零、前言
匈牙利算法是一个经典的解决二部图最小权值匹配问题的算法。网上也有不少资料,但是看完之后总觉得有两个核心问题没有解决:算法为什么一定能得到最优匹配?算法复杂度为什么不再是指数级了?
最后读到了python的库函数scipy.optimize.linear_sum_assignment源代码里引用的文章,才算理解算法的实现,再花了一点时间弄清楚了上边两个问题。
一、问题描述
匈牙利算法解决的问题一般这样通俗的描述:有n个工作,需要指派给n个工人,每个工人完成每个工作的时间可能都不一样,给出一个算法,使得得到的指派结果总的时间最少。
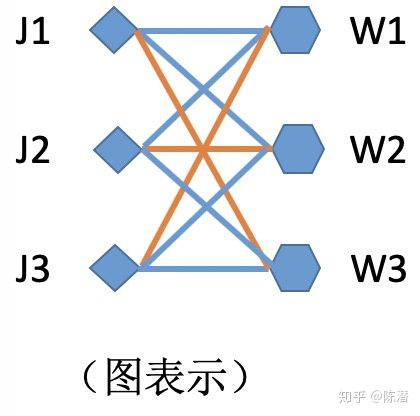
用一个矩阵表示:

矩阵的(i,j)元素值,代表第i个工人完成第j个工作的时间,称为权值矩阵。
二、算法的核心步骤
算法的具体实现参阅

本站链接 Munkres' Assignment Algorithm
这里只讲关键的步骤:
1.每一行减去该行最小值
2.通过寻找增广路径的方式,尝试进行不带权重的匹配,只有值为0的项为可匹配项
3.如果最大匹配数为n,则结束,当前匹配为最优匹配,否则执行第4步
4.用最少的横线和竖线覆盖所有零值,取mv=未被覆盖的矩阵块的最小元素,所有未被覆盖的矩阵块的元素减去mv,所有被横竖线都覆盖的矩阵块的元素加上mv,然后回到第2步
第二步怎么找增光路径后面再解释,先解释一下第四步:
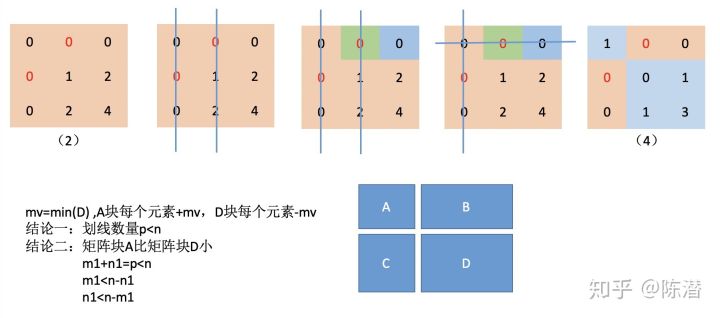
(0)第一张图标红的两个零是暂时作为结果的两个匹配
(1)把他们所在的两列覆盖
(2)找到一个没有被覆盖的蓝色块的0,它所在的第一行有一个绿色块的0是被标红的,于是把第一行覆盖,取消对绿色块0所在列的覆盖
(3)重复第二步,直到找不出未被覆盖的0,这个时候把矩阵分成了ABCD四块,执行上图里的操作。
这里有两个结论后边会用到:
(1)划线(所有横线竖线)数量p<n
(2)矩阵块A的大小比D小,意味着A的元素数量比D小
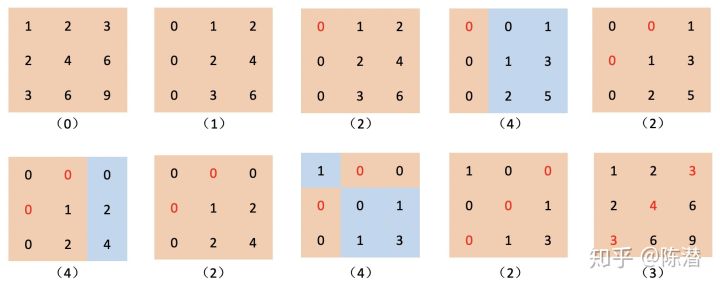
举一个完整的例子:
三、算法为什么是有效的?
现在回答第一个问题。
结合算法的步骤,算法有效相当于三个子问题:
(1)如果得到一个结果,一定是最后匹配?
(2)没有达到完全匹配时,第4步总是可以实现?
(3)第2步和第4步的循环可以终止?
(1)如果得到一个结果,一定是最后匹配?
