介绍 mbedtls 的 tls client 的使用方法,常见的功能参数配置和含义。 当前使用的 mbedtls 版本是: mbedtls-3.4.0。
功能参数配置
需要配置的功能选项
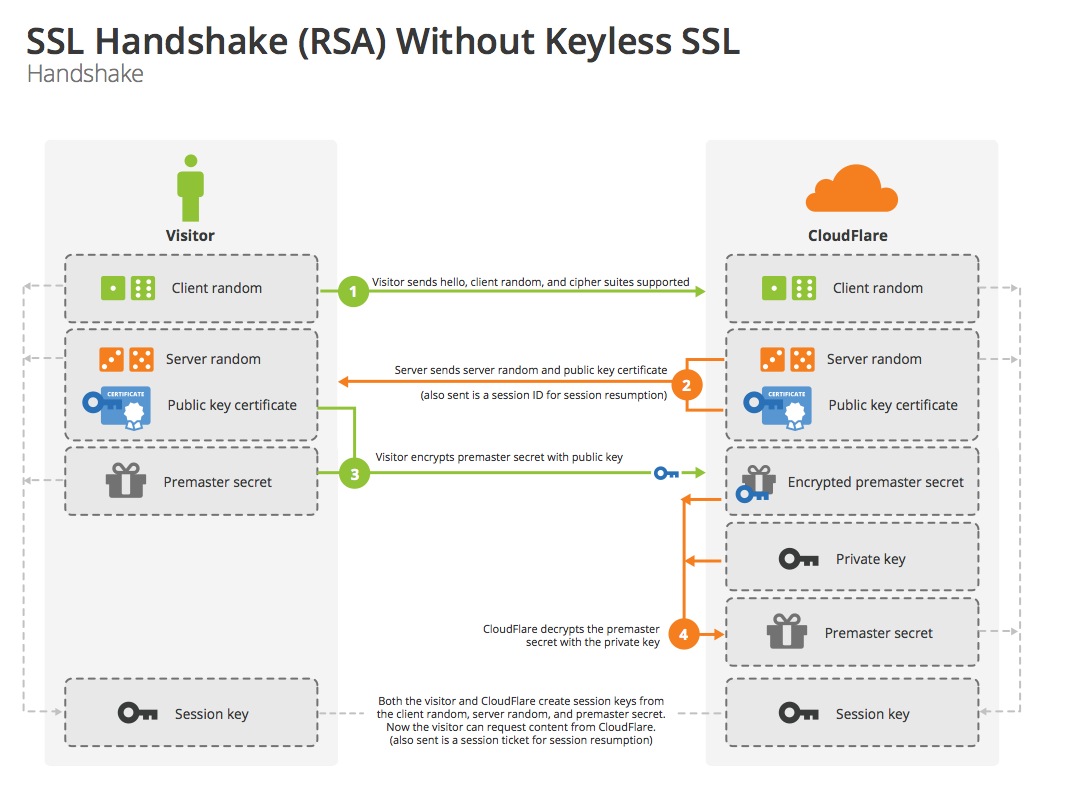
- 设置 tls 协议版本: 配置 tls 1.2, tls 1.3, 还是二者都支持。
- 认证方式设置:单向认证、双向认证、还是 psk。
- 握手时的校验等级设置:不校验证书合法性,仅加密;校验,但如果失败也继续执行后面的握手流程;校验不通过则终止握手流程。
- 服务器ca证书设置
- 客户端证书和密钥设置
- 预定义共享密钥设置
编译配置
使用 mbedtls_config.h 配置文件,tls 1.2 默认打开,不需要修改,但 tls 1.3 未开启,需要特别设置。
|
1 2 3 4 5 |
//mbedtls_config.h #define MBEDTLS_SSL_PROTO_TLS1_3 #define MBEDTLS_SSL_TLS1_3_COMPATIBILITY_MODE #define MBEDTLS_USE_PSA_CRYPTO #define MBEDTLS_PSA_CRYPTO_CONFIG |
解决 mps_common.h 中的编译问题,替换 MBEDTLS_MPS_STORED_SIZE_MAX 和 MBEDTLS_MPS_SIZE_MAX 宏定义。
|
1 2 3 |
//mps_common.h #define MBEDTLS_MPS_STORED_SIZE_MAX (SIZE_MAX) #define MBEDTLS_MPS_SIZE_MAX (SIZE_MAX) |
API 设计和实现
接口处理的事情,主要是连接参数配置、打开和关闭连接,接收和发送数据。
数据结构定义:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
typedef enum { QTF_TLS_AUTH_MODE_CERT = 0, // 校验证书 QTF_TLS_AUTH_MODE_PSK, // 预定义共享密钥 QTF_TLS_AUTH_MODE_MAX }qtf_tls_auth_mode_t; typedef enum { QTF_TLS_VERSION_TLS1_2 = 0, // TLS v1.2 QTF_TLS_VERSION_TLS1_3, // TLS v1.3 QTF_TLS_VERSION_TLS1_2_1_3, // TLS v1.2 and TLS v1.3 QTF_TLS_VERSION_MAX }qtf_tls_version_t; typedef enum { QTF_TLS_VERIFY_MODE_NONE = 0, // 不校验证书是否合法 QTF_TLS_VERIFY_MODE_OPTIONAL, // 证书校验失败,继续执行握手 QTF_TLS_VERIFY_MODE_REQUIRED, // 证书校验失败终止握手,推荐配置 QTF_TLS_VERIFY_MODE_MAX }qtf_tls_verify_mode_t; typedef enum { QTF_TLS_DEBUG_LEVEL_NONE = 0, QTF_TLS_DEBUG_LEVEL_ERROR, QTF_TLS_DEBUG_LEVEL_STATE, QTF_TLS_DEBUG_LEVEL_INFO, QTF_TLS_DEBUG_LEVEL_VERBOSE, }qtf_tls_debug_level_t; // tls 报文分片大小设置 typedef enum { QTF_TLS_MAX_FRAG_LEN_NO_USE = 0, // 不设置 QTF_TLS_MAX_FRAG_LEN_512, // 设置 tls 报文分片大小 512 字节 QTF_TLS_MAX_FRAG_LEN_1024, QTF_TLS_MAX_FRAG_LEN_2048, QTF_TLS_MAX_FRAG_LEN_4096, }qtf_tls_max_frag_len_t; typedef struct { qtf_tls_auth_mode_t auth_mode; // 认证方式 qtf_tls_verify_mode_t verify_mode; // 握手校验等级 qtf_tls_version_t tls_version; // tls 协议版本设置 qtf_tls_debug_level_t debug_level; // 调试日志等级设置 qtf_tls_max_frag_len_t max_frag_len; // 报文分片大小设置 uint32_t hanshake_timeout_ms; // 握手超时时间设置 const char *ca_cert; // 服务器ca 证书 uint32_t ca_cert_len; const char *client_cert; // 客户端证书 uint32_t client_cert_len; const char *client_key; // 客户端密钥 uint32_t client_key_len; const char *client_key_passwd; uint32_t client_key_passwd_len; const char *psk; // 预定义共享密钥 uint32_t psk_len; const char *psk_id; }qtf_tls_conn_param_t; |
