cities list in WordPress core. #wp i18n make-pot . continents-and-cities.pot --include="wp-admin/includes/continents-cities.php" --ignore-domain $ wp i18n make-pot . languages/SpeakIt-zh_CN.po $ brew install gettext $ brew link --force gettext $ brew install Gtranslator # 比较好用的反而是QT的 Linguist, 其实直接文本编辑器编辑,更直接 $ gtranslator languages/SpeakIt-zh_CN.po $ msgfmt -o SpeakIt-zh_CN.mo SpeakIt-zh_CN.po |
调试的时候,通过在 wp-config.php 中定义 define('WPLANG', 'zh_CN'); 来切换语言类型。
参考链接
- WordPress主题制作教程(八): WordPress的语言国际化
- Function Reference/load plugin textdomain
- WordPress Plugin Internationalization (i18n) Localization (L10n)
- I18n for WordPress Developers
- wordpress 插件 汉化
- wordpress插件国际化(I18n)
- WordPress 插件开发 支持多语言 国际化 图文教程
- 语言文件.po .pot和.mo简介及汉化
- 什么是本地化?
- WordPress函数:load_plugin_textdomain
- How to create .pot files with POedit?
- wp i18n make-pot
- WordPress 5.0+支持JavaScript i18n本地化翻译
- wp-cli/i18n-command
- 使用 WP-CLI 在命令行安装WORDPRESS
- Gettext po文件编辑器
- WordPress i18n: Make Your Plugin Translation Ready
Gettext po文件编辑器
Gettext 是一个非常老牌和成熟的国际化和本地化解决方案,在 Linux 下几乎每个 GNU 程序中都能见到 Gettext 的身影。在 Gettext 中,每个 locale 对应一个 po 文件,虽说 po 文件是纯文本,但是如果用普通的文本编辑器来编辑是非常麻烦的。
正好这两天国际化 ,搜到了几个 Linux 下的 po 编辑器~,推荐 Gtranslator 。WordPress 翻译( i18n )的时候使用这些工具。
macOS 下安装如下命令:
|
1 2 3 4 5 6 7 |
$ brew install gettext $ brew link --force gettext $ brew install Gtranslator $ gtranslator |
继续阅读Gettext po文件编辑器
WordPress文章内容加上TTS语音朗读
浏览一些博客的时候是否有看到过在内容上面有可以选择语音朗读功能,看着感觉还是蛮炫酷的。尤其是移动端的网站阅读体验比较好,比如一些内容教程、小说类型的网站可以使用这样的功能。
这里我们一般是使用的是百度提供的TTS(Text To Speech)文本到语音功能。
如下是实现这个基本功能的插件实现的代码。如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
<?php /** * @package SpeakIt */ /* Plugin Name: Speak It Plugin URI: https://www.mobibrw.com/speakit Description: Plugin for Speak Version: 1.0 Author: longsky Author URI: https://www.mobibrw.com License: GPLv2 or later Text Domain: SpeakIt */ ?> <?php function mbStrSplit ($string, $len = 1) { //对内容进行分割 $start = 0; $strlen = mb_strlen($string); while ($strlen) { $array[] = mb_substr($string, $start, $len, "utf8"); $string = mb_substr($string, $len, $strlen, "utf8"); $strlen = mb_strlen($string); } return $array; } function match_chinese($chars, $encoding = 'utf8') { //过滤特殊字符串 $pattern = ($encoding == 'utf8')?'/[\x{4e00}-\x{9fa5}a-zA-Z0-9,,。 ]/u':'/[\x80-\xFF]/'; preg_match_all($pattern, $chars, $result); $temp = join('', $result[0]); return $temp; } function load_template_html($tts_uri, $ctx) { $template_html = '<video id="speakit_video" style="display:none"> <source id="speakit_src" type="video/mp4"> </video> <script type="text/javascript"> var speakitOff = 0; var speakitUri = "'.$tts_uri.'"; var speakitCtx = eval('.$ctx.'); var speakitAud = document.getElementById("speakit_video"); if (speakitCtx.length > 0) { speakitAud.src = speakitUri + speakitCtx[speakitOff]; } function playSpeakItContent() { var speakitAudBtn = document.getElementById("speakit_btn"); if (speakitAud.paused && speakitCtx.length > 0) { speakitAudBtn.src = "'.plugins_url('images/pause.png', __FILE__).'"; //暂停图片 speakitAud.src = speakitUri + speakitCtx[speakitOff]; speakitAud.onended = function() { speakitOff = speakitOff + 1; if (speakitOff < speakitCtx.length) { speakitAud.src = speakitUri + speakitCtx[speakitOff]; speakitAud.play(); } else { if (!speakitAud.paused) { speakitAud.pause(); } speakitOff = 0; speakitAudBtn.src = "'.plugins_url('images/play.png', __FILE__).'"; //暂停图片 } }; speakitAud.play(); } else { if (!speakitAud.paused) { speakitAud.pause(); } speakitAudBtn.src = "'.plugins_url('images/play.png', __FILE__).'"; //播放图片 } } </script> <span style="float: left; margin-right: 10px; cursor: pointer;"> <a href="javascript:playSpeakItContent();"><img src="'.plugins_url('images/play.png', __FILE__).'" width="25" height="25" id="speakit_btn" border="0"></a> </span>'; return $template_html; } function load_speak_html($content) { $str = $content; $str = strip_tags($str); $str = str_replace("、", ",", $str); //保留顿号 $str = match_chinese($str); $ctx_len = mb_strlen(preg_replace('/\s/', '', html_entity_decode(strip_tags($str))), 'UTF-8'); $r = mbStrSplit($str, 900); $tts_uri = "https://tts.baidu.com/text2audio?cuid=baiduid&lan=zh&ctp=1&pdt=311&tex="; return load_template_html($tts_uri, json_encode($r)); } function speakit_main($content) { if(is_single()||is_feed()) { $html = load_speak_html($content); $content = $html.$content; } return $content; } add_filter ('the_content', 'speakit_main'); ?> |
这里我们将代码添加到WordPress的plugins目录下的SpeakIt目录下。
里面有两个按钮play.png,pause.png,需要存放到SpeakIt插件的images目录下:
![]()

参考链接
ubuntu 16.04安装配置WordPress 5.3.2并建立PHP调试环境
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
$ sudo apt-get install apache2 $ sudo apt-get install mysql-server $ sudo apt-get install mysql-client $ sudo apt-get install php7.0 $ sudo apt-get install php-gd $ sudo apt install php-mbstring $ sudo apt install php-dom # 如果使用了WP-Statistics统计插件,需要安装依赖 $ sudo apt-get install php7.0-curl $ sudo apt-get install php7.0-bcmath # PHP Zip支持,提高网络以及内存压缩工具,提升性能 $ sudo apt-get install php-zip # PHP图像处理支持,imagick替代默认的GD图像处理,提升图像处理性能 $ sudo apt install php-imagick # 默认imagick是不启用的,需要手工开启 $ sudo phpenmod imagick $ sudo a2dismod mpm_prefork $ sudo a2enmod mpm_event $ sudo apt-get install libapache2-mod-fastcgi php7.0-fpm $ sudo service php7.0-fpm restart $ sudo a2enmod actions fastcgi alias proxy_fcgi $ sudo apt-get install php-mysql # 启用 Rewrite 模块,我们后续的WP Super Cache需要这个模块的支持 $ sudo a2enmod rewrite $ sudo service apache2 restart # 我们以root连接数据库,我们需要手工创建数据库,否则会出现如下错误: # “我们能够连接到数据库服务器(这意味着您的用户名和密码正确),但未能选择wordpress数据库。” $ mysql -u root -p -e "create database wordpress;" $ cd /var/www $ sudo chown -R www-data:www-data wordpress |
WordPress配置文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
<VirtualHost *:80> # The ServerName directive sets the request scheme, hostname and port that # the server uses to identify itself. This is used when creating # redirection URLs. In the context of virtual hosts, the ServerName # specifies what hostname must appear in the request's Host: header to # match this virtual host. For the default virtual host (this file) this # value is not decisive as it is used as a last resort host regardless. # However, you must set it for any further virtual host explicitly. #ServerName www.example.com ServerAdmin webmaster@localhost #DocumentRoot /var/www/html DocumentRoot /var/www/wordpress <Directory /var/www/wordpress> #Options Indexes FollowSymLinks MultiViews Options FollowSymLinks MultiViews AllowOverride All # Apache 2.2 # FCGIWrapper /usr/bin/php5-cgi .php # AddHandler fcgid-script .php # Options ExecCGI SymLinksIfOwnerMatch # Apache 2.4.10 <FilesMatch \.php$> SetHandler "proxy:unix:/run/php/php7.0-fpm.sock|fcgi://localhost" </FilesMatch> Order allow,deny allow from all </Directory> # Available loglevels: trace8, ..., trace1, debug, info, notice, warn, # error, crit, alert, emerg. # It is also possible to configure the loglevel for particular # modules, e.g. #LogLevel info ssl:warn ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined # For most configuration files from conf-available/, which are # enabled or disabled at a global level, it is possible to # include a line for only one particular virtual host. For example the # following line enables the CGI configuration for this host only # after it has been globally disabled with "a2disconf". #Include conf-available/serve-cgi-bin.conf </VirtualHost> # vim: syntax=apache ts=4 sw=4 sts=4 sr noet |
继续阅读ubuntu 16.04安装配置WordPress 5.3.2并建立PHP调试环境