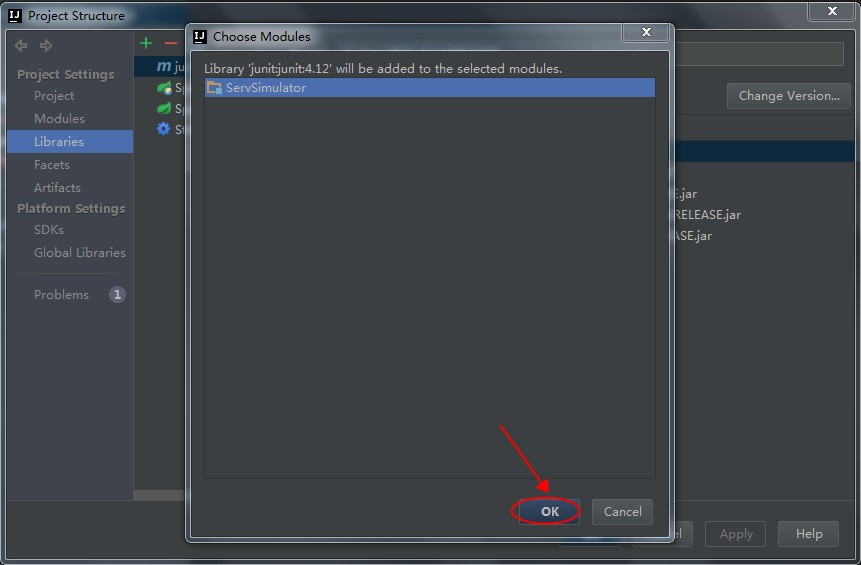
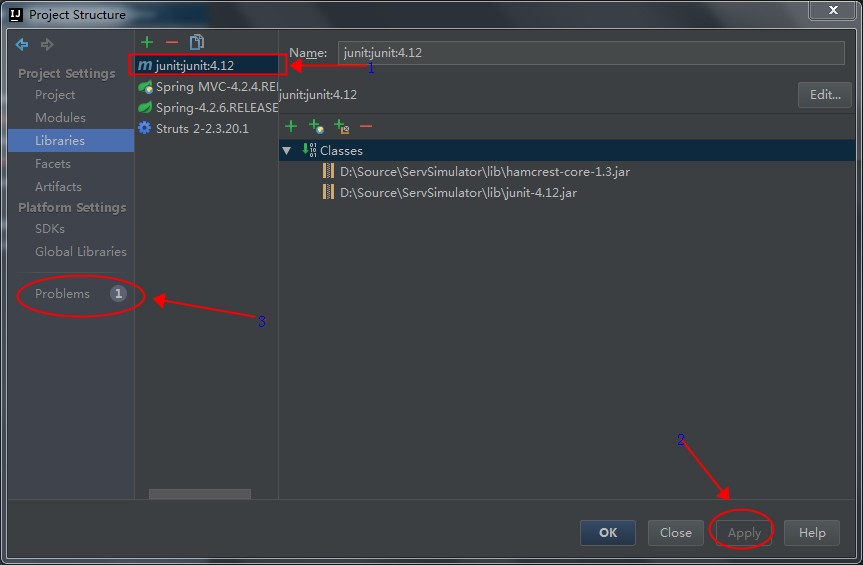
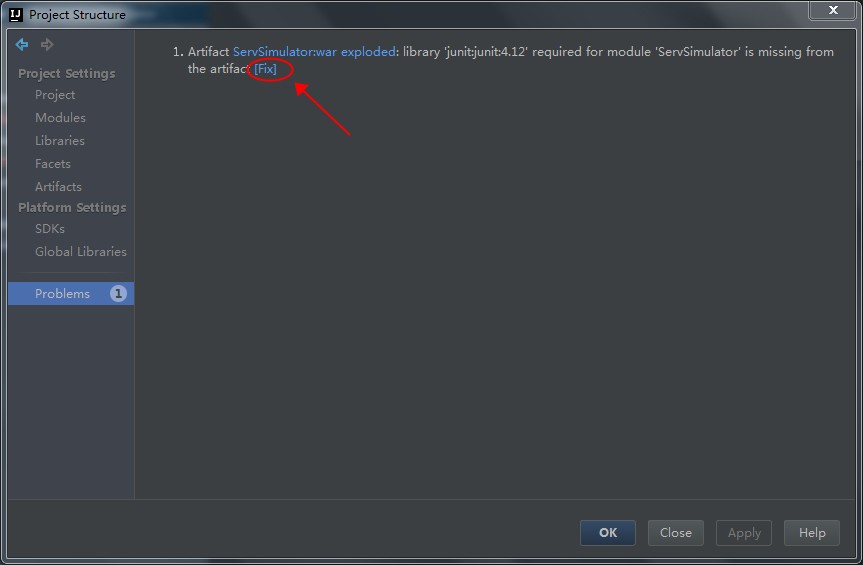
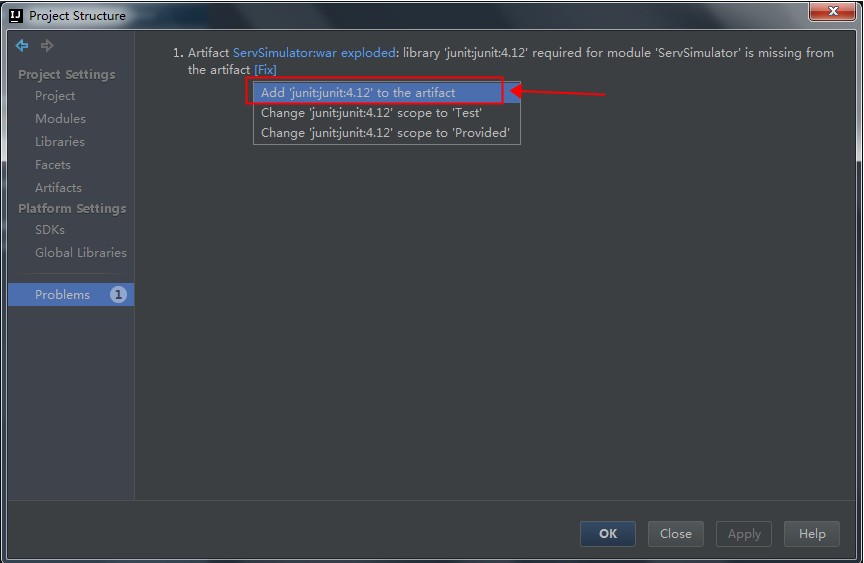
树莓派安装的系统是Linux raspberrypi 4.1.19+,以下的命令都是通过SSH在树莓派的系统上直接执行的。
1.编译树莓派内核
参照Ubuntu 16.04 (x64)树莓派B+(Raspberry Pi B+)源代码编译
2.安装git
|
1 |
pi@raspberrypi ~ $ sudo apt-get install git |
3.安装编译工具
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
pi@raspberrypi ~ $ sudo apt-get install build-essential pi@raspberrypi ~ $ sudo apt-get install autoconf pi@raspberrypi ~ $ sudo apt-get install bc pi@raspberrypi ~ $ sudo apt-get install gcc-4.8 g++-4.8 # 首先要让系统知道我们安装了多个版本的g++ # 命令最后的 20和50是优先级,如果使用auto选择模式,系统将默认使用优先级高的 pi@raspberrypi ~ $ sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.6 20 pi@raspberrypi ~ $ sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.8 50 pi@raspberrypi ~ $ sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.6 20 pi@raspberrypi ~ $ sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.8 50 pi@raspberrypi ~ $ sudo update-alternatives --config gcc pi@raspberrypi ~ $ sudo update-alternatives --config g++ |
我们在编译树莓派内核的时候,使用的gcc的版本是4.8.3版本(rpi-tools目录下),但是遗憾的是,树莓派自带的gcc的版本却是4.6.3,用这个版本的gcc编译出来的内核驱动可能会直接崩溃的,我们最好手工指定使用的gcc跟我们编译内核的时候的版本一致。换句话说,如果哪天我们编译内核的gcc再次升级,那么我们也需要手工在树莓派内部指定相同版本。
4.拷贝刚刚编译树莓派内核的源代码到当前的树莓派系统磁盘
从树莓派上拔下SD卡,插入到编译内核的Ubuntu 16.04 (x64)系统上,拷贝源代码
|
1 2 3 |
$ sudo cp -r rpi-linux /media/`whoami`/root/usr/src $ sudo chmod 777 -R /media/`whoami`/root/usr/src |
5.建立内核模块库目录的链接
重新插上SD卡,并且启动进入树莓派系统
|
1 |
pi@raspberrypi ~ $ sudo ln -s /usr/src/rpi-linux /lib/modules/$(uname -r)/build |
6.检测源代码目录下是否存在Module.symvers
|
1 2 3 |
pi@raspberrypi ~ $ cd /lib/modules/$(uname -r)/build pi@raspberrypi /lib/modules/4.4.12+/build $ ls -l | grep Module.symvers |
这个文件在我们编译内核之后应该是存在的,如果不存在,需要重新编译内核。
没有Module.symvers或用错了Module.symvers都可能会造成你加载模块时报Exec format error.