连接参数配置说明:
-
auth_mode:认证方式设置。
一是通过证书认证,另一个是通过预定义密钥 PSK。
-
verify_mode:握手的校验等级。
推荐配置为 QTF_TLS_VERIFY_MODE_REQUIRED。如果只是想加密而不校验,可以配置 QTF_TLS_VERIFY_MODE_NONE 或 QTF_TLS_VERIFY_MODE_OPTIONAL。
-
tls_version:tls 协议版本。
推荐配置成 tls 1.2 或 tls 1.3,tls 1.2 以下的版本不安全,tls 1.3 版本 mbedtls 没有完整支持。
-
debug_level:日志等级。
推荐设置 QTF_TLS_DEBUG_LEVEL_NONE 关闭日志输出。排查问题时可以将日志打开 QTF_TLS_DEBUG_LEVEL_VERBOSE(注意会打印密钥和收发数据的明文内容)。
-
max_frag_len: 数据分片大小设置。
在客户端侧设置,用于协商数据分片大小,设置这个参数应该是出于对使用内存大小和带宽的考虑。
设置太小,可能会出现服务器证书接收不完整导致握手失败问题,但最大值也不能设置超过接收缓冲区的大小。
-
hanshake_timeout_ms:握手超时时间。
-
ca_cert:服务器的 ca 证书。
如果要求校验证书,则必须设置。客户端校验服务器是否合法,单向认证。
-
client_cert:客户端证书。
要求双向认证的时候必须设置,用于服务器校验客户端是否合法。同时还要设置 client_key。
-
psk :预定义共享密钥。
psk 不需要证书认证,减少握手数据交互流程,但需要指定 psk_id 身份标识和指定加密套件。
接口定义:
|
1 2 3 4 |
void *qtf_tls_connect(const char *host, uint16_t port, qtf_tls_conn_param_t *param); int qtf_tls_send(void *handle, const void *buf, uint32_t len, uint32_t timeout_ms); int qtf_tls_recv(void *handle, void *buf, uint32_t len, uint32_t timeout_ms); int qtf_tls_close(void *handle); |
接口实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 |
#include <stdio.h> #include <stdlib.h> #include <string.h> #include "qt_idf_tls.h" #include "dlg/dlg.h" #include "mbedtls/net_sockets.h" #include "mbedtls/ssl.h" #include "mbedtls/ctr_drbg.h" #include "mbedtls/debug.h" #include "mbedtls/platform.h" #include "mbedtls/timing.h" #include "mbedtls/entropy.h" #include "mbedtls/error.h" typedef struct { mbedtls_net_context socket_fd; mbedtls_entropy_context entropy; mbedtls_ctr_drbg_context ctr_drbg; mbedtls_ssl_context ssl; mbedtls_ssl_config ssl_conf; mbedtls_x509_crt ca_cert; mbedtls_x509_crt client_cert; mbedtls_pk_context private_key; }qtf_tls_handle_t; #if defined(MBEDTLS_DEBUG_C) static void _ssl_debug(void *ctx, int level, const char *file, int line, const char *str) { printf("[mbedTLS]:[%s]:[%d]: %s\r\n", (file), line, (str)); } #endif static int _mbedtls_tcp_connect(mbedtls_net_context *ctx, const char *host, uint16_t port) { int ret = 0; char port_str[6] = {0}; snprintf(port_str, sizeof(port_str), "%d", port); ret = mbedtls_net_connect(ctx, host, port_str, MBEDTLS_NET_PROTO_TCP); if(ret != 0) { dlg_error("mbedtls_net_connect connect failed returned 0x%04x errno: %d", ret < 0 ? -ret : ret, errno); return ret; } ret = mbedtls_net_set_block(ctx); if(ret != 0) { dlg_error("mbedtls_net_set_block failed returned 0x%04x errno: %d", ret < 0 ? -ret : ret, errno); return ret; } return 0; } static int _tls_net_init(qtf_tls_handle_t *handle, qtf_tls_conn_param_t *param) { int ret = -1; mbedtls_net_init(&(handle->socket_fd)); mbedtls_ssl_init(&(handle->ssl)); mbedtls_ssl_config_init(&(handle->ssl_conf)); mbedtls_ctr_drbg_init(&(handle->ctr_drbg)); mbedtls_entropy_init(&(handle->entropy)); #if defined(MBEDTLS_DEBUG_C) mbedtls_debug_set_threshold(param->debug_level); mbedtls_ssl_conf_dbg(&handle->ssl_conf, _ssl_debug, NULL); #endif #if defined(MBEDTLS_USE_PSA_CRYPTO) || defined(MBEDTLS_SSL_PROTO_TLS1_3) // tls 1.3 需要调用 psa_crypto_init ret = psa_crypto_init(); if (ret != PSA_SUCCESS) { dlg_error("psa_crypto_init failed"); goto error; } #endif ret = mbedtls_ssl_conf_max_frag_len(&(handle->ssl_conf), param->max_frag_len); if (ret != 0) { dlg_error("mbedtls_ssl_conf_max_frag_len failed"); goto error; } ret = mbedtls_ctr_drbg_seed(&(handle->ctr_drbg), mbedtls_entropy_func, &(handle->entropy), NULL, 0); if (ret != 0) { dlg_error("mbedtls_ctr_drbg_seed failed"); goto error; } // 证书认证方式 if(param->auth_mode == QTF_TLS_AUTH_MODE_CERT) { if(param->ca_cert && param->ca_cert_len) { mbedtls_x509_crt_init(&(handle->ca_cert)); ret = mbedtls_x509_crt_parse(&(handle->ca_cert), (const unsigned char *)param->ca_cert, param->ca_cert_len+1); if (ret != 0) { dlg_error("mbedtls_x509_crt_parse failed"); goto error; } } else { if(param->verify_mode != QTF_TLS_VERIFY_MODE_NONE) { dlg_error("invalid ca cert"); goto error; } dlg_info("verify mode is none"); } mbedtls_ssl_conf_ca_chain(&(handle->ssl_conf), &(handle->ca_cert), NULL); if (param->client_cert && param->client_cert_len && param->client_key && param->client_key_len) { // 双向认证 mbedtls_x509_crt_init(&(handle->client_cert)); mbedtls_pk_init(&(handle->private_key)); ret = mbedtls_x509_crt_parse(&(handle->client_cert), (const unsigned char *)param->client_cert, param->client_cert_len + 1); if (ret != 0) { dlg_error("mbedtls_x509_crt_parse failed"); goto error; } ret = mbedtls_pk_parse_key(&(handle->private_key), (const unsigned char *)param->client_key, param->client_key_len + 1, (const unsigned char *)param->client_key_passwd, param->client_key_passwd_len + 1, NULL, NULL); if (ret != 0) { dlg_error("mbedtls_pk_parse_key failed"); goto error; } ret = mbedtls_ssl_conf_own_cert(&(handle->ssl_conf), &(handle->client_cert), &(handle->private_key)); if (ret != 0) { dlg_error("mbedtls_ssl_conf_own_cert failed"); goto error; } } } // psk 认证 else if(param->auth_mode == QTF_TLS_AUTH_MODE_PSK) { if(param->psk && param->psk_len && param->psk_id) { ret = mbedtls_ssl_conf_psk(&(handle->ssl_conf), (const unsigned char *)param->psk, param->psk_len, (const unsigned char *)param->psk_id, strlen(param->psk_id)); if (ret != 0) { dlg_error("mbedtls_ssl_conf_psk failed"); goto error; } } else { dlg_error("invalid psk"); goto error; } } else { dlg_error("invalid auth mode"); goto error; } return ret; error: return ret; } static int __tls_net_deinit(qtf_tls_handle_t *handle) { mbedtls_net_free(&(handle->socket_fd)); mbedtls_ssl_free(&(handle->ssl)); mbedtls_ssl_config_free(&(handle->ssl_conf)); mbedtls_ctr_drbg_free(&(handle->ctr_drbg)); mbedtls_entropy_free(&(handle->entropy)); mbedtls_x509_crt_free(&(handle->ca_cert)); mbedtls_x509_crt_free(&(handle->client_cert)); mbedtls_pk_free(&(handle->private_key)); return 0; } void *qtf_tls_connect(const char *host, uint16_t port, qtf_tls_conn_param_t *param) { qtf_tls_handle_t *handle = NULL; int ret = 0; if(!host || !param) { dlg_error("invalid param"); goto error; } handle = (qtf_tls_handle_t *)malloc(sizeof(qtf_tls_handle_t)); if(!handle) { dlg_error("malloc failed"); goto error; } // 配置 tls 连接参数 ret = _tls_net_init(handle, param); if(ret != 0) { dlg_error("tls net init failed"); goto error; } dlg_info("Connecting to %s:%d...", host, port); // 建立 tcp 连接 ret = _mbedtls_tcp_connect(&(handle->socket_fd), host, port); if (ret != 0) { dlg_error("mbedtls_tcp_connect failed"); goto error; } // 设置 tls 客户端 mbedtls_ssl_config_defaults(&(handle->ssl_conf), MBEDTLS_SSL_IS_CLIENT, MBEDTLS_SSL_TRANSPORT_STREAM, MBEDTLS_SSL_PRESET_DEFAULT); mbedtls_ssl_conf_read_timeout(&(handle->ssl_conf), param->hanshake_timeout_ms); // 配置认证等级 mbedtls_ssl_conf_authmode(&(handle->ssl_conf), param->verify_mode); // 协议版本设置 if(param->tls_version == QTF_TLS_VERSION_TLS1_2) { mbedtls_ssl_conf_max_tls_version(&(handle->ssl_conf), MBEDTLS_SSL_VERSION_TLS1_2); mbedtls_ssl_conf_min_tls_version(&(handle->ssl_conf), MBEDTLS_SSL_VERSION_TLS1_2); } else if(param->tls_version == QTF_TLS_VERSION_TLS1_3) { mbedtls_ssl_conf_max_tls_version(&(handle->ssl_conf), MBEDTLS_SSL_VERSION_TLS1_3); mbedtls_ssl_conf_min_tls_version(&(handle->ssl_conf), MBEDTLS_SSL_VERSION_TLS1_3); } else { mbedtls_ssl_conf_max_tls_version(&(handle->ssl_conf), MBEDTLS_SSL_VERSION_TLS1_3); mbedtls_ssl_conf_min_tls_version(&(handle->ssl_conf), MBEDTLS_SSL_VERSION_TLS1_2); } mbedtls_ssl_conf_rng(&(handle->ssl_conf), mbedtls_ctr_drbg_random, &(handle->ctr_drbg)); // todo: config ciphersuites ret = mbedtls_ssl_setup(&(handle->ssl), &(handle->ssl_conf)); if (ret != 0) { dlg_error("mbedtls_ssl_setup failed"); goto error; } // 配置 tcp 收发函数,可自定义也可使用 mbedtls 的实现 mbedtls_ssl_set_bio(&(handle->ssl), &(handle->socket_fd), mbedtls_net_send, mbedtls_net_recv, mbedtls_net_recv_timeout); // 设置服务器域名,目的是配置 SNI (Server Name Indication) 扩展。 ret = mbedtls_ssl_set_hostname(&(handle->ssl), host); if (ret != 0) { dlg_error("mbedtls_ssl_set_hostname failed"); goto error; } // 执行握手流程 while ((ret = mbedtls_ssl_handshake(&(handle->ssl))) != 0) { if (ret != MBEDTLS_ERR_SSL_WANT_READ && ret != MBEDTLS_ERR_SSL_WANT_WRITE) { dlg_error("mbedtls_ssl_handshake failed 0x%04x", ret < 0 ? -ret : ret); goto error; } } // 证书校验结果 ret = mbedtls_ssl_get_verify_result(&(handle->ssl)); if (ret < 