这是由两点保证的:
•对于经过变换最后的权值矩阵,我们找到的匹配结果是最优匹配,因为权值和为0
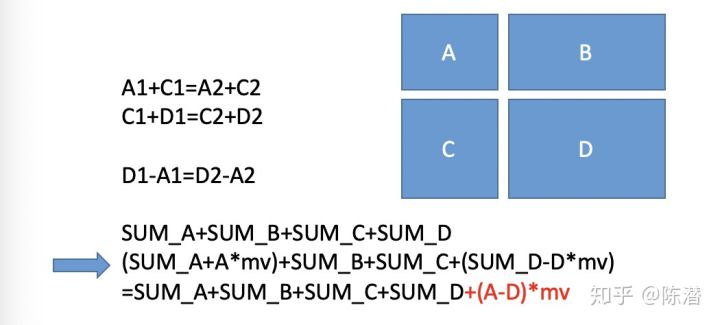
•权值矩阵经过变换前后,所有合法匹配之间权值和的差值不变:
SUM_A1-SUM_B1=SUM_A2-SUM_B2=……
解释一下就是说,比如有两个任意的合法匹配结果A和B,他们不一定说最优的,但都是合法的,意味着每行每列都有一个匹配。在做第四步变换之前,他们的权值和分别为SUM_A1和SUM_B1,差值说SUM_A1-SUM_B1。在做第四步变换之后,他们的权值和的差值SUM_A2-SUM_B2,这两个差值在变换前后保持不变。也就是说我们要找的最优匹配原本是个弟弟,变换后还是个弟弟,还是会被我们准确的揪出来。
差值不变这么解释:
(2)没有达到完全匹配时,第4步总是可以实现?
回到上边的第一个结论:划线数量p<n,所以一定可以找出上图这样的矩阵分块
(3)第2步和第4步的循环可以终止?
首先权值矩阵经过第一步之后所有元素都大于零,所以元素和也大于零。
然后每一次第四步的变换,都会使元素和减少,因此循环会终止。
每次减少的量为(D-A)*mv,这里A和D表示A块和D块的元素数量,上边第二个结论说了D>A。
这里有个问题没有很确定,那这个循环的次数为啥不是指数增长的?
四、算法复杂度为什么不是指数级?
这里说一下怎么通过增广路径寻找最大匹配
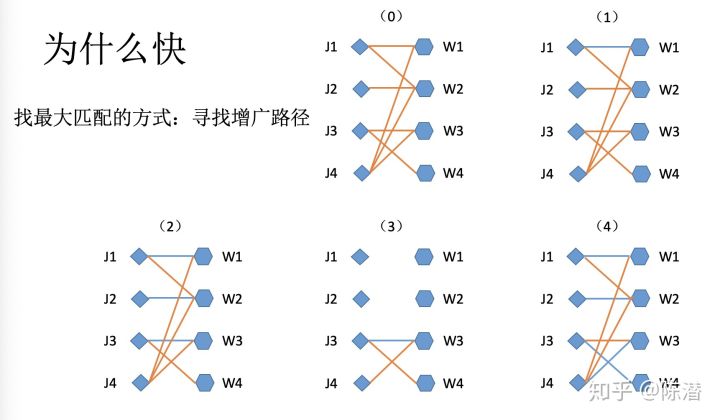
上图找到第四张图增广路径的方式是深度搜索,尝试把原本匹配了的关系解绑,看能不能找到更多匹配。但其实只说是深度搜索的话也有可能是指数级的。算法变快的原因是在尝试过程当中,已经失败的路径中间经过的所有顶点,之后都不再尝试了。
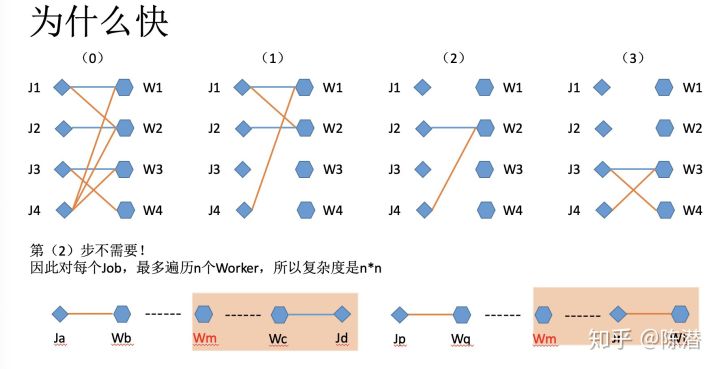
以上。
您好,请教下WordPress自带备案链接地址在哪里修改?工信部现在网址变更了,但WordPress还是旧的地址。
请看我有文章单独介绍这个问题的