7.将当前正在使用的系统的内核配置作为编译内核时候的配置
|
1 2 3 4 5 6 7 |
pi@raspberrypi /lib/modules/4.4.12+/build $ sudo modprobe configs pi@raspberrypi /lib/modules/4.4.12+/build $ sudo touch .config pi@raspberrypi /lib/modules/4.4.12+/build $ sudo chmod 777 .config pi@raspberrypi /lib/modules/4.4.12+/build $ sudo gzip -dc /proc/config.gz > /lib/modules/$(uname -r)/build/.config |
8.生成编译内核所需要的文件
|
1 2 3 |
pi@raspberrypi ~ $ cd /lib/modules/$(uname -r)/build pi@raspberrypi /lib/modules/4.4.12+/build $ sudo make modules_prepare |
9.修改驱动程序的默认版本号与本系统相同
|
1 |
pi@raspberrypi ~ $ sudo vim /lib/modules/$(uname -r)/build/include/generated/utsrelease.h |
修改里面的内容为使用uname -r命令显示的内容,此系统版本显示为4.4.12+,修改后的内容如下:
|
1 |
#define UTS_RELEASE "4.4.12+" |
如果不进行上述的修改,会导致编译出来的内核文件在加载的时候提示disagrees about version of symbol module_layout,而无法成功加载驱动。
10.下载驱动程序源代码
|
1 2 3 |
pi@raspberrypi ~ $ cd ~ pi@raspberrypi ~ $ git clone https://github.com/robopeak/rpusbdisp.git |
11.切换到驱动程序的源代码目录
|
1 |
pi@raspberrypi ~ $ cd ~/rpusbdisp/drivers/linux-driver |
12.编译源代码
|
1 2 3 |
pi@raspberrypi ~/rpusbdisp/drivers/linux-driver $ make clean pi@raspberrypi ~/rpusbdisp/drivers/linux-driver $ make CFLAGS=-g |
编译完成后使用
|
1 |
pi@raspberrypi ~/rpusbdisp/drivers/linux-driver $ modinfo rp_usbdisplay.ko |
查看是不是与使用
|
1 |
pi@raspberrypi ~/rpusbdisp/drivers/linux-driver $ uname -r |
显示的完全相同,如果不完全相同,则需要继续进行上面的调整。
13.安装编译好的驱动
|
1 2 3 4 5 |
pi@raspberrypi ~/rpusbdisp/drivers/linux-driver $ sudo cp rp_usbdisplay.ko /lib/modules/`uname -r`/kernel/drivers/video/ pi@raspberrypi ~/rpusbdisp/drivers/linux-driver $ sudo depmod pi@raspberrypi ~/rpusbdisp/drivers/linux-driver $ sudo modprobe rp_usbdisplay |
执行完成后,会在/dev目录下面生成fb1这个文件。
|
1 2 |
$ ls /dev/fb* /dev/fb0 /dev/fb1 |
执行
|
1 |
$ cat /dev/fb0 > /dev/fb1 |
如果出现花屏,则驱动一切正常。
此处存在一个大坑。如果按照说明文档把驱动拷贝到
|
1 |
$ cp rp_usbdisplay.ko /lib/modules/`uname -r`/ |
或者直接运行,
|
1 |
pi@raspberrypi ~/rpusbdisp/drivers/linux-driver $ sudo ./run.sh |
则运行时候报错:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.140347] Internal error: Oops: 5 [#1] ARM Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.231738] Process modprobe (pid: 2850, stack limit = 0xd4cde188) Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.237909] Stack: (0xd4cdfe80 to 0xd4ce0000) Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.242269] fe80: bf1f8acc 00007fff bf1f8ac0 c007abe4 00000000 de593000 00000000 bf1f8acc Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.250441] fea0: 00000000 bf1f8acc bf1f8cb8 bf1f8c7c bf1f8010 bf1f8bb8 20000013 ffffffff Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.258611] fec0: 00000000 c056cda8 d4cdfeec 00000000 00000000 00000000 00000000 00000000 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.266782] fee0: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.274952] ff00: 00000000 00000000 de593000 000071eb 00000000 b6ede1eb de59a1eb d4cde000 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.283125] ff20: b6ec5948 00000000 d4cdffa4 d4cdff38 c007db58 c007bc20 00000000 de593000 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.291296] ff40: 000071eb de5973ac de597224 de5997c4 00002cb8 000035c8 00000000 00000000 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.299467] ff60: 00000000 00001e24 00000025 00000026 0000001a 0000001e 00000010 00000000 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.307637] ff80: 00000000 00040000 80458c38 00000080 c000f748 d4cde000 00000000 d4cdffa8 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.315808] ffa0: c000f580 c007da88 00000000 00040000 b6ed7000 000071eb b6ec5948 b6ed7000 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.323979] ffc0: 00000000 00040000 80458c38 00000080 80458d90 000071eb b6ec5948 00000000 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.332151] ffe0: 00000000 be9ba2fc b6ebcfb4 b6e27534 60000010 b6ed7000 1bffa861 1bffac61 Message from syslogd@raspberrypi at Aug 30 17:08:33 ... kernel:[ 93.356275] Code: e51bc088 e15c0007 e2477008 0a000009 (e5973014) Segmentation fault |
这个问题是由于驱动存放的目录不正确导致的。
14.将RoboPeakMini USB显示器驱动程序的内核模块设定为自动启动
|
1 |
pi@raspberrypi ~ $ sudo vim /etc/modules |
然后在文件尾部增加一行rp_usbdisplay。