0) { dlg_error("mbedtls_ssl_get_verify_result 0x%04x", ret < 0 ? -ret : ret); goto error; } return handle; error: if(handle) { __tls_net_deinit(handle); free(handle); } return NULL; } int qtf_tls_send(void *handle, const void *buf, uint32_t len, uint32_t timeout_ms) { qtf_tls_handle_t *tls_handle = (qtf_tls_handle_t *)handle; int ret = 0; if(!handle || !buf || !len) { dlg_error("invalid param"); return -1; } // 发送数据 while ((ret = mbedtls_ssl_write(&(tls_handle->ssl), (const unsigned char *)buf, len)) <= 0) { if (ret != MBEDTLS_ERR_SSL_WANT_READ && ret != MBEDTLS_ERR_SSL_WANT_WRITE) { dlg_error("mbedtls_ssl_write failed 0x%04x", ret < 0 ? -ret : ret); return -1; } } return ret; } int qtf_tls_recv(void *handle, void *buf, uint32_t len, uint32_t timeout_ms) { qtf_tls_handle_t *tls_handle = (qtf_tls_handle_t *)handle; int ret = 0; if(!handle || !buf || !len) { dlg_error("invalid param"); return -1; } // 接收数据 while ((ret = mbedtls_ssl_read(&(tls_handle->ssl), (unsigned char *)buf, len)) <= 0) { if (ret != MBEDTLS_ERR_SSL_WANT_READ && ret != MBEDTLS_ERR_SSL_WANT_WRITE) { dlg_error("mbedtls_ssl_read failed 0x%04x", ret < 0 ? -ret : ret); return -1; } } return ret; } int qtf_tls_close(void *handle) { int ret = 0; qtf_tls_handle_t *tls_handle = (qtf_tls_handle_t *)handle; if (!handle) { dlg_error("invalid param"); return -1; } // 关闭连接,释放资源 do { ret = mbedtls_ssl_close_notify(&(tls_handle->ssl)); } while (ret == MBEDTLS_ERR_SSL_WANT_READ || ret == MBEDTLS_ERR_SSL_WANT_WRITE); __tls_net_deinit(tls_handle); free(tls_handle); return 0; } |
测试例子
测试代码,连接 https 测试服务器 httpbin.org,发送一个 get 请求,并接收服务器回复。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
void shell_tlstest_cmd(int argc, char *argv) { qtf_tls_conn_param_t tls_param = {0}; void *tls_handle = NULL; char recv_buf[1024] = {0}; int ret = 0; const char request[] = "GET /get?a=1 HTTP/1.1\r\n" "Host: httpbin.org\r\n" "Connection: close\r\n" "\r\n"; const char *test_ca_cert = { "-----BEGIN CERTIFICATE-----\r\n" "MIIDdTCCAl2gAwIBAgILBAAAAAABFUtaw5QwDQYJKoZIhvcNAQEFBQAwVzELMAkG\r\n" "A1UEBhMCQkUxGTAXBgNVBAoTEEdsb2JhbFNpZ24gbnYtc2ExEDAOBgNVBAsTB1Jv\r\n" "b3QgQ0ExGzAZBgNVBAMTEkdsb2JhbFNpZ24gUm9vdCBDQTAeFw05ODA5MDExMjAw\r\n" "MDBaFw0yODAxMjgxMjAwMDBaMFcxCzAJBgNVBAYTAkJFMRkwFwYDVQQKExBHbG9i\r\n" "YWxTaWduIG52LXNhMRAwDgYDVQQLEwdSb290IENBMRswGQYDVQQDExJHbG9iYWxT\r\n" "aWduIFJvb3QgQ0EwggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQDaDuaZ\r\n" "jc6j40+Kfvvxi4Mla+pIH/EqsLmVEQS98GPR4mdmzxzdzxtIK+6NiY6arymAZavp\r\n" "xy0Sy6scTHAHoT0KMM0VjU/43dSMUBUc71DuxC73/OlS8pF94G3VNTCOXkNz8kHp\r\n" "1Wrjsok6Vjk4bwY8iGlbKk3Fp1S4bInMm/k8yuX9ifUSPJJ4ltbcdG6TRGHRjcdG\r\n" "snUOhugZitVtbNV4FpWi6cgKOOvyJBNPc1STE4U6G7weNLWLBYy5d4ux2x8gkasJ\r\n" "U26Qzns3dLlwR5EiUWMWea6xrkEmCMgZK9FGqkjWZCrXgzT/LCrBbBlDSgeF59N8\r\n" "9iFo7+ryUp9/k5DPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNVHRMBAf8E\r\n" "BTADAQH/MB0GA1UdDgQWBBRge2YaRQ2XyolQL30EzTSo//z9SzANBgkqhkiG9w0B\r\n" "AQUFAAOCAQEA1nPnfE920I2/7LqivjTFKDK1fPxsnCwrvQmeU79rXqoRSLblCKOz\r\n" "yj1hTdNGCbM+w6DjY1Ub8rrvrTnhQ7k4o+YviiY776BQVvnGCv04zcQLcFGUl5gE\r\n" "38NflNUVyRRBnMRddWQVDf9VMOyGj/8N7yy5Y0b2qvzfvGn9LhJIZJrglfCm7ymP\r\n" "AbEVtQwdpf5pLGkkeB6zpxxxYu7KyJesF12KwvhHhm4qxFYxldBniYUr+WymXUad\r\n" "DKqC5JlR3XC321Y9YeRq4VzW9v493kHMB65jUr9TU/Qr6cf9tveCX4XSQRjbgbME\r\n" "HMUfpIBvFSDJ3gyICh3WZlXi/EjJKSZp4A==\r\n" "-----END CERTIFICATE-----"}; tls_param.auth_mode = QTF_TLS_AUTH_MODE_CERT; tls_param.verify_mode = QTF_TLS_VERIFY_MODE_OPTIONAL; tls_param.hanshake_timeout_ms = 10000; tls_param.ca_cert = test_ca_cert; tls_param.ca_cert_len = strlen(test_ca_cert); tls_param.client_cert = NULL; tls_param.client_cert_len = 0; tls_param.client_key = NULL; tls_param.client_key_len = 0; tls_param.client_key_passwd = NULL; tls_param.client_key_passwd_len = 0; tls_param.psk = NULL; tls_param.psk_len = 0; tls_param.psk_id = NULL; tls_param.debug_level = QTF_TLS_DEBUG_LEVEL_ERROR; tls_param.tls_version = QTF_TLS_VERSION_TLS1_2; tls_param.max_frag_len = QTF_TLS_MAX_FRAG_LEN_NO_USE; tls_handle = qtf_tls_connect("httpbin.org", 443, &tls_param); if(tls_handle) { shell_printf("tls connect success\r\n"); } else { shell_printf("tls connect failed\r\n"); return; } ret = qtf_tls_send(tls_handle, request, strlen(request), 1000); if(ret > 0) { shell_printf("tls send success\r\n"); } else { shell_printf("tls send failed\r\n"); qtf_tls_close(tls_handle); return; } ret = qtf_tls_recv(tls_handle, recv_buf, sizeof(recv_buf), 1000); if(ret > 0) { shell_printf("tls recv success\r\n"); shell_printf("recv:%s\r\n", recv_buf); } else { shell_printf("tls recv failed\r\n"); } qtf_tls_close(tls_handle); } |
测试日志:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
[qt_idf_tls.c:250 qtf_tls_connect] Connecting to httpbin.org:443... [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_client.c]:[258]: got supported group(001d) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_client.c]:[258]: got supported group(0017) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_client.c]:[258]: got supported group(0018) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_client.c]:[258]: got supported group(001e) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_client.c]:[258]: got supported group(0019) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_client.c]:[258]: got supported group(001a) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_client.c]:[258]: got supported group(001b) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_client.c]:[258]: got supported group(001c) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_tls.c]:[7384]: x509_verify_cert() returned -9984 (-0x2700) [mbedTLS]:[D:/workspace/QT/qt_idf/components/mbedtls/library/ssl_tls12_client.c]:[2762]: Perform PSA-based ECDH computation. tls connect success tls send success tls recv success recv:HTTP/1.1 200 OK Date: Sun, 02 Jul 2023 12:02:04 GMT Content-Type: application/json Content-Length: 220 Connection: close Server: gunicorn/19.9.0 Access-Control-Allow-Origin: * Access-Control-Allow-Credentials: true { "args": { "a": "1" }, "headers": { "Host": "httpbin.org", "X-Amzn-Trace-Id": "Root=1-64a1673a-5197ca4a2ff801443ac81bc6" }, "origin": "223.73.211.183", "url": "https://httpbin.org/get?a=1" } |


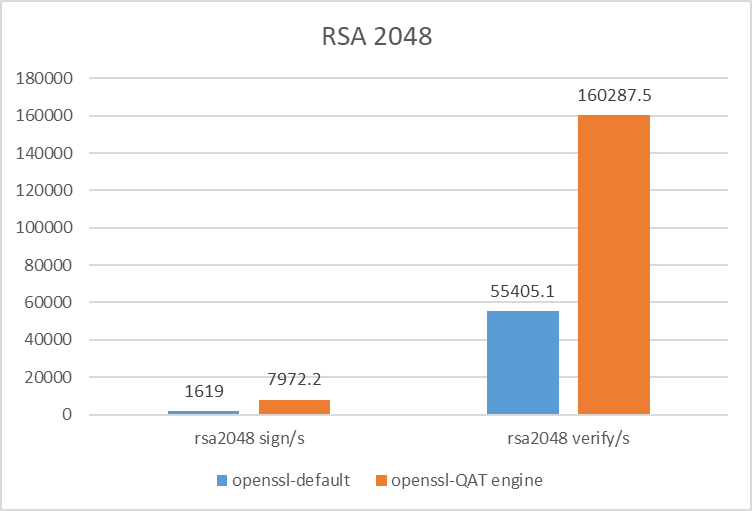
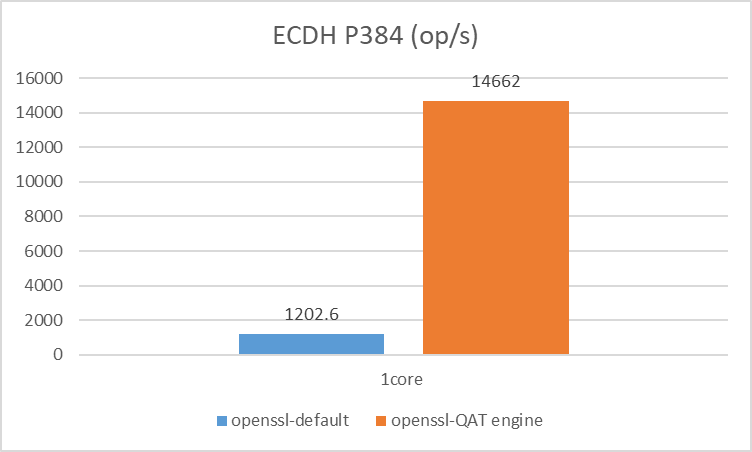
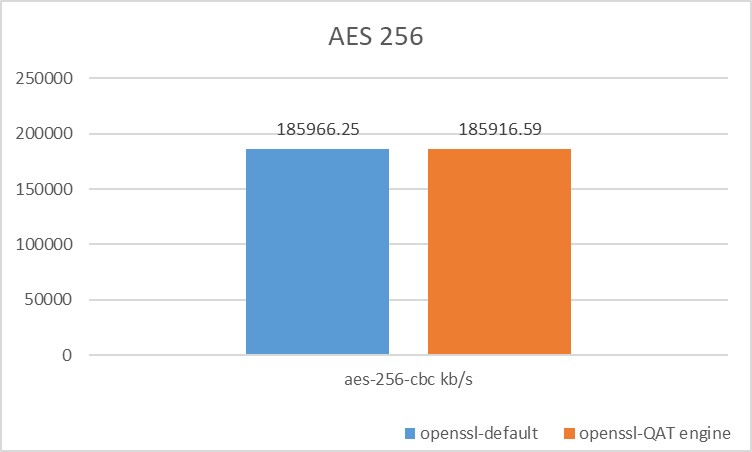


{kind=link}
{kind